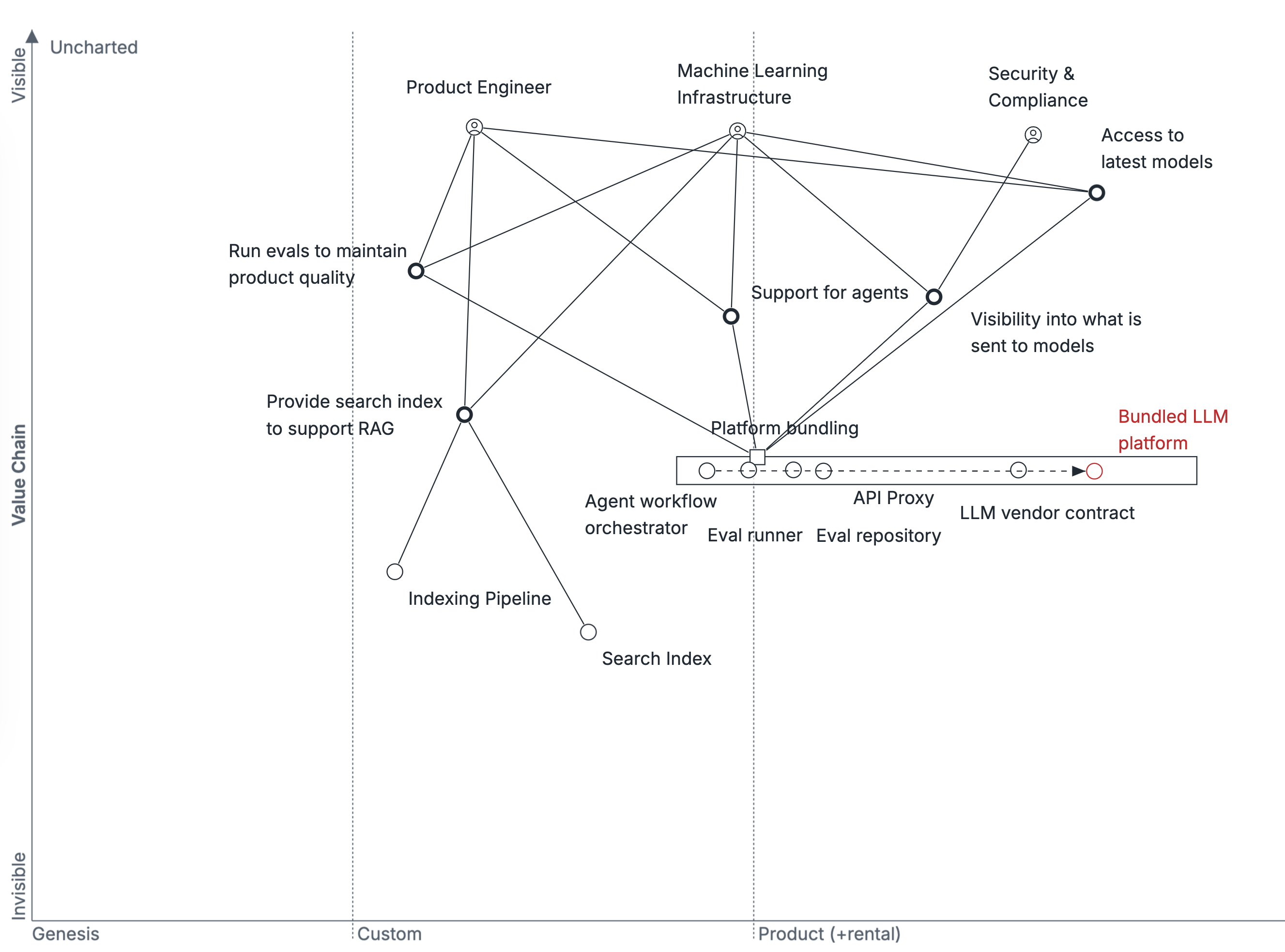
Wardley mapping the LLM ecosystem.
In How should you adopt LLMs?, we explore how a theoretical ride sharing company, Theoretical Ride Sharing, should adopt Large Language Models (LLMs). Part of that strategy’s diagnosis depends on understanding the expected evolution of the LLM ecosystem, which we’ve built a Wardley map to better explore.
This map of the LLM space focuses on how product companies should address the proliferation of model providers such as Anthropic, Google and OpenAI, as well as the proliferation of LLM product patterns like agentic workflows, Retrieval Augmented Generation (RAG), and running evals to maintain performance as models change.
This is a chapter from Crafting Engineering Strategy.
Reading this document
To quickly understand the analysis within this Wardley Map, read from top to bottom to understand this analysis. If you want to understand how this map was written, then you should read section by section from the bottom up, starting with Users, then Value Chains, and so on.
More detail on this structure in Refining strategy with Wardley Mapping.
How things work today
If Retrieval Augmented Generation (RAG) was the trending LLM pattern of 2023, and you could reasonably argue that agents–or agentic workflows–are the pattern of 2024, then it’s hard to guess what the patterns of tomorrow will be, but it’s likely that there are more, new patterns coming our way. LLMs are a proven platform today, and now are being applied widely to discover new patterns. It’s a safe bet that validating these patterns will continue to drive product companies to support additional infrastructure components (e.g. search indexes to support RAG).
This proliferation of patterns has created a significant cost for these product companies, a problem which market forces are likely to address as offerings evolve.
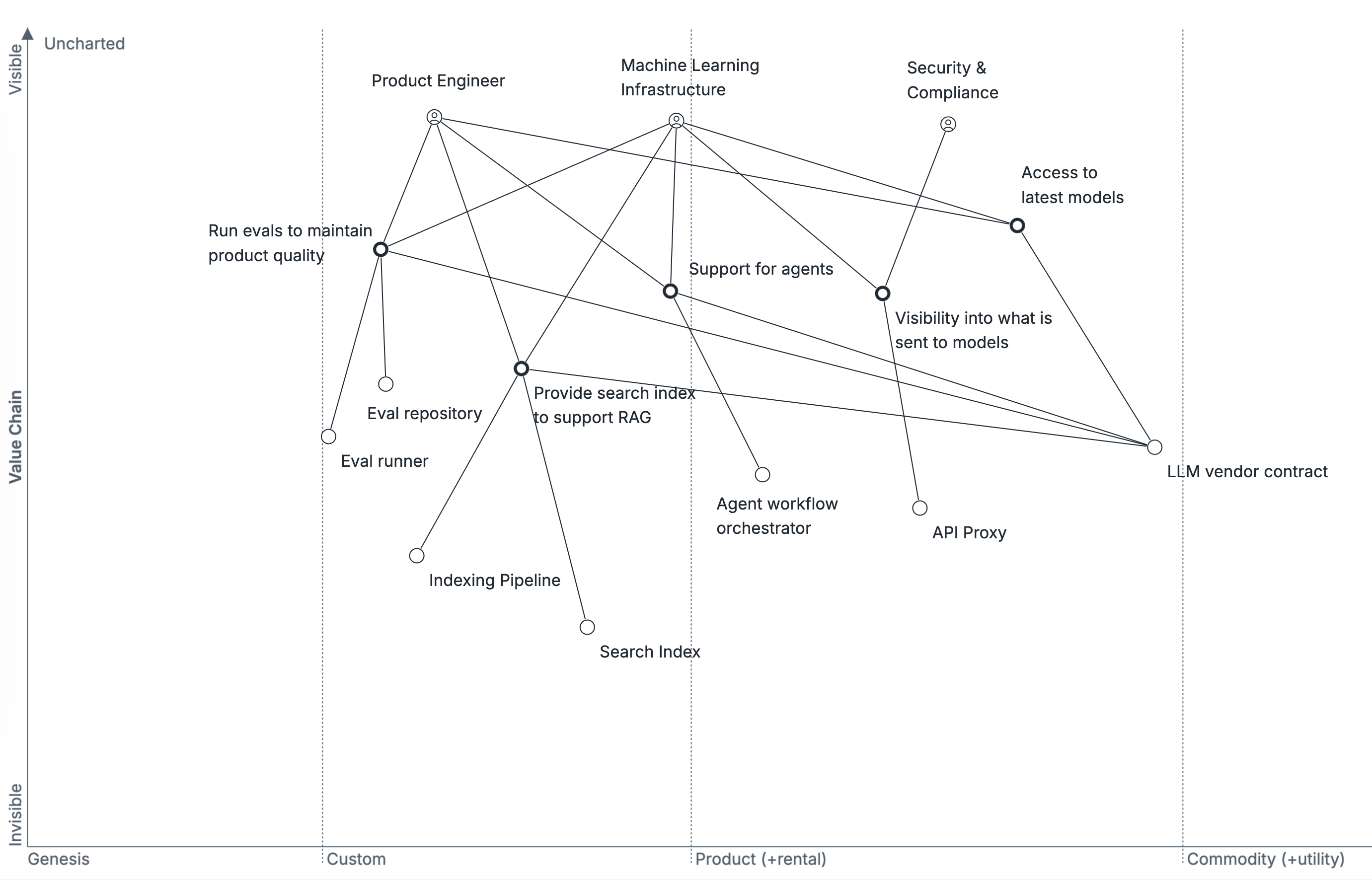
Transition to future state
Looking at the evolution of the LLM ecosystem, there are two questions that I believe will define the evolution of the space:
- Will LLM framework platforms for agents, RAG, and so on, remain bundled with model providers such as OpenAI and Anthropic? Or will they, instead, split with models and platforms being offered separately?
- Which elements of LLM frameworks will be productizable in the short-term? For example, running evals seems like a straightforward opportunity for bundling, as would providing some degree of agent support. Conversely, bundling RAG might seem straightforward but most production use cases would require real-time updates, incurring the full complexity of operating scaled search clusters.
Depending on the answers to those questions, you might draw a very different map. This map answers the first question by imagining that LLM platforms will decouple from model providers, while also allowing you to license with that platform for model access rather than needing to individually negotiate with each model provider. It answers the second question by imagining that most non-RAG functionality will move into a bundled platform provider. Given the richness of investment in the current space, it seems safe to believe that every plausible combination will exist to some degree until the ecosystem eventually stabilizes in one dominant configuration.

The key drivers of this configuration are that the LLM ecosystem is investing new patterns every year, and companies are spinning up haphazard internal solutions to validate those patterns, but ultimately few product companies are able to effectively fund these sorts of internal solutions in the long run.
If this map is correct, then it means eventual headwinds faced by both model providers (who are inherently limited to providing their own subset of models) as well as narrow LLM platform providers (who can only service a subset of LLM patterns). The likely best bet for a product company in this future is adopting the broadest LLM pattern platforms today, and to explicitly decouple pattern platform from model provider.
User & Value Chains
The LLM landscape is evolving rapidly, with some techniques getting introduced and reaching wide-spread adoption within a single calendar year. Sometimes those widely adopted techniques are actually being adopted, and other times it’s closer to “conference-talk driven development” where folks with broad platforms inflate the maturity of industry adoption.
The three primary users attempting to navigate that dynamism are:
- Product Engineers are looking for faster, easier solutions to deploying LLMs across the many, evolving parameters: new models, support for agents, solutions to offload the search dimensions of retrieval-augmented-generation (RAG), and so on.
- Machine Learning Infrastructure team is responsible for the effective usage of the mechanisms, and steering product developers towards effective adoption of these tools. They are also, in tandem with other infrastructure engineering teams, responsible for supporting common elements for LLM solutions, such as search indexes to power RAG implementations.
- Security and Compliance – how to ensure models are hosted safely and securely, and that we’re only sending approved information? how do we stay in alignment with rapidly evolving AI risks and requirements?
To keep the map focused on evolution rather than organizational dynamics, I’ve consolidated a number of teams in slightly artificial ways, and omitted a few teams that are certainly worth considering. Finance needs to understand the cost and usage of LLM usage. Security and Compliance are really different teams, with both overlapping and distinct requirements between them. Machine Learning Infrastructure could be split into two distinct teams with somewhat conflicting perspectives on who should own things like search infrastructure.
Depending on what you want to learn from the map, you might prefer to combine, split and introduce a different set of combinations than I’ve selected here.