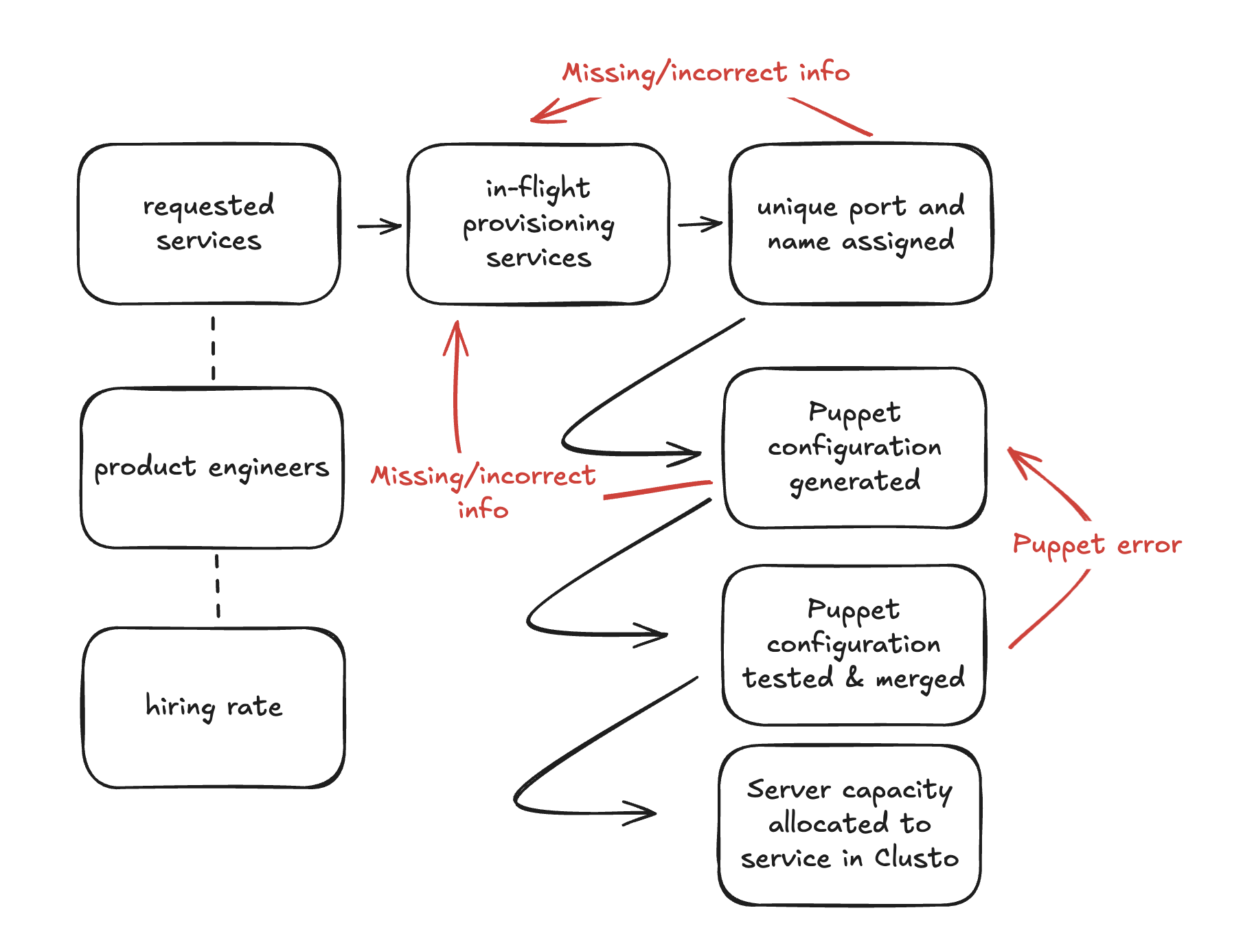
Service onboarding model for Uber (2014).
At the core of Uber’s service migration strategy (2014) is understanding the service onboarding process, and identifying the levers to speed up that process. Here we’ll develop a system model representing that onboarding process, and exercise the model to test a number of hypotheses about how to best speed up provisioning.
In this chapter, we’ll cover:
- Where the model of service onboarding suggested we focus on efforts
- Developing a system model using the lethain/systems package on Github. That model is available in the lethain/eng-strategy-models repository
- Exercising that model to learn from it
Let’s figure out what this model can teach us.
This is a chapter from Crafting Engineering Strategy.
Learnings
Even if we model this problem with a 100% success rate (e.g. no errors at all), the backlog of requested new services continues to increase over time. This clarifies that the problem to be solved is not the service provisioning team’s efficiency in running their current process, but rather that the fundamental approach is not working.
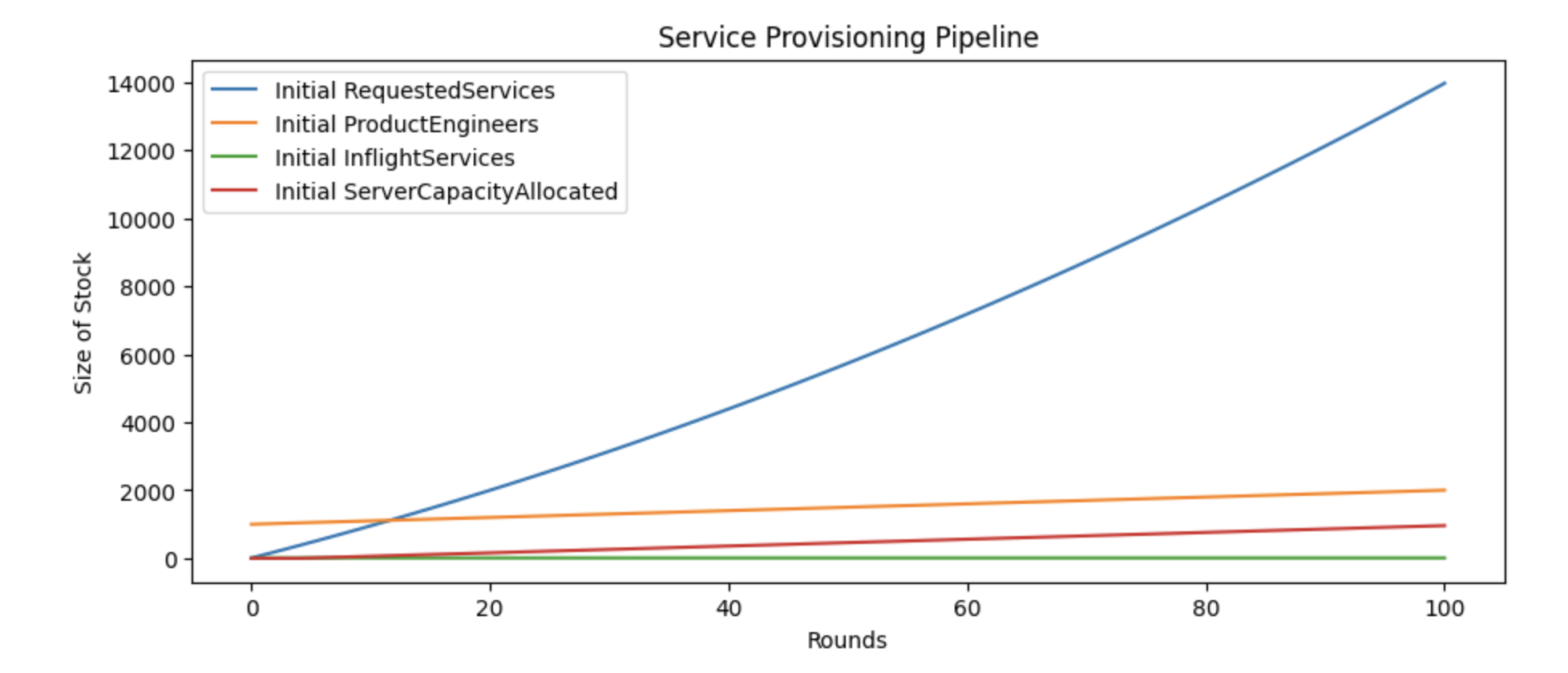
Although hiring is tempting as a solution, our model suggests it is not a particularly valuable approach in this scenario. Even increasing the Service Provisioning team’s staff allocated to manually provisioning services by 500% doesn’t solve the backlog of incoming requests.
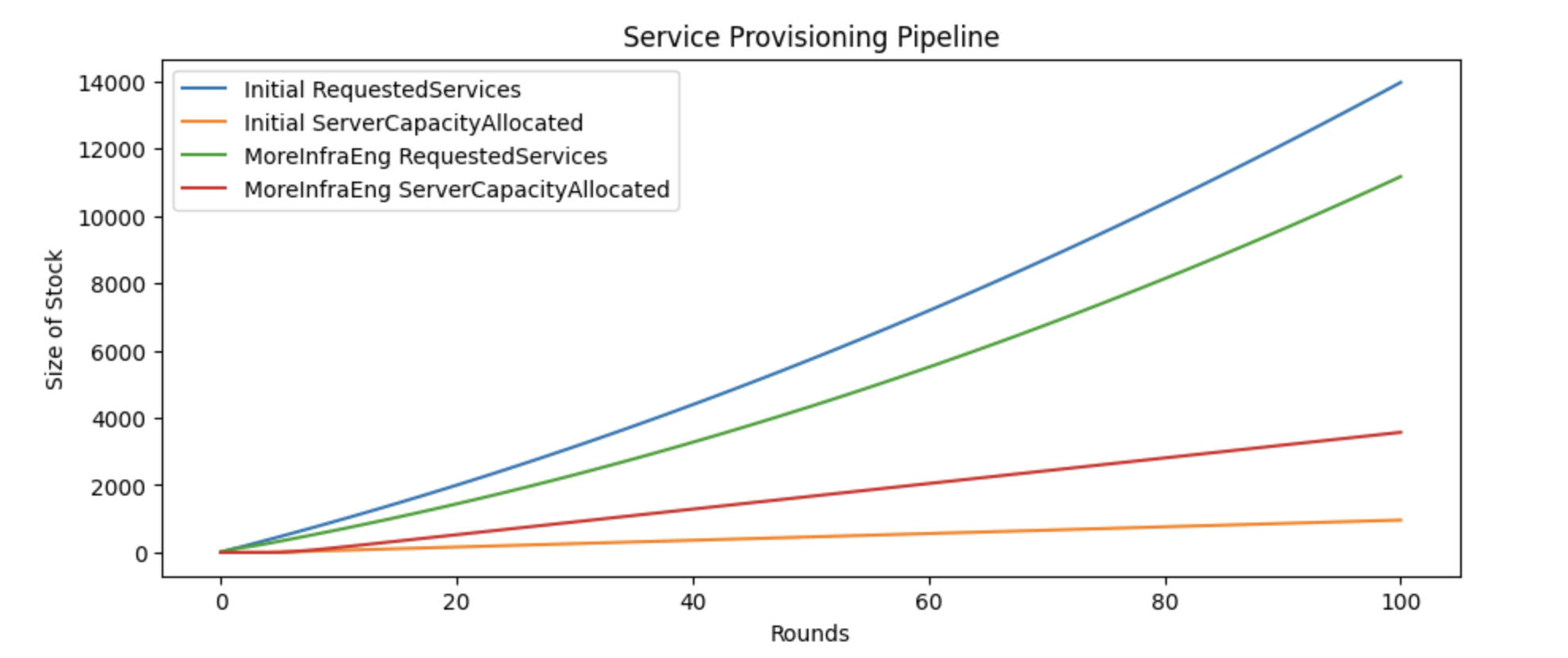
If reducing errors doesn’t solve the problem, and increased hiring for the team doesn’t solve the problem, then we have to find a way to eliminate manual service provisioning entirely. The most promising candidate is moving to a self-service provisioning model, which our model shows solves the backlog problem effectively.
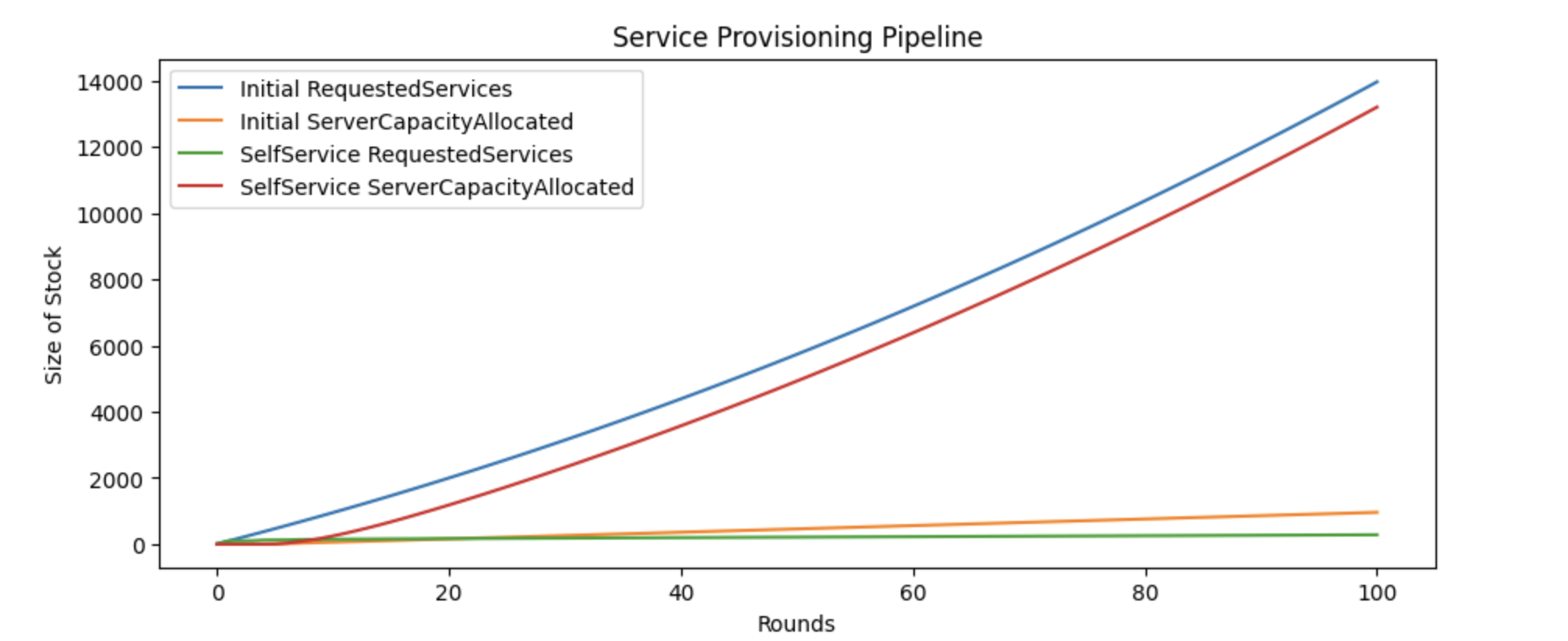
Refining our earlier statement, additional hiring may benefit the team if we are able to focus those hires on building self-service provisioning, and we’re able to ramp their productivity faster than the increase of incoming service provisioning requests.
Sketch
Our initial sketch of service provisioning is a simple pipeline starting with
requested services and moving step by step through to server capacity allocated.
Some of these steps are likely much slower than others, but it gives a sense of the
stages and where things might go wrong. It also gives us a sense of what we can measure
to evaluate if our approach to provisioning is working well.
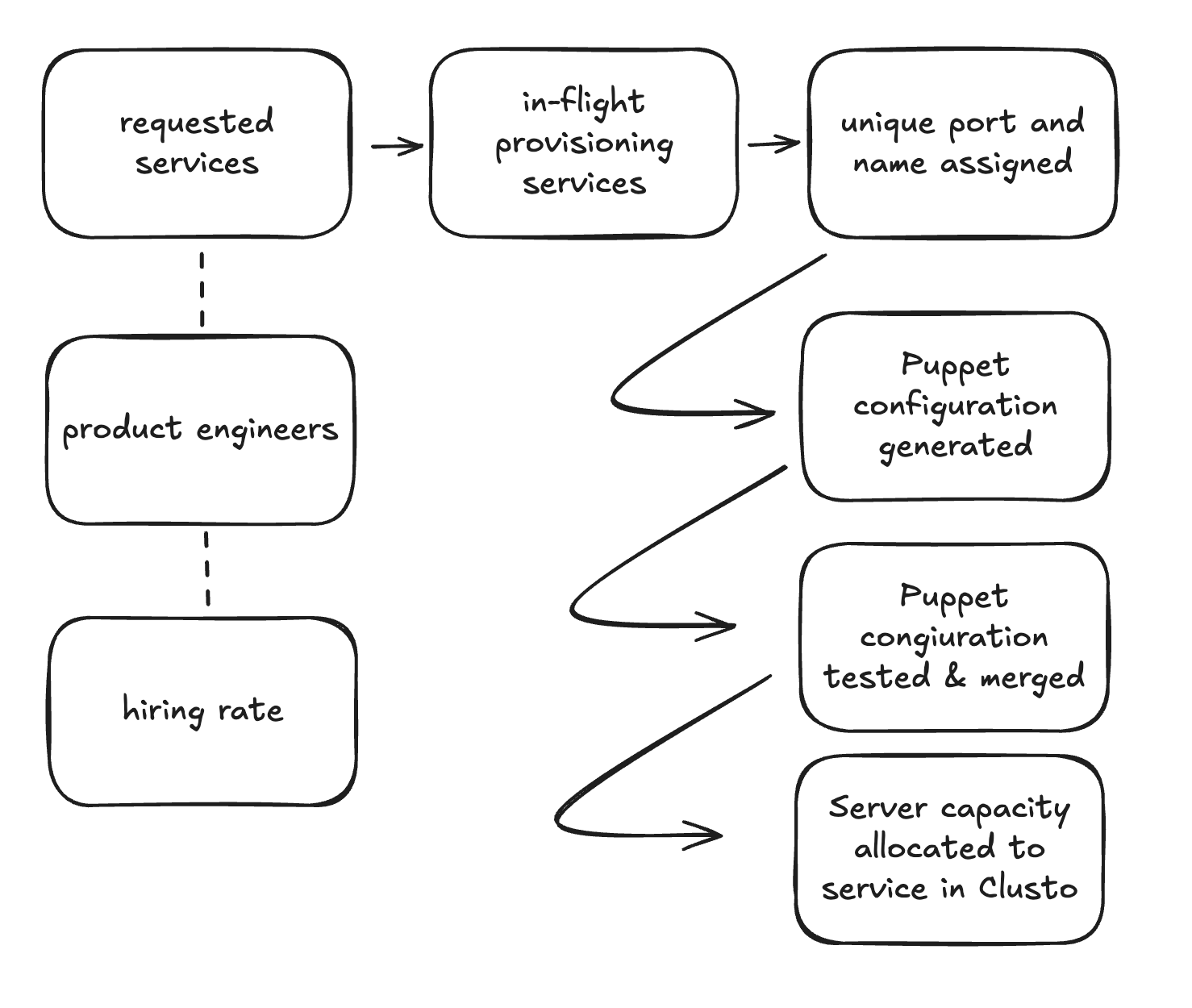
One element worth mentioning is the dotted lines from hiring rate to product engineers and
from product engineers to requested services. These are called links, which are stocks that
influence another stock, but don’t flow directly into them.
A purist would correctly note that links should connect to flows rather than stocks. That is true! However, as we’ll encounter when we convert this sketch into a model, there are actually several counterintuitive elements here that are necessary to model this system but make the sketch less readable. As a modeler, you’ll frequently encounter these sorts of tradeoffs, and you’ll have to decide what choices serve your needs best in the moment.
The biggest missing element the initial model is error flows, where things can sometimes go wrong in addition to sometimes going right. There are many ways things can go wrong, but we’re going to focus on modeling three error flows in particular:
Missing/incorrect informationoccurs twice in this model, and throws a provisioning request back into the initial provisioning phase where information is collected.When this occurs during port assignment, this is a relatively small trip backwards. However, when it occurs in Puppet configuration, this is a significantly larger step backwards.
Puppet erroroccurs in the second to final stock,Puppet configuration tested & merged. This sends requests back one step in the provisioning flow.
Updating our sketch to reflect these flows, we get a fairly complete and somewhat nuanced, view of the service provisioning flow.

Note that the combination of these two flows introduces the possibility of a service
being almost fully provisioned, but then traveling from Puppet testing back to Puppet configuration
due to Puppet error, and then backwards again to the initial step due to Missing/incorrect information.
This means nearly all provisioning progress can be lost if things go wrong.
There are more nuances we could introduce here, but there’s already enough complexity here for us to learn quite a bit from this model.
Reason
Studying our sketches, a few things stand out:
The hiring of product engineers is going to drive up service provisioning requests over time, but there’s no counterbalancing hiring of infrastructure engineers to work on service provisioning. This means there’s an implicit, but very real, deadline to scale this process independently of the size of the infrastructure engineering team.
Even without building the full model, it’s clear that we have to either stop hiring product engineers, turn this into a self-service solution, or find a new mechanism to discourage service provisioning.
The size of error rates are going to influence results a great deal, particularly those for
Missing/incorrect information. This is probably the most valuable place to start looking for efficiency improvements.Missing information errors are more expensive than the model implies, because they require coordination across teams to resolve. Conversely, Puppet testing errors are probably cheaper than the model implies, because they should be solvable within the same team and consequently benefit from a quick iteration loop.
Now we need to build a model that helps guide our inquiry into those questions.
Model
You can find the full implementation of this model on Github if you want to see the entirety rather than these emphasized snippets.
First, let’s get the success states working:
HiringRate(10)
ProductEngineers(1000)
[PotentialHires] > ProductEngineers @ HiringRate
[PotentialServices] > RequestedServices(10) @ ProductEngineers / 10
RequestedServices > InflightServices(0, 10) @ Leak(1.0)
InflightServices > PortNameAssigned @ Leak(1.0)
PortNameAssigned > PuppetGenerated @ Leak(1.0)
PuppetGenerated > PuppetConfigMerged @ Leak(1.0)
PuppetConfigMerged > ServerCapacityAllocated @ Leak(1.0)
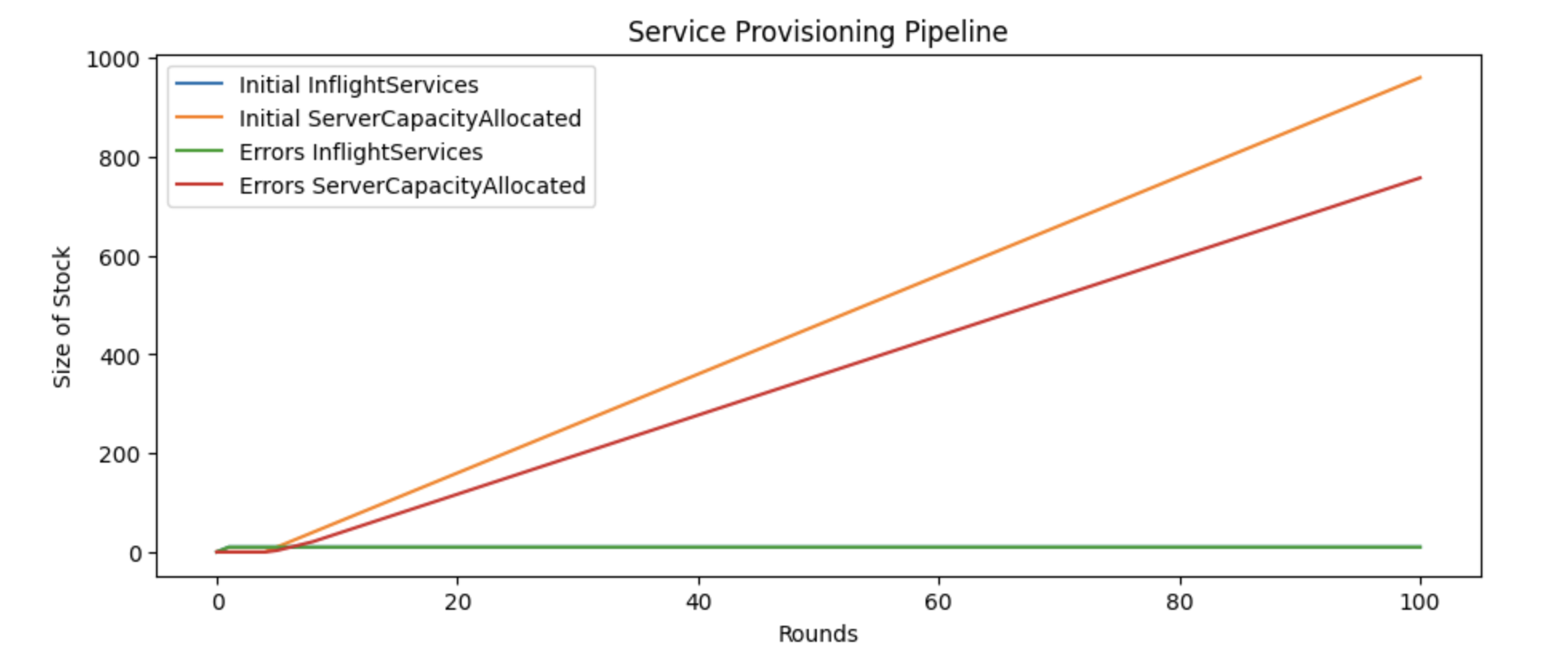
As we run this model, we can see that the number of requested services grows significantly over time. This makes sense, as we’re only able to provision a maximum of ten services per round.
However, it’s also the best case, because we’re not capturing the three error states:
- Unique port and name assignment can fail because of missing or incorrect information
- Puppet configuration can also fail due to missing or incorrect information.
- Puppet configurations can have errors in them, requiring rework.
Let’s update the model to include these failure modes, starting with unique port and name assignment. The error-free version looks like this:
InflightServices > PortNameAssigned @ Leak(1.0)
Now let’s add in an error rate, where 20% of requests are missing information and return to inflight services stock.
PortNameAssigned > PuppetGenerated @ Leak(0.8)
PortNameAssigned > RequestedServices @ Leak(0.2)
Then let’s do the same thing for puppet configuration errors:
# original version
PuppetGenerated > PuppetConfigMerged @ Leak(1.0)
# updated version with errors
PuppetGenerated > PuppetConfigMerged @ Leak(0.8)
PuppetGenerated > InflightServices @ Leak(0.2)
Finally, we’ll make a similar change to represent errors made in the Puppet templates themselves:
# original version
PuppetConfigMerged > ServerCapacityAllocated @ Leak(1.0)
# updated version with errors
PuppetConfigMerged > ServerCapacityAllocated @ Leak(0.8)
PuppetConfigMerged > PuppetGenerated @ Leak(0.2)
Even with relatively low error rates, we can see that the throughput of the system overall has been meaningfully impacted by introducing these errors.
Now that we have the foundation of the model built, it’s time to start exercising the model to understand the problem space a bit better.
Exercise
We already know the errors are impacting throughput, but let’s start by narrowing down which of errors matter most by increasing the error rate for each of them independently and comparing the impact.
To model this, we’ll create three new specifications, each of which increases one error from from 20% error rate to 50% error rate, and see how the overall throughput of the system is affected:
# test 1: port assignment errors increased
PortNameAssigned > PuppetGenerated @ Leak(0.5)
PortNameAssigned > RequestedServices @ Leak(0.5)
# test 2: puppet generated errors increased
PuppetGenerated > PuppetConfigMerged @ Leak(0.5)
PuppetGenerated > InflightServices @ Leak(0.5)
# test 3: puppet merged errors increased
PuppetConfigMerged > ServerCapacityAllocated @ Leak(0.5)
PuppetConfigMerged > PuppetGenerated @ Leak(0.5)
Comparing the impact of increasing the error rates from 20% to 50% in each of the three error loops, we can get a sense of the model’s sensitivity to each error.
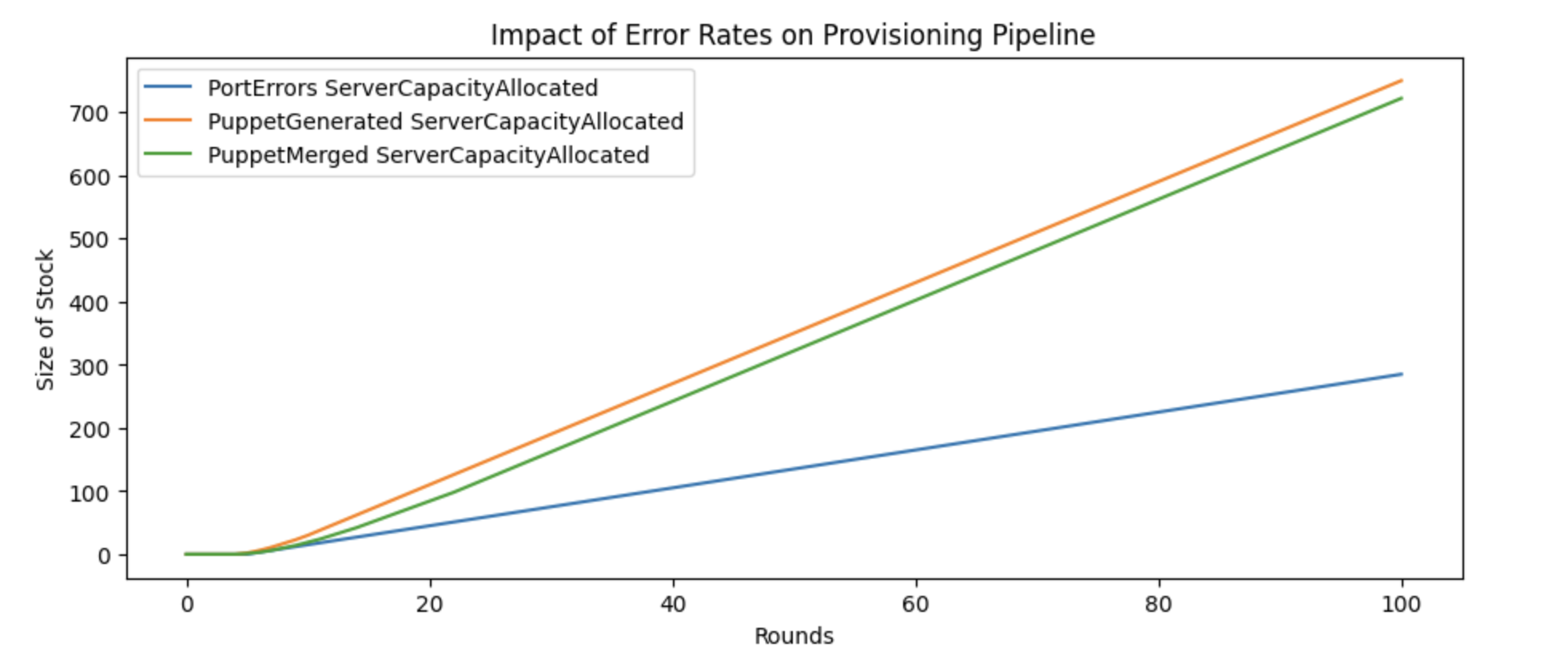
This chart captures why exercising is so impactful: we’d assumed during sketching that errors in puppet generation would matter the most because they caused a long trip backwards, but it turns out a very high error rate early in the process matters even more because there are still multiple other potential errors later on that compound on its increase.
Next we can get a sense of the impact of hiring more people onto the service
provisioning team to manually provision more services, which we can model by
increasing the maximum size of the inflight services stock from 10 to 50.
# initial model
RequestedServices > InflightServices(0, 10) @ Leak(1.0)
# with 5x capacity!
RequestedServices > InflightServices(0, 50) @ Leak(1.0)
Unfortunately, we can see that even increasing the team’s capacity by 500% doesn’t solve the backlog of requested services.
There’s some impact, but that much, and the backlog of requested services remains extremely high. We can conclude that more infrastructure hiring isn’t the solution we need, but let’s see if moving to self-service is a plausible solution.
We can simulate the impact of moving to self-service by removing the maximum size from inflight services entirely:
# initial model
RequestedServices > InflightServices(0, 10) @ Leak(1.0)
# simulating self-service
RequestedServices > InflightServices(0) @ Leak(1.0)
We can see this finally solves the backlog.
At this point, we’ve exercised the model a fair amount and have a good sense of what it wants to tell us. We know which errors matter the most to invest in early, and we also know that we need to make the move to a self-service platform sometime soon.