Uber's service migration strategy circa 2014.
In early 2014, I joined as an engineering manager for Uber’s Infrastructure team. We were responsible for a wide number of things, including provisioning new services. While the overall team I led grew significantly over time, the subset working on service provisioning never grew beyond four engineers.
Those four engineers successfully migrated 1,000+ services onto a new, future-proofed service platform. More importantly, they did it while absorbing the majority, although certainly not the entirety, of the migration workload onto that small team rather than spreading it across the 2,000+ engineers working at Uber at the time. Their strategy serves as an interesting case study of how a team can drive strategy, even without any executive sponsor, by focusing on solving a pressing user problem, and providing effective ergonomics while doing so.
Note that after this introductory section, the remainder of this strategy will be written from the perspective of 2014, when it was originally developed.
More than a decade after this strategy was implemented, we have an interesting perspective to evaluate its impact. It’s fair to say that it had some meaningful, negative consequences by allowing the widespread proliferation of new services within Uber. Those services contributed to a messy architecture that had to go through cycles of internal cleanup over the following years.
As the principal author of this strategy, I’ve learned a lot from meditating on the fact that this strategy was wildly successful, that I think Uber is better off for having followed it, and that it also meaningfully degraded Uber’s developer experience over time. There’s both good and bad here; with a wide enough lens, all evaluations get complicated.
This is a chapter from Crafting Engineering Strategy.
Reading this document
To apply this strategy, start at the top with Policy. To understand the thinking behind this strategy, read sections in reverse order, starting with Explore, then Diagnose and so on. Relative to the default structure, this document makes one tweak, folding the Operation section in with Policy.
More detail on this structure in Making a readable Engineering Strategy document.
Policy & Operation
We’ve adopted these guiding principles for extending Uber’s service platform:
Constrain manual provisioning allocation to maximize investment in self-service provisioning. The service provisioning team will maintain a fixed allocation of one full time engineer on manual service provisioning tasks. We will move the remaining engineers to work on automation to speed up future service provisioning. This will degrade manual provisioning in the short term, but the alternative is permanently degrading provisioning by the influx of new service requests from newly hired product engineers.
Self-service must be safely usable by a new hire without Uber context. It is possible today to make a Puppet or Clusto change while provisioning a new service that negatively impacts the production environment. This must not be true in any self-service solution.
Move to structured requests, and out of tickets. Missing or incorrect information in provisioning requests create significant delays in provisioning. Further, collecting this information is the first step of moving to a self-service process. As such, we can get paid twice by reducing errors in manual provisioning while also creating the interface for self-service workflows.
Prefer initializing new services with good defaults rather than requiring user input. Most new services are provisioned for new projects with strong timeline pressure but little certainty on their long-term requirements. These users cannot accurately predict their future needs, and expecting them to do so creates significant friction.
Instead, the provisioning framework should suggest good defaults, and make it easy to change the settings later when users have more clarity. The gate from development environment to production environment is a particularly effective one for ensuring settings are refreshed.
We are materializing those principles into this sequenced set of tasks:
Create an internal tool that coordinates service provisioning, replacing the process where teams request new services via Phabricator tickets. This new tool will maintain a schema of required fields that must be supplied, with the aim of eliminating the majority of back and forth between teams during service provisioning.
In addition to capturing necessary data, this will also serve as our interface for automating various steps in provisioning without requiring future changes in the workflow to request service provisioning.
Extend the internal tool to generate Puppet scaffolding for new services, reducing the potential for errors in two ways. First, the data supplied in the service provisioning request can be directly included in the rendered template. Second, this will eliminate most human tweaking of templates where typos can create issues.
Port allocation poses a particularly high-risk, as reusing a port can break routing to an existing production service. As such, this will be the first area we fully automate, with the provisioning service supplying the allocated port rather than requiring requesting teams to provide an already allocated port.
Doing this will require moving the port registry out of a Phabricator wiki page and into a database, which will allow us to guard access with a variety of checks.
Manual assignment of new services to servers often leads to new services being allocated to already heavily utilized servers. We will replace the manual assignment with an automated system, and do so with the intention of migrating to the Mesos/Aurora cluster once it is available for production workloads.
Each week, we’ll review the size of the service provisioning queue, along with the service provisioning time to assess whether the strategy is working or needs to be revised.
Prolonged strategy testing
Although I didn’t have a name for this practice in 2014 when we created and implemented this strategy, the preceding section captures an important reality of team-led bottom-up strategy: when you don’t have authority to mandate compliance, you have to get the details right. The best way to do that is a prolonged strategy testing phase. Indeed, because compliance is rooted in effectiveness, my experience is that non-executive strategy development can never stop refining their approach.
Refine
In order to refine our diagnosis, we’ve created a systems model for service onboarding. This will allow us to simulate a variety of different approaches to our problem, and determine which approach, or combination of approaches, will be most effective.
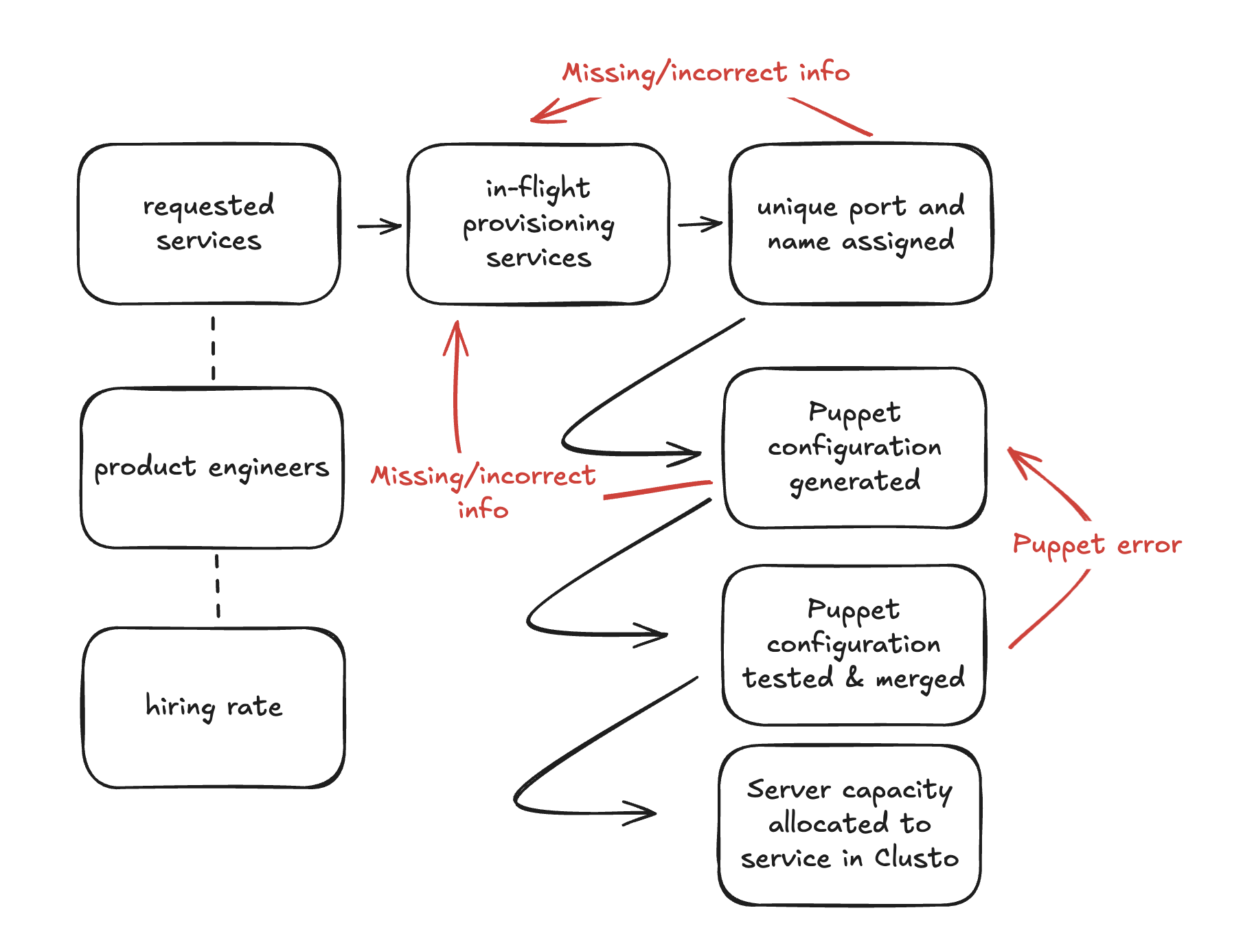
As we exercised the model, it became clear that:
- we are increasingly falling behind,
- hiring onto the service provisioning team is not a viable solution, and
- moving to a self-service approach is our only option.
While the model writeup justifies each of those statements in more detail,
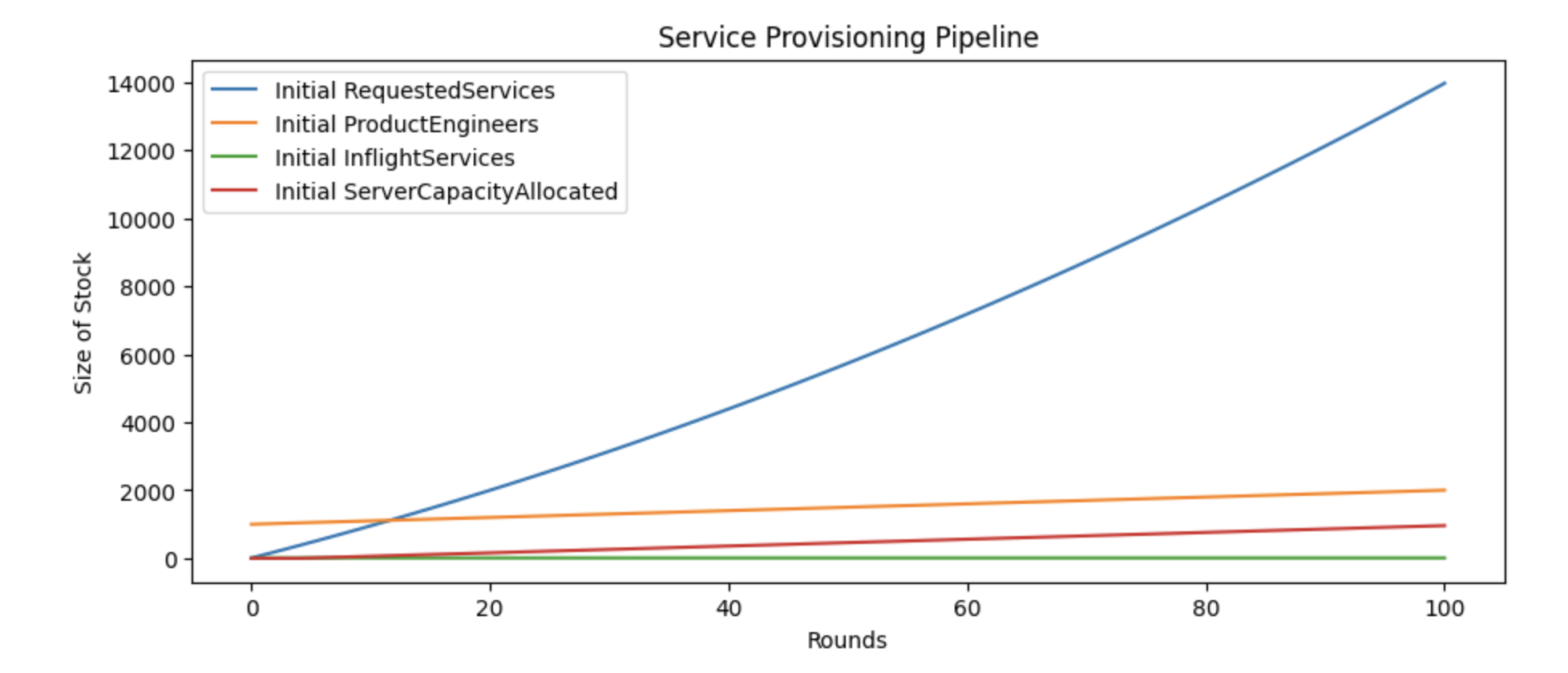
we’ll include two charts here. The first chart shows the status quo,
where new service provisioning requests, labeled as Initial RequestedServices, quickly accumulate into a backlog.
Second, we have a chart comparing the outcomes between the current status quo and a self-service approach.
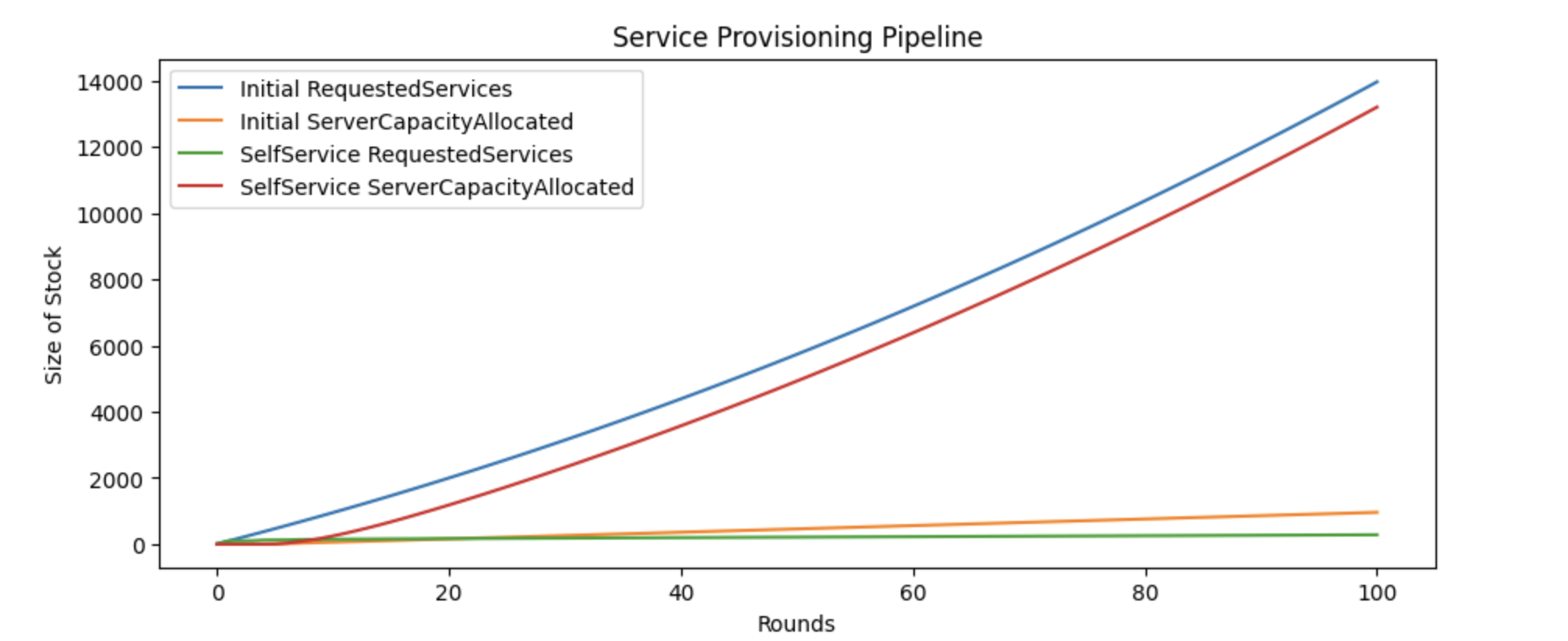
In that chart, you can see that the service provisioning backlog in the self-service model remains steady,
as represented by the SelfService RequestedServices line. Of the various attempts to find a solution,
none of the others showed promise, including eliminating all errors in provisioning and increasing the team’s
capacity by 500%.
Diagnose
We’ve diagnosed the current state of service provisioning at Uber as:
Many product engineering teams are aiming to leave the centralized monolith, which is generating two to three service provisioning requests each week. We expect this rate to increase roughly linearly with the size of the product engineering organization.
Even if we disagree with this shift to additional services, there’s no team responsible for maintaining the extensibility of the monolith, and working in the monolith is the number one source of developer frustration, so we don’t have a practical counter proposal to offer engineers other than provisioning a new service.
The engineering organization is doubling every six months. Consequently, a year from now, we expect eight to twelve service provisioning requests every week.
Within infrastructure engineering, there is a team of four engineers responsible for service provisioning today. While our organization is growing at a similar rate as product engineering, none of that additional headcount is being allocated directly to the team working on service provisioning. We do not anticipate this changing.
Some additional headcount is being allocated to Service Reliability Engineers (SREs) who can take on the most nuanced, complicated service provisioning work. However, their bandwidth is already heavily constrained across many tasks, so relying on SREs is an insufficient solution.
The queue for service provisioning is already increasing in size as things are today. Barring some change, many services will not be provisioned in a timely fashion.
Today, provisioning a new service takes about a week, with numerous round trips between the requesting team and the provisioning team. Missing and incorrect information between teams is the largest source of delay in provisioning services.
If the provisioning team has all the necessary information and it’s accurate, then a new service can be provisioned in about three to four hours of work across configuration in Puppet, metadata in Clusto, allocating ports, assigning the service to servers, and so on.
There are few safeguards on port allocation, server assignment and so on. It is easy to inadvertently cause a production outage during service provisioning unless done with attention to detail.
Given our rate of hiring, training the engineering organization to use this unsafe toolchain is an impractical solution: even if we train the entire organization perfectly today, there will be just as many untrained individuals in six months. Further, product engineering leadership has no interest in their team being diverted to service provisioning training.
It’s widely agreed across the infrastructure engineering team that essentially every component of service provisioning should be replaced as soon as possible, but there is no concrete plan to replace any of the core components. Further, there is no team accountable for replacing these components, which means the service provisioning team will either need to work around the current tooling or replace that tooling ourselves.
It’s urgent to unblock development of new services, but moving those new services to production is rarely urgent, and occurs after a long internal development period. Evidence of this is that requests to provision a new service generally come with significant urgency and internal escalations to management. After the service is provisioned for development, there are relatively few urgent escalations other than one-off requests for increased production capacity during incidents.
Another team within infrastructure is actively exploring adoption of Mesos and Aurora, but there’s no concrete timeline for when this might be available for our usage. Until they commit to supporting our workloads, we’ll need to find an alternative solution.
Explore
Uber’s server and service infrastructure today is composed of a handful of pieces. First, we run servers on-prem within a handful of colocations. Second, we describe each server in Puppet manifests to support repeatable provisioning of servers. Finally, we manage fleet and server metadata in a tool named Clusto, originally created by Digg, which allows us to populate Puppet manifests with server and cluster appropriate metadata during provisioning. In general, we agree that our current infrastructure is nearing its end of lifespan, but it’s less obvious what the appropriate replacements are for each piece.
There’s significant internal opposition to running in the cloud, up to and including our CEO, so we don’t believe that will change in the foreseeable future. We do however believe there’s opportunity to change our service definitions from Puppet to something along the lines of Docker, and to change our metadata mechanism towards a more purpose-built solution like Mesos/Aurora or Kubernetes.
As a starting point, we find it valuable to read Large-scale cluster management at Google with Borg which informed some elements of the approach to Kubernetes, and Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center which describes the Mesos/Aurora approach.
If you’re wondering why there’s no mention of Borg, Omega, and Kubernetes, it’s because it wasn’t published until 2016, a year after this strategy was developed.
Within Uber, we have a number of ex-Twitter engineers who can speak with confidence to their experience operating with Mesos/Aurora at Twitter. We have been unable to find anyone to speak with that has production Kubernetes experience operating a comparably large fleet of 10,000+ servers, although presumably someone is operating–or close to operating–Kubernetes at that scale.
Our general belief of the evolution of the ecosystem at the time is described in this Wardley mapping exercise on service orchestration (2014).
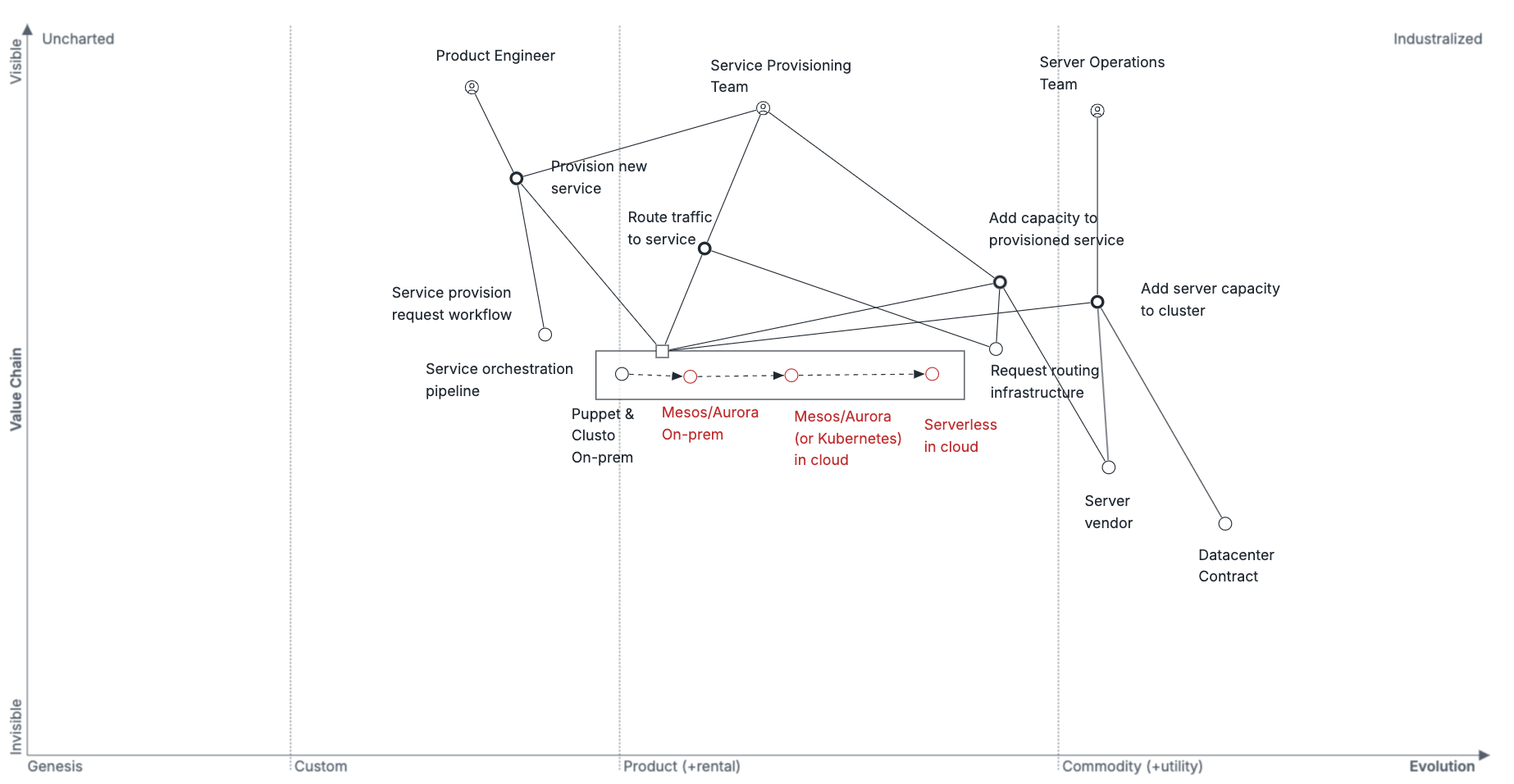
One of the unknowns today is how the evolution of Mesos/Aurora and Kubernetes will look in the future. Kubernetes seems promising with Google’s backing, but there are few if any meaningful production deployments today. Mesos/Aurora has more community support and more production deployments, but the absolute number of deployments remains quite small, and there is no large-scale industry backer outside of Twitter.
Even further out, there’s considerable excitement around “serverless” frameworks, which seem like a likely future evolution, but canvassing the industry and our networks we’ve been unable to find enough real-world usage to make an active push towards this destination today.
Wardley mapping is introduced as one of the techniques for strategy refinement, but it can also be a useful technique for exploring an dynamic ecosystem like service orchestration in 2014.
Assembling each strategy requires exercising judgment on how to compile the pieces together most usefully, and in this case I found that the map fits most naturally with the rest of exploration rather than in the more operationally-focused refinement section.