Trying out Google Container Engine
Reading the news, sometimes it feels like the key challenge facing startup CTOs is whether they pursue their service orchestration strategy or their autonomous vehicle strategy first. That said, I do believe that any technology company with more than a handful of engineers should indeed have an orchestration strategy, and to that end I’ve been spending time lately getting more familiar with Kubernetes and Google Container Engine (GKE) in particular.
The specific question I had in mind was whether I, personally, could get the level of automation, integration and flexibility I get at work–where I’m benefitting from significant investment into AWS AutoScaling Groups tooling, Jenkins integrations and an entire ecosystem of development tooling–and get it for “almost free”, without creating too much maintenance overhead for me to maintain.
To answer the question, I ported this blog to Kubernetes and GKE this weekend. At this point, it’s entirely served from GKE, and the AWS infrastructure has been spun down. (I’ll migrate systemsandpapers.com in the next week or two.)
(This endeavor is, slightly perverse, having recently moved to AWS.)
The steps I took were:
- Create a GKE hosted Kubernetes cluster, using three
n1-standard-1instances (each has 1.8 GB RAM). - Write a
Dockerfile, initially a transliteration of my existing Packer configuration which ran Nginx and the Go binary in the same VM. (Previously I had been baking AMIs.) - Sync my blog’s shoddy codebase, named
daedalus, from Github to Google Source Repositories, on the reasonable but unvalidated assumption that it’ll reduce build latencies to have it locally. - Create a build trigger in Container Builder to automatically
build Daedalus’
Dockerfileeach time I push to themasterbranch, and upload the resulting image into Container Registry, where it can be used by GKE. (I had a short detour into tagging container images with branch instead of tag, and it became clear that Kubernetes does not care for that approach, plus it breaks rollbacks.) - Get this approach working fully, including creating an ingress
resource with an HTTP(S) Google Load Balancer routing traffic to
daedalus. - It was at this point that things detoured slightly, as GLBs don’t provide automatic SSL certificate management capabilities similar to AWS ALBs, and it became clear that I would need to manage my own certificates.
- Let’s Encrypt is the obvious solution, and it seemed like
kube-lego was the most common integration,
so I set that up. It did work, but the specific behavior I want ended up
being harder to model: I want all non SSL traffic to get passed through, and all SSL
traffic to get terminated and passed through.
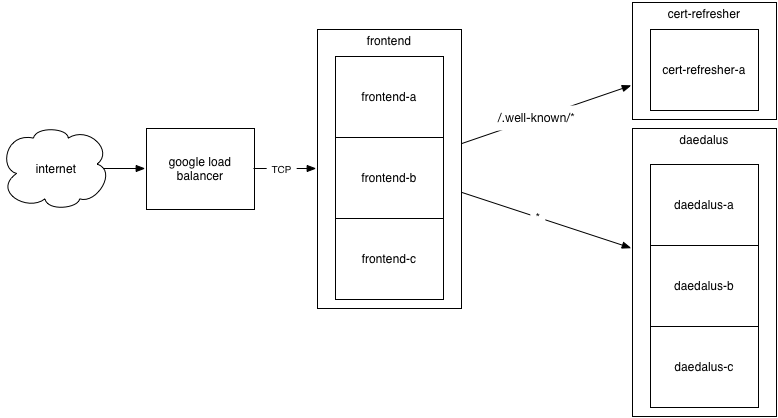
kube-legowanted specific routing rules for every domain and protocol (sort of necessary following from its approach to capturing the/.well-known/*path as required for answering Let’s Encrypt’s domain ownership challenges), and it claimed the route for unmatched traffic, directing it to a default Nginx config as opposed to letting me point it to mydaedalusnodes. This didn’t work well given the number of domains I wanted to handle (mostly just redirecting them tolethain.com, but enough that having a rule per domain was going to exceed my understanding of GLB’s restrictions), so I was back at the drawing board. - After some thought, I decided the best solution was to split out my Nginx and SSL termination
work into its own
deployment, such that I have two:frontendthat hosts Nginx and does SSL termination, anddaedaluswhich only runs the Go binary. It took a bit of configuration, but I was able to get this working, with a loadbalancer type service that directed TCP traffic to myfrontenddeployment, which in turn reverse-proxied to thedaedalusdeployment’sClusterIP. I updated the Nginx configurations to serve the Let’s Encrypt challenge tokens directly, and was able to pass the challenges. (I wanted to get a new cert tolethain.combefore switching DNS, so I actually ended up hacking my AWS’ instances’ Nginx configs to reverse proxy to my GCP load balancer for the challenge files, although in later readings I believe a 301 redirect would have worked just as well and been a bit less annoying.) - This was working pretty well, with the caveat that I only had a single
frontendpod, a necessary simplification becausecertbotwas writing local files and if we had multiple pods then some wouldn’t have the file to respond to the challenge accurately. After some reading, the simplest solution was to create acert-refreshdeployment, which I run with a single instance, and then have thefrontendpods reverse-proxy/.well-known/*back to that instance. For the things that really matter, e.g. serving traffic, there is high availability; cert renewal is technically no longer highly available, but the requirements are that it runs a refresh script once a day, so it can fulfill its needs even with extraordinarily poor uptime. - Victory!
This was quite a bit of debugging and hacking around to get working, but in the end it culminated in six yaml files (three deployments, three services) and three Dockerfiles, such that I could recreate the entire environment in a couple of minutes (ok, let’s call it thirty) if I had to.
More interestingly, it’s by far the most mature, convenient environment I’ve ever had for my
personal infrastructure. The entire pipeline after pushing to Git to having the container uploaded
is automated, and my deployment at this point is simply updating a deployment.yaml to point to the
new container’s tag, and Kubernetes does an incremental rollout of the new version, while respecting healthchecks
and pausing the rollout if healthchecks fail.
I can even rollback via the command line, which is a novel new idea for my personal infrastructure.
Events are sent to Google PubSub during container builds,
so it’s my guess that I’ll be able to add wiring there to have a complete continuous integration
pipeline with another hour or two of hacking around. I think, excitingly, that’s not just true for my personal applications like daedalus,
but also for the supporting infrastructure such as the frontend nodes. If I make invalid Nginx
configurations, I’ll no longer break my websites! (I’ve worked at real companies that couldn’t
make that same claim!)
Overall, I’ve been extremely impressed, and will move the remainder of my infrastructure over the
next week or two, giving me a slightly more complex environment to manage. Kubernetes was quite fun to
get more comfortable with, and the Google Cloud is mostly excellent, although it still hasn’t shaken
the feel that while its ideas may be simpler than AWS’, its execution is still rougher around the
edges (for example, the experience of getting gsutil working is meaningfully more confusing than awscli).