Using Cloud Firestore to power a Slack app.
Continuing from Make Slack app respond to reacji, it’s time to actually store and retrieve real data instead of relying on stubbed data. We’ll be building on Google Cloud Firestore, which is a NoSQL database offered on GCP.
By the end of this post our /reflect commands and :ididit: reacji will get recorded properly,
and each call to /recall and visit to the App Home view will return real
data as well.
post starts at commit 08eb and ends at commit 4584
Slack app in Python series
- Creating a Slack App in Python on GCP
- Adding App Home to Slack app in Python
- Make Slack app respond to reacji
- Using Cloud Firestore to power a Slack app
- Distributing your Slack application
Breaking apart files
Before jumping into integration with Cloud Firestore, I did a good bit of repository clean up to prepare for those changes.
I broke apart reflect/main.py into a bunch of smaller,
more focused files.
I moved utility methods into reflect/utils.py
and Slack API integration into reflect/api.py.
I moved endpoints handling events into reflect/events.py
and those handling Slash Commands into reflect/commands.py.
from api import get_message, slack_api from utils import block, verify
Finally, I also moved functionality for storing and retrieving
reflections into storage.py, which is where we’ll do most of
the implementation work in this post.
Single function with dispatch
Adding storage is going to require changes
to event_post, reflect_post and recall_post.
In the current structure, that would require
deploying all three functions after each change, which
feels a bit overly complex.
To avoid that, I’ve shifted to use a single entry point,
named dispatch, and declared routes to identify
the correct handler for a given request.
def dispatch(request):
signing_secret = os.environ['SLACK_SIGN_SECRET'].encode('utf-8')
verify(request, signing_secret)
# events are application/json, and
# slash commands are sent as x-www-form-urlencoded
route = "unknown"
if request.content_type == 'application/json':
parsed = request.json
event_type = parsed['type']
route = 'event/' + event_type
if 'event' in parsed and 'type' in parsed['event']:
route += '/' + parsed['event']['type']
elif request.content_type == 'application/x-www-form-urlencoded':
data = request.form
route = 'command/' + data['command'].strip('/')
for path, handler in ROUTES:
if path == route:
return handler(request)
print("couldn't handle route(%s), json(%s), form(%s)" % \
(route, request.json, request.form))
raise Exception("couldn't handle route %s" % (route,))We’re then able to specify our various routes
within the ROUTES global variable.
ROUTES = (
('event/url_verification', url_verification_event),
('event/event_callback/app_home_opened', app_home_opened_event),
('event/event_callback/reaction_added', reaction_added_event),
('command/reflect', reflect_command),
('command/recall', recall_command),
)If we want to add more routes in the future, we just add a route and a handler, no need to muck around within the Slack App admin, create a function or whatnot.
We do need to create the Cloud Function for dispatch though, so go ahead and create
it using the gcloud CLI.
gcloud functions deploy dispatch \
--env-vars-file env.yaml \
--runtime python37 \
--trigger-http
Then write down the new routing URL.
https://your-url-here.cloudfunctions.net/dispatch
Then I updated both /reflect and /recall Slash Commands to point to it in Slash Commands,
and also clicked over to Event Subscriptions and updated the Request URL.
With this cleanup complete, now we can shift into what we came here to do: adding storage.
Provisioning Firestore database
Since we’re already deep in Google Cloud’s tech stack for this project, we’re going to use Google Firestore for our backend, largely following along the Firestore quickstart for servers.
First step is creating a new Firestore database.
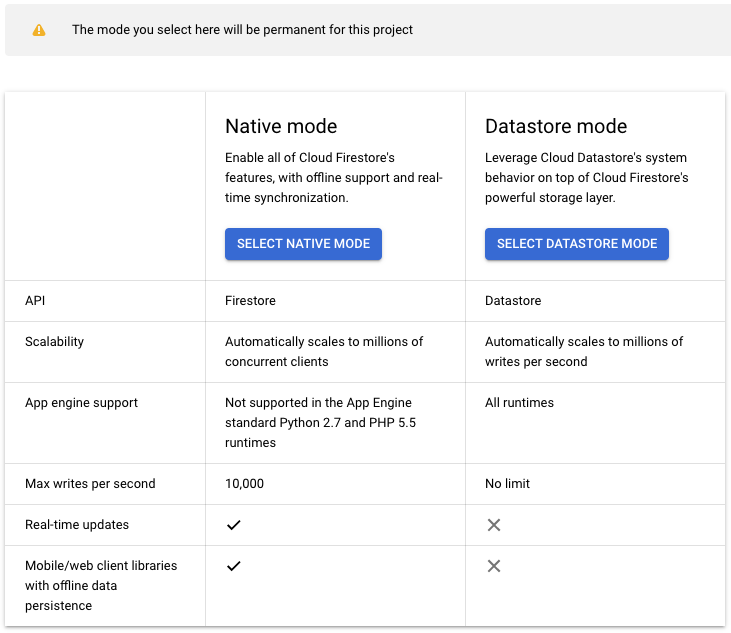
Select Native Mode, which is the newer version. The older version, Datastore mode, is being deprecated and has less functionality.
Next you’ll need to select a region for your database, and whether you want a single-region database or a multi-region database. You want a multi-region database, although confirm that by reading the pricing page. The free tier is the same for both, and the price is just under twice as much for multi-region but still cheap.
At this point your Firestore will start provisioning, which will take a couple of minutes.
Authentication credentials
Next we need to create authentication credentials to make requests to Firestore. First remind yourself of the project id for your project.
gcloud projects lists
Then create a service account.
gcloud iam service-accounts create reflectapp
gcloud projects add-iam-policy-binding reflectslackapp \
--member "serviceAccount:reflectapp@reflectslackapp.iam.gserviceaccount.com" \
--role "roles/owner"
Then generate keys.
This will create a JSON file with your credentials in
reflect/ as gcp_creds.json.
gcloud iam service-accounts keys create \
gcp_creds.json \
--iam-account reflectapp@reflectslackapp.iam.gserviceaccount.com
If you run the command in a different directory, move your gcp_creds.json
into reflect/.
Then we need to update reflect/env.yaml to point towards
the credentials file.
SLACK_SIGN_SECRET: your-secret
SLACK_BOT_TOKEN: your-bot-token
SLACK_OAUTH_TOKEN: your-oauth-token
GOOGLE_APPLICATION_CREDENTIALS: gcp_creds.json
With that, your credentials are good to go.
Add Python dependency
We’ll need to add the Python library for Firestore
to our requirements.txt as well:
requests==2.20.0
google-cloud-firestore==1.6.0
You can install it into your local virtual environment via:
source ../venv/bin/activate
pip install google-cloud-firestore==1.6.0
Now we can start integrating with Firestore.
Modeling data in Firestore
Before we start our integration, a few words on the Firestore data model. From a distance, Firestore collections are similar to SQL tables, and Firestore documents are similar to SQL rows. Each document contains a series of key-value pairs, which can be strings, timestamps, numbers and so on.
However, these documents are considerably more capable than typical rows,
and can contain sub-collections and nested objects.
Our data model is going to be a collection of users, with each user
having a subcollection of tasks, and each call to /reflect will create a new task.
Reading and writing to Firestore
Let’s walk through performing the various operations we might be interested
in using the Python google.cloud.firestore library, starting with
creating a document.
Note that creating a document implicitly creates the containing collection,
no need to create it explicitly.
>>> from google.cloud import firestore
>>> db = firestore.Client()
>>> doc = db.collection('users').document('lethain')
>>> doc.set({'name': 'lethain', 'team': 'ttttt'})
update_time {
seconds: 1573350318
nanos: 108481000
}You can also create a document without specifying the document id.
>>> col = db.collection('users')
>>> col.add({'name': 'lethain', 'team': 'ttttt'})
update_time {
seconds: 1573370218
nanos: 107401000
}Retrieving an individual document.
>>> db.collection('users').document('lethain').get().to_dict()
{'team': 'ttttt', 'name': 'lethain'}Retrieving all objects in a collection.
>>> for doc in db.collection('users').stream():
... print(doc.to_dict())
...
{'name': 'another', 'team': 'ttttt'}
{'name': 'lethain', 'team': 'ttttt'}Then let’s take a stab at retrieving a subcollection, for example
all the tasks created by the user lethain.
>>> tasks = db.collection('users').document('lethain').collection('tasks')
>>> tasks.document('a').set({'name': 'a', 'text': 'I did a thing'})
update_time { seconds: 1573350799 nanos: 411757000 }
>>> tasks.document('b').set({'name': 'b', 'text': 'I did another thing'})
update_time { seconds: 1573350807 nanos: 355376000 }
>>> for doc in tasks.stream():
... print(doc.to_dict())
...
{'name': 'a', 'text': 'I did a thing'}
{'text': 'I did another thing', 'name': 'b'}What about filtering retrieval to a subset of documents?
>>> for task in tasks.where('name', '==', 'b').stream():
... print(task.to_dict())
...
{'name': 'b', 'text': 'I did another thing'}
>>> for task in tasks.where('name', '==', 'c').stream():
... print(task.to_dict())
...
>>> We can use other operators, such as >=, <= and so on in our where clauses.
As we get into our actual implementation, we’ll use the where clause filtering
on timestamps to retrieve only tasks in the last week by default, and dynamically
depending on user supplied parameters.
We can also order and limit the results.
>>> query = tasks.order_by('name', \
direction=firestore.Query.DESCENDING).limit(5)
>>> for task in query.stream():
... print(task.to_dict())
...
{'name': 'b', 'text': 'I did another thing'}
{'text': 'I did a thing', 'name': 'a'}Deleting an object works about how you’d expect.
>>> db.collection('users').document('another').delete()
seconds: 1573351166
nanos: 188116000Deleting all objects in a collection deletes the collection, with the weird caveat that deleting a document does not delete its subcollections, so I could imagine it’s easy to strand data this way.
Alright, we’ve put together enough examples here to actually implement our task storage and retrieval functionality and replace those long-standing stubs.
Implementing reflect
So far when users /reflect on a task, we’re printing the data
into a log but otherwise ignoring it.
def reflect(team_id, user_id, text):
print("Reflected(%s, %s): %s" % (team_id, user_id, text))Now we can go ahead and replace that with something that works,
starting with a utility function to retrieve the tasks collection
for a given user within reflect/storage.py.
def tasks(team_id, user_id):
key = "%s:%s" % (team_id, user_id)
ref = DB.collection('users').document(key).collection('tasks')
return refThen we’ll use that collection to implement recall.
def reflect(team_id, user_id, text):
doc = {
'team': team_id,
'user': user_id,
'text': text,
'ts': datetime.datetime.now(),
}
col = tasks(team_id, user_id)
col.add(doc)Deploy an updated version, and voila, your data is actually being stored. Add a new task in Slack.
/reflect I've added Firestore to this thing #slack #firestore
Then we can verify within the Firestore data explorer.
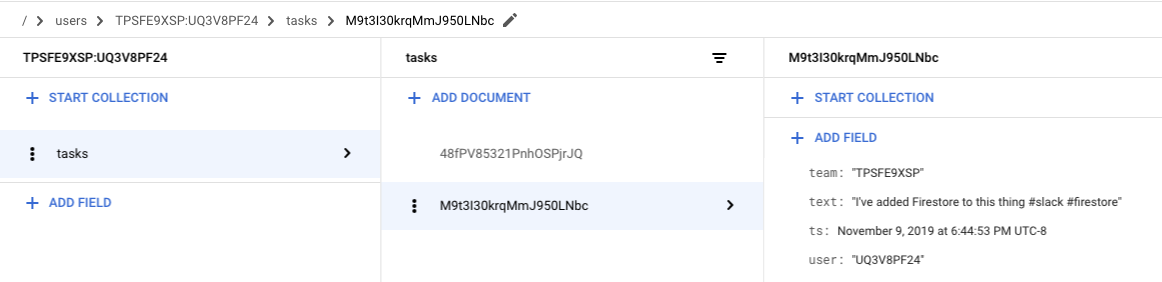
This is pretty great! Just a few lines of code and our Slack app is starting to do something real.
Implementing recall
Staying in reflect/storage.py, we’ll use the same tasks function
to retrieve the collection of user tasks and then stream out the related
task documents.
def recall(team_id, user_id, text):
col = tasks(team_id, user_id)
for task in col.stream():
yield task.to_dict()['text']We could certainly imagine doing more to fully support
the implied query language in /recall documentation,
but I think we’ve done enough to demonstrate the scaffolding to
iterate into the real thing.
Deploy this updated /recall, and we can give it a try.
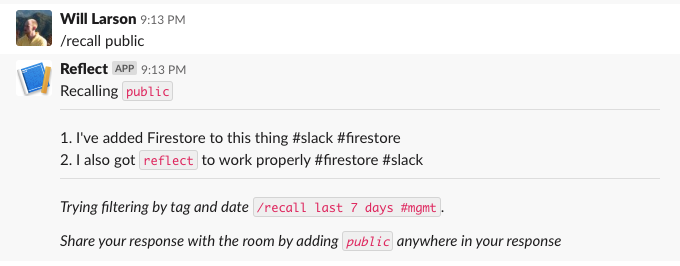
What about the reacji, do those work?
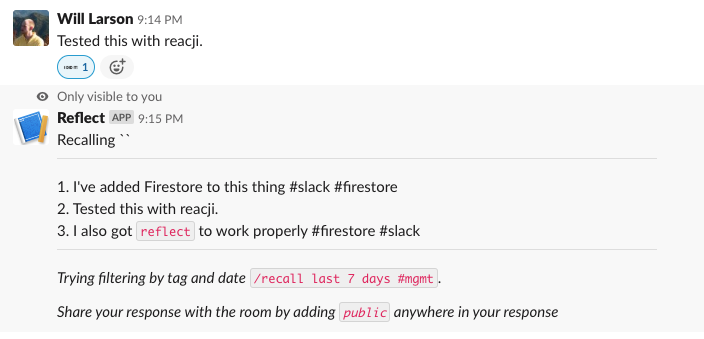
Yup, that works, then finally we just have to check in on the App Home and verify if that works too.
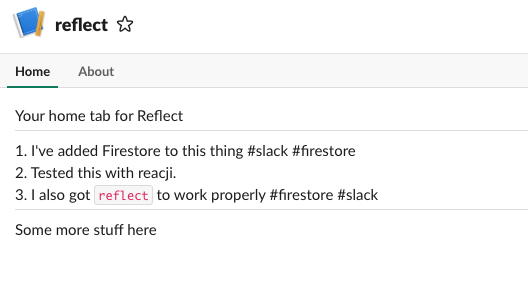
Yup, it looks like our app is truly working.
Thoughts on Cloud Firestore
This was my first chance to work with Cloud Firestore, and I came away quite excited by it. It’s admittedly a fairly constrained set of query patterns, but after working with early versions of Cassandra I feel pretty comfortable modeling data within tight constraints.
Altogether, it started up quickly, was responsive, was expressive enough, and is quite cheap for this sort of small workload. Quite a lot to like.
I did find the Firestore documentation a bit scattered. What I was looking for was usually somewhere but not quite where I expected it, and I also ran into at least one page of documentation that directed to a 404, which was a bit surprising.
Next
We’ve come a long way. One post left, which will be focused on getting the app publishable so that other folks can install it!
continue in Distributing your Slack application