Serverless: Gatekeeping and Profit Margins
In the beginning, we had servers behind a load balancer. Each server of a given kind (api servers, frontend servers, etc) had the same set of processes running on them, and each application bound to the same statically allocated port on every server.
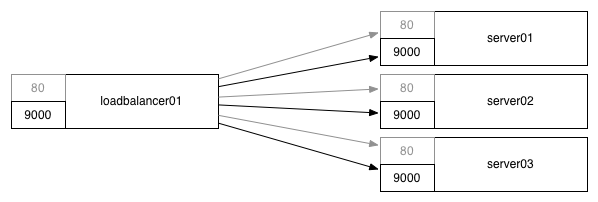
This worked well! Over time we wanted to take better advantage of our often under utilized servers, and adjusting our CPU to memory to IOPS ratio during the three year SKU depreciation cycle wasn’t fast enough as our system architectures continued to quickly evolve.
This and the increasingly wide availability of reliable cloud providers drove virtual machine adoption, which maintained the existing server level abstraction, but allowed multiple virtual servers to cotenant on a given physical server. It didn’t change the load balancing story or the static port allocation much though: all servers of the same kind continued to run the same processes.
VMs enabled increased hardware efficiency through cotenanting, but you were in two scenarios:
- Running on the cloud, in which case improved bin packing strategies benefit the cloud provider, not you.
- Running on your own hardware, in which case you were very likely statically mapping VMs onto servers, such that improving your VM to server allocation was time consuming, and at any given point your allocation was fairly sub-optimal, although better than the pre-VM scenario since now you have smaller pieces to allocate into the bins.
Manual bin packing has become increasing challenging as patterns like service oriented architecture and microservices have exploded the number of bespoke processes a given company runs from a handful to hundreds (or even thousands). Fortunately, over the past few years, several long-running trends have started to come together to obsolete manual bin packing!
First, real-time configuration mechanisms, like etcd and consul, have made refreshing configuration files (for e.g. a software loadbalancer like HAProxy) have latencies of seconds instead of minutes or hours. This is an important precursor to dynamic process scheduling, as you can’t move processes efficiently if there is a long delay between a process being scheduled on a server and sending it traffic.
Next, the move to containers like rkt and docker has crisply decoupled the environment processes run in from the servers they run on, making it possible for infrastructure engineers to place any stateless service on almost any server within their fleet. This has eroded the idea of a static mapping between services and server roles: where once your app servers ran some specific list of services defined in Puppet, now one server role can run all your services, and the services no longer need to be defined within your configuration management (although if you’re not using a scheduler, they still have to be defined somewhere, which might end up being your config management).
(With due apologies, I’m very much ignoring stateful services here, including databases and such. My sense is that each stateful service will continue being statically mapped to a server role for the time being in most infrastructure setups. This will eventually no longer be true as we move towards local-storage-as-a-service technologies like EBS and GFS/Colossus, or as stateful services move to models with sufficient small overlapping shards that recreating a lost node is a trivial event that can happen constantly in the background without degrading the system’s behavior.)
Finally, building on both real-time configuration to drive service discovery and containers to allow a single server role for all stateless services, we’re entering a golden age of process scheduling, like kubernetes and mesos, which elevate us from periodic human-or-script driven static allocation to dynamic allocation that occurs in something approaching real-time (perhaps it’s every hour or day, but certainly much faster than waiting for someone to manually rebalance your cluster).
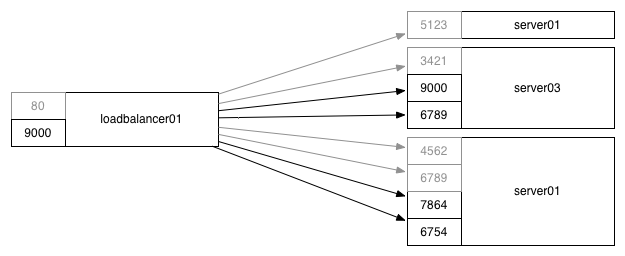
From an infrastructure perspective, these combine into something pretty remarkable!
First, we’ve moved from static port allocation to dynamic port allocation, such that you can run many copies of a given application on a server. (You can also run zero instances, wasting fewer resources on idle service as compared to the static mapping of service to a given server role.)
Next, we’re able to dynamically scale our services, bringing the optimizations, and the pain, of AWS’ autoscaling groups to our infrastructures, even if we’re running on physical hardware. This gives us a programmatic interface to automate efficient bin packing, allowing us to get some nice cost/efficiency benefits without harming any humans in the process.
Most importantly, we have this phenomenal separation of concerns between the product engineers writing and maintaining the processes and the infrastructure engineers who are providing the platform which schedules those processes. Service owners can pick the right tooling for their needs, infrastructure can run the built container without any awareness of the container’s contents, and the two sides rely on the backpressure from quality of service and cost accounting to steer towards a mutually sustainable balance without the upfront gatekeeping and tight coordination introduced by the static service to server mapping model.
The above model still depends on persistent processes which can accept routed requests, or you could have persistent processes pulling from a queue, but in either case the processes are long-running. As we start drilling into our services usage patterns, a large number of these services probably get close to no traffic, but we’re still running at least three instances for redundancy purposes.
Let’s imagine we create a new scheduler, which doesn’t schedule processes, but instead it pre-positions containers across your fleet such that you could start the contained processes without having to first copy the container’s contents to the server. Now let’s imagine we have local SSDs on our servers, or that we have network local storage which is fast enough that you can read the container in a handful of milliseconds. This would allow each of your servers to have the potential to run hundreds or thousands of services.

Building on our prepositioned containers, let’s say we can start one of them in a couple hundred milliseconds. Now incoming requests to our load balancer look a bit different:
- If there aren’t instances already running, ask the scheduler to start one of the preposition containers.
- Route to an existing container.
Now, we only need to persistently run processes which have frequent incoming traffic. For anything which takes less than two requests per second, it is more efficient for us to recycle immediately, although the exact math here depends a bit on how strongly we want to weight the latency cost. Throughput shouldn’t be much of an issue because we’ll amortize the spinup cost across many requests if we get a spike. For throughput beyond the capacity of a single process, we can make our load balancer a bit smarter such that it can add capacity if a service’s latency grows too high (modulo some mechanism to prevent infinite autoscaling in degenerate cases).
This is pretty awesome, and has reduced our incremental cost-per-service to almost zero from a scheduling infrastructure and infrastructure engineering perspective, but there are two interesting things happening here:
First, although we’ve reduced the infrastructure cost of new services to near zero, the human costs for service owners to maintain a large number of services is not going down. Quite the opposite: historically the friction of introducing more infrastructure has somewhat unintentionally kept the cardinality of libraries and frameworks at a given company low. Without those constraints, companies often lack an immune system to prevent the introduction of new technologies, and the number starts to grow linearly with either time or developer headcount or both!
The other issue is that while the friction of creating services has gone down, and depending on your workload, the cost of running services is now bound on disk costs instead of cpu/memory, you’re still paying some fixed cost per service. Getting that cost as low as possible depends mostly on container size, which varies greatly. Looking at Docker’s layering system, if you can drive towards a highly unified stack of frameworks and dependencies, then you can reduce the space per container to something remarkably small.
(In terms of active load, the underlying platform’s cost efficiency also depends a great deal on programming language, so I imagine we’ll see a lot of movement towards highly cpu and memory efficient languages like Go for serverless applications. Node seems like an early focus, although it’s not particularly CPU or memory efficient and has a fairly high latency garbage collector, but it is relatively decoupled from the underlying O/S, and has a large library and developer ecosystem. Seemingly, this early on it probably makes more sense to drive adoption and efficiency.)
These are, in my opinion, the twin concerns driving serverless adoption: on one hand, companies trying to regain centralized control of their software now that infrastructure friction doesn’t serve as an inadvertent gatekeeper, and on the other cloud providers using aws lambda and cloud functions to drive cost efficiencies in their massively multi-tenant clouds.
Neither of these are reasons why we shouldn’t be moving to serverless!
It’s great if clouds can get more cost efficient, especially if you’re running an internal cloud, and although I’m skeptical of the gatekeeping model of top-down architecture, it’s also clear that most companies struggle to figure out an effective alternative to nudge teams to make company-optimal decisions instead of team-local decisions. (Although I suppose if we apply the Innovator’s Dilemma’s lessons, it seems possible that being company-optimal in the short-term is actually company sub-optimal in the long run.)
My other ending thought is that I suspect that developing serverless applications is going to feel a lot more like developing monoliths than developing microservices. Even though they’re being scheduled and perhaps even deployed as independent units of code, their aggressive minimalism will force them to lean very heavily on the framework they run in, and you’ll either be back in the monolith change coordination challenge or you’ll be in the degenerate microservices scenario where you have to individually migrate every function to each new version. The former sounds a lot more pleasant.