Scalable Scraping in Clojure
Craigslist is a great website. So great, it so happens, that I've heard some people spend a considerable amount of time staring at its endless stream of postings.
Thinking about that, it occurred to me that a script which monitors the post stream and saves relevant postings to disk might be a nice project for using Clojure to perform concurrent fetches and concurrent processing.
Prerequisites
Before getting started, you'll need to have
- installed Clojure (this tutorial was written with the 1.0 release),
- installed clojure-contrib (written with the version compatible with 1.0 release).
If you've got those, then we're ready to go. If you don't have those, the tutorial is going to be waiting right here while you take care of your errands.
Architecture
There are many ways to pull some content down from Craigslist, parse it, and then write a subset to disk. Of those many ways, some are simple and straightforward. This solution isn't one of those.
Instead, this tutorial looks to develop a scalable and extendable approach, with an emphasis on concurrent processing.
The system is divided into two sub-components: content retrieval and content processing. These two communicate via a shared queue (retrieval places data onto the queue, processing reads data off of it). First, let's look at the content retrieval portion.

The goal of content retrieval is to convert a list of Craigslist categories into a queue filled with the meta-data about each contained post.
The flow of retrieval is
- pull down the recent posts in one or more Craigslist categories,
- extract each post's URL,
- submit the URLs to a pool of worker agents,
- have worker agents retrieve URLs and deposit the retrieved data into the post-queue.
Next up, the content processing portion of the system.
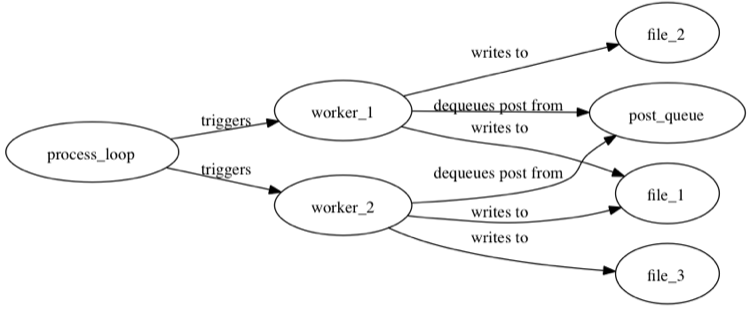
The aim of content processing is to
- dequeue posts from the post-queue,
- use user-defined filters (a filter is a list of required words) to sort them into buckets (where a given post might exist in multiple buckets),
- and then write the posts in each bucket to separate files.
As the application runs the filter-files will continue to grow, filled with posts which satisfy the topics' requirements. You'll never need to obsessively check Craigslist again.
Instead you can obsessively check a series of text file. Isn't progress grand?
Discovering New Posts
As we start to assemble the components for our script, first we'll put together the code to retrieve the recent posts in a Craigslist category.

To accomplish this, we'll first need to be able to fetch the listing page's html.
duck-streams is wise to the http protocol, which makes this the simplest
of possible ways to retrieve webpages:
lists:foreach(fun(Pid) ->
Pid ! {self(), update, Key, Value}
end, pg2:get_members(kvs)),
Sender ! {self(), received, {set, Key, Value}},
After fetching the raw HTML, we need to extract all of the job postings' URLs. Each of those posts looks something like this:
-define(KVS_WRITES, 3).
-define(KVS_READS, 3).
-define(TIMEOUT, 500).
So we can extract the a URL using re-find and a regex like this:
-record(kvs_store, {data, pending_reads, pending_writes}).
However, we really want to be able to extract all matches from the text, rather than just the first one. For this we can use re-seq:
% a brief interlude for record syntax
Store = #kvs_store{data=[], pending_reads=[], pending_writes=[]},
#kvs_store{data=D, pending_reads=R, pending_writes=W} = Store,
Writes = Store#kvsstore.pending_writes,
get_value(Key, S=#kvs_store{data=Data}) ->
proplists:get_value(Key, Data).
set_value(Key, Value, S=#kvs_store{data=Data}) ->
S#{data=[{Key, Value} | proplists:delete(Key, Data)]}.
From there we can wrap this in a function to allow us to specify arbitrary post categories:
-include("kvs.hrl").
Really, we only want the second part of each match (the URL, as opposed to the full match),
which we can get by running the results through map:
%% @doc create N nodes in distributed key-value store
%% @spec start(integer()) -> started
start(N) ->
pg2:create(kvs),
lists:foreach(fun(_) ->
Store = #kvs_store{data=[],
pending_reads=[],
pending_writes=[]},
pg2:join(kvs, spawn(kvs, store, [Store]))
end, lists:seq(0, N)),
started.
Finally, we really want the full url, not just the relative URL, which we can generate by
prepending http://craigslist to the relative URLs.
% old definition
store(Data) -> term().
% new definition
store(Store = #kvs_store{data=Data,
pending_reads=Reads,
pending_writes=Writes}) -> term().
With that, the first piece of the project is complete.
Extracting Data from Posts
The next step is to write a function which takes a post's url, retrieves the raw HTML for that post, and then extracts the post's metadata (meaning in this case its title and body).
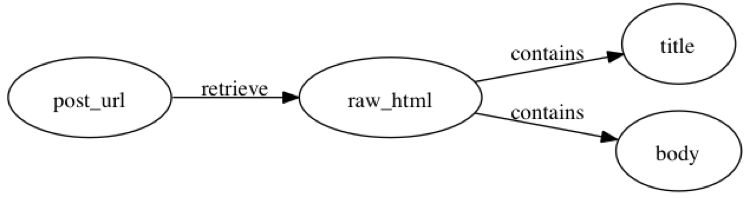
From the html, we're looking for these two snippets:
store(Data, Reads, Writes) -> term().
If we can just extract those, we're in business. An adequate attempt looks like this:
{Sender, set, Key, Value} ->
% client interface for updating values
lists:foreach(fun(Pid) ->
Pid ! {self(), update, Sender, Key, Value}
end, pg2:get_members(kvs)),
Writes2 = [{ {Sender, Key}, ?KVS_WRITES} | Writes],
store(Store#kvs_store{pending_writes=Writes2});
One issue is that the extracted body is littered with HTML tags, but we can remedy that fairly easily (with due apologies, this really is much more brief than bringing in an external dependency, and it isn't particularly important if it works well... which it does not):
{Sender, update, Client, Key, Value} ->
% sent to all nodes by first receiving node
Sender ! {self(), updated, Client, Key, Value},
store(Store#kvs_store{data=[{Key, Value} |
proplists:delete(Key, Data)]});
With that, two pieces of our project have been assembled. Onward we go.
Filtering Posts
The next step is to take the list of post data and then discover the posts which we're interested in. The end goal is to support any number of filters, where each filter is written to a separate file, and each filter contains a list of representative words. (Each filter is run on every post, which means that a given most can be accepted by more than one filter.)
To get started, we might create these two filters:
{_Sender, updated, Client, Key, Value} ->
Count = proplists:get_value({Client, Key}, Writes),
case Count of
undefined ->
store(Store);
0 ->
Client ! {self(), received, {set, Key, Value}},
store(Store#kvs_store{
pending_writes=proplists:delete({Key, Value}, Writes)});
_ ->
store(Store#kvs_store{
pending_writes=[{ {Client, Key}, Count-1} |
proplists:delete({Client, Key}, Writes)]})
end;
A simple first attempt at filtering posts would be to only accept posts that contain all the specified words. There are many ways you could implement word detection, but perhaps the simplest approach is to tokenize the string:
{Sender, get, Key} ->
% client interface for retrieving values
lists:foreach(fun(Pid) ->
Pid ! {self(), retrieve, Sender, Key}
end, pg2:get_members(kvs)),
% ?KVS_READS is required # of nodes to read from
% [] is used to collect read values
Reads2 = [{ {Sender, Key}, {?KVS_READS, []}} | Reads],
store(Store#kvs_store{pending_reads=Reads2});
From there, we can check that the hashmap contains a list of expected words.
{Sender, retrieve, Client, Key} ->
Sender ! {self(), retrieved, Client, Key, proplists:get_value(Key, Data)},
store(Store);
Building on these pieces, we need to combine tokenize and has-keys? into
a single function which evaluates a post and determines if it matches the filter.
{_Sender, retrieved, Client, Key, Value} ->
case proplists:get_value({Client, Key}, Reads) of
{0, Values} ->
Freq = lists:foldr(fun(X, Acc) ->
case proplists:get_value(X, Acc) of
undefined -> [{X, 1} | Acc];
N -> [{X, N+1} | proplists:delete(X, Acc)]
end
end, [], Values),
[{Popular, _} | _ ] = lists:reverse(lists:keysort(2, Freq)),
Client ! {self(), got, Popular},
store(Store#kvs_store{
pending_reads=proplists:delete({Key, Value}, Reads)});
{Count, Values} ->
store(Store#kvs_store{
pending_reads=[{ {Client, Key}, {Count-1, [Value | Values]}} |
proplists:delete({Client, Key}, Reads)]})
end;
Okay, we're getting pretty close now, just one more piece to write and then we can start integrating the pieces.
Writing Matching Posts to File
All posts for a given filter should be written to the same file, and since multiple workers might be processing posts at the same time, we'll need to provide a way to sequence writes on the shared file.
The easiest way to achieve this is to use an agent to guard the files. We're currently
defining filters as a list of key terms, but let's expand the definition to be a hash-map
where the key :tags contains the list of terms, and :file contains an agent whose
value is a filename.
ts() ->
{Mega, Sec, _} = erlang:now(),
(Mega * 1000000) + Sec.
Then we can write a function which takes a filter and a post and writes the post to file.
{Sender, set, Key, Value} ->
lists:foreach(fun(Pid) ->
Pid ! {self(), update, Sender, Key, Value}
end, pg2:get_members(kvs)),
Writes2 = [{ {Sender, Key}, {?KVS_WRITES, ts()}} | Writes],
store(Store#kvs_store{pending_writes=Writes2});
(Please beware that I have been getting errors about append-spit not
being publicly available when running the code via the script runner, but when
using (load-file "cl.clj") it works fine. To manage complexity I decided against
rewriting an append-spit duplicate in this tutorial, but you'll probably
need to--or slightly modify the duck-streams code that is suggested for
using with Clojure 1.0.)
Using the save-post function looks like:
{_Sender, updated, Client, Key, Value} ->
{Count, Timestamp} = proplists:get_value({Client, Key}, Writes),
case Count of
undefined ->
store(Store);
0 ->
Client ! {self(), received, {set, Key, Value}},
store(Store#kvs_store{
pending_writes=proplists:delete({Key, Value}, Writes)});
_ ->
store(Store#kvs_store{
pending_writes=[{ {Client, Key}, {Count-1, Timestamp}} |
proplists:delete({Client, Key}, Writes)]})
end;
Now that we've put together all the components, we can start piecing them together into a working system.
Wiring the System
The system we're putting together can be thought of as having two independent subcomponents: populating the post queue, and depopulating the post queue.
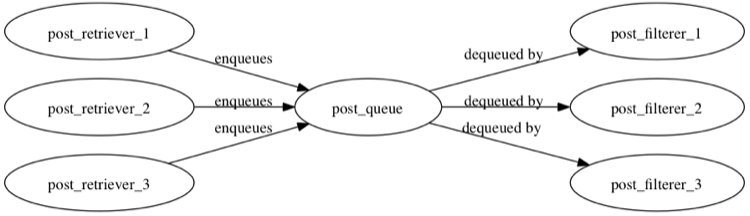
We'll take advantage of this decoupling by implementing the two halves independently. Using this level of decoupling in what could be implemented as a fifty line script is definitely overkill, but decoupling code by interacting with shared datastructures is a specialized case of the hardest task in team software development: defining interfaces.
It seems likely that all interfaces are just operations on a datastructure (key-value stores like Dynamo are hash-maps), or can be thought of as simple algorithms on simple algorithms (most Twitter apis can be modeled as filters on an array, although one imagines the implementation may differ). So, the generous reader may choose the believe the decoupled design is an opportunity to practice this important skill.
I suspect the ungenerous reader stopped reading a long time ago.
Queuing Posts in the Post Queue
The components to wire together here are:
- Spreading categories over a pool of agents,
- spreading the posts in each category over another pool of agents
- storing each retrieved post in the post-queue,
- wiring a timer to periodically trigger the category retrieval.
This sounds fairly complex, but the implementation is fairly concise thanks to all the functions we have written thus far. First we need to write several functions for creating and sending to agent pools.
after
?KVS_POLL_PENDING ->
Writes2 = lists:filter(fun filter_writes/1, Writes),
Reads2 = lists:filter(fun filter_reads/1, Reads),
store(Store#kvs_store{pending_writes=Writes2,
pending_reads=Reads2})
end.
We could improve upon agent-from-pool to ensure fairness over
the agent pool, but for the time being the random assignment is sufficient.
Using our agent-pools, we can now throw together the content retrieval portion.
qaodmasdkwaspemas18ajkqlsmdqpakldnzsdfls
(The sleeps are to avoid pegging the site with requests. Not that it is likely that our little scraper will break Craigslist, rather it seems much more likely that Craigslist might break our little crawler.)
Usage looks like:
qaodmasdkwaspemas19ajkqlsmdqpakldnzsdfls
With the post-queue populating, it's time to move on to processing the posts.
Dequeuing Posts from the Post Queue
The steps in dequeuing and processing the collected posts are:
- Create a polling app which will either:
- attempt to dequeue a post, assign it to a random worker thread, send itself a message to check the queue again,
- or sleep for several seconds before sending itself a message to check the queue again.
- Each worker thread will take a post, pass it through the filters, and then append it to the filter's file as appropriate.
Reusing the agent-pool functions from above, it looks like this.
qaodmasdkwaspemas20ajkqlsmdqpakldnzsdfls
Usage looks like:
qaodmasdkwaspemas21ajkqlsmdqpakldnzsdfls
With that, we just need to wire in some periodic pings to run the category retrieval and queue processing elements.
Scheduling Periodic Events
There are a couple of ways to handle periodic scheduling of messages to agents. The simplest is the old standard do forever loop with a sleep inside, but you can actually do periodic scheduling using agents to perform the periodic sends.
I'll be writing a post about this idea in the next couple of days, but here is a very
simple form we can use to trigger the process-posts
function we have just finished writing (we'll call process-categories manually,
since we don't actually have a mechanism to prevent duplicate posts being fetched).
qaodmasdkwaspemas22ajkqlsmdqpakldnzsdfls
And with that, we're finally done.
The Finish
The final source for the project is available on Github.
Please let me know if you encounter any issues in the code.
This example ended up becoming a bit longer and much more complex than expected, but hopefully there are some tidbits worth understanding. In many ways, this example parallels a possible design for a very heavy-weight implementation in terms of performance and scalability, but with the help of agents is nonetheless quite concise.
Clojure is a lot of fun, in no small part because it generates such brief code. Writing brief and expressive code is probably the secret joy of working with lispy languages. Hopefully my next entries will be a bit less convoluted than this one, to better demonstrate those properties. ;)
Acknowledgements
This article owes debts of varying sizes to:
- Clojure
- clojure-contrib
- Mark Reid's Setting Up Clojure for Mac OS X
- Fetching Web Comics with Clojure, Part 1
Thanks for reading, I hope it was helpful and I'm always glad for feedback. Let me know what you think!