Reclaim unreasonable software.
Big Ball of Mud was published twenty years ago and rings just as true today: the most prominent architecture in successful, growth-stage companies is non-architecture. Crisp patterns are slowly overgrown by the chaotic tendrils of quick fixes, and productivity creeps towards zero.
After a couple years wallowing at zero, many companies turn towards The Grand Migration pattern and rewrite their software. These rewrites are quite challenging and often fall.
An alternative path, which I wrote about in You can’t reason about big balls of mud, is to stop reasoning about your software, but instead move towards empirical experimentation to guide software changes. Experimentation lends more consistent results than rewrites, but suffers from being quite slow.
Here I’ll attempt to sketch out a third path: reclaim unreasonable software through verified behaviors and asserted properties. This approach is an alternative to experimentation and rewriting, as well as a general framework for maintaining reasonable software.
The excellent Jessica Kerr wrote Let’s reason about behavior about these ideas as well.
Golden Age & Apocalypse
Some software never successfully addresses the domain it aspires to solve, and the good news there is that at least you never need to maintain such software, because maintenance is reserved for valuable things.
If your software does succeed in addressing the problem domain, then it becomes Golden Age software. Golden Age software is the best of software in the best of circumstances. The team maintaining it is the team who designed it, intimately familiar with all its quirks. The problems it solves are mostly the problems it was designed to solve, within the constraints it was designed to satisfy.
At some point, you’ll find an extraordinarily elegant extension to the software, allowing you to solve an important new problem that wasn’t part of the original design. This solution will be heralded as a validation of how flexible the software is, but in retrospect you’ll realize this was the beginning of the Golden Age’s end: the elegant solve that foretold a growing inability to reason about the software.
Time fosters complexity and decays software. Teams decay too, with folks moving off to other projects and companies. At some point you’ll look up and realize you’re maintaining Post-Apocalyptic software whose evolution has become “lost technology”, harrowing to operate or extend. You have a book of incantations that tend to allow it to keep turning, but no one is comfortable making meaningful changes.
Rewrite or reclaim
The abstract deity known only as business value doesn’t care whether your software is easy to reason about, but it does care quite a bit about your ability to release new features and to operate your software well enough to retain users. At some point, the slowing velocity will become the discussion you have at planning and strategy meetings, with one resounding refrain: the status quo isn’t working.
At this point, many and perhaps most companies choose to rewrite their software. Mark it down as a lost cause, design a replacement, and craft a thoughtful migration plan to minimize risk. (And sometimes pulling new risks into the portfolios risk, such as a move from a monolith to a service-oriented-architecture.)
However, I’m increasingly confident that rewrites aren’t inevitable, and that you can intentionally reclaim software that has entered its Post-Apocalyptic phase by evolving beliefs into behaviors and properties.
Beliefs & properties
Post-Apocalyptic software is hard to modify because it doesn’t behave in predictable ways, instead you only have beliefs about how it works. Some beliefs you might have about your software:
- All state changes caused by an HTTP request are written atomically.
- Processes always attempts to read state from Redis before reading from MySQL.
- Reads after writes are only safe if performed against the primary server, and are unsafe against secondaries until the current time is greater than the time of write plus the current replication lag.
- Processes have no state, so requests will be handled correctly regardless of which process handles them.
It’s hard to write software based on beliefs, because they’re often wrong, so you end up having to empirically verify your solution, step by step. Or just fail a bunch, I’d say is a very slow, undirected form of empirical validation.
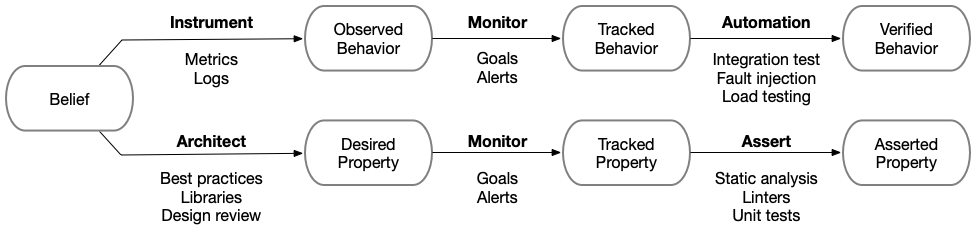
We make unreasonable software reasonable by turning each belief into either a behavior or a property. Behaviors are aspects of software that can be validated empircally against an environment. Properties are aspects of software that can be validated statically or through local exercise.
The distinction here is a bit nuanced, and you may find that your behaviors are another company’s properties and vice-versa. Exploring the distinction through examples:
- “Every file has at least one test” is a property you can enforce on your build server.
- “99.99% of requests complete within two seconds” is a behavior that you can monitor in your production environment.
- “Every execution branch is exercised by tests” is a property because it can be verified by running coverage tests on your host or on a build host. It doesn’t require an environment to exercise against.
- “All reads after write are performed against the primary database” is the sort of thing that most companies would verify by either (a) logging and verifying the behavior in logs or (b) a real-time assertion that errors on bad read-after-write behavior, both of which would make it a behavior.
- “State mutation for each requests is handled within a single transaction” is something you can verify statically by forcing all mutation into a constrained interface that has appropriate sematics, which makes it a property. Then again, some companies might be unwilling to constrain behavior to that extent, and might instead monitor the number of transactions per request, which would make it a behavior.
Let’s go a bit further into developing this taxonomy. There are three interesting gradients for behaviors:
- Observed behaviors are those which you can notice in your logs, metrics or dashboards.
- Tracked behaviors are those which you’ll get informed when they change, but only after operating updated software in an environment, for example an alert informing you about an increase in production latency.
- Verified behaviors are behaviors that you can rely on being consistently true because there is a timely mechanism that ensures them before deployment is complete. The three most common mechanisms for ensuring behavior are: (a) end-to-end integration tests, (b) fault injection that routinely trigger relevant failure modes, (c) load or performance testing that verifies software before completing deployment.
While it’s kind of annoying to confirm verified behaviors because they require an attempted deploy, it’s easy to design around them because you can be confident they remain true. Tracked behaviors are interesting, because they ought to be easy to design around (they’re tracked after all!) but tend to degrade over time without a dedicated organizational program ensuring that teams fix regressions. Most companies don’t have such a program for all relevant behaviors, so in practice they’re rather hard to design around, and each architectural change is preceeded by a period of fixing regressions in tracked behaviors before the intended change can be made.
A similar gradient applies to properties:
- Intended properties are those that you ask folks to maintain in their software, often propagated through design reviews, training, best practices documents and such.
- Tracked properties are those that are reported on but without an enforcement mechanism. Code coverage falls into this category for many companies, where they report on changes but don’t block deployment.
- Asserted properties are enforced before deployment begins, generally through static analysis, code linters or unit tests.
What I find particularly interesting about properties is that at their worst they are misleading and harmful – who hasn’t been in a conversation where someone bemoans a team not properly observing an undocumented but intended property – and at their best they are the easiest to design around and provide by far the best development experience.
The productivity advantages of asserted properties over behaviors (even at their verified best) is most obvious when comparing large codebase productivity between dynamically and statically typed programming languages. Statically typed languages provide an immediate feedback loop on several categories of errors that would otherwise require a full deployment cycle.
The vast majority of companies out there have zero verified behaviors and close-to-zero asserted properties, but that’s not because this is particularly challenging, it’s just that they’ve never considered how powerful it is to have software they can reason about.
Conversely, most long-lived companies that are able to maintain execution velocity have a significant number of either verified behaviors or asserted properties, and often both. Each company is allowed to rewrite exactly once, but afterwards you’ve got to learn how to reclaim your software instead.
Software reclamation
Coming back to your Post-Apocalyptic software: how do you regain the confidence to make changes? List out all the beliefs that you’d need to have in order to be confident in modifying your software, and then for each belief an approach for evolving it up the belief and property ladder.
You get the best results by evolving beliefs into asserted properties, followed by verified behaviors, but there is a surprising amount of value to moving them into tracked behaviors or properties as well, as it helps you understand the level of effort that’ll be required before you can begin reasoning about your software again.
If the scorecard is low enough, then you know it’s going to be easier to reclaim your software than to rewrite. If it’s high enough, then maybe the rewrite really will be easier.
The approach here isn’t only useful for reclaiming software, it’s a useful way to ratchet software against reasoning regression in the first place. Prevention remains the best fix.