Polishing Up Our Django & BOSS Search Service
In the first part of this series we spent some time setting up the Yahoo BOSS Mashup Framework, and ended by putting together an extremely minimal search service. For those who didn't work through part one, you can grab a zip of what we developed here, but you'll need to follow the instructions in part one for acquiring a BOSS App ID. In this second part of the series we are going to flesh out our search service a bit:
- We're going to let users search either the web, Yahoo News, or images.
- We're going to let users page through search results.
Lets get moving.
Expanding SearchForm
First, open up my_search/yahoo_search/views.py and take a look at SearchForm. At the moment all we have is this:
class SearchForm(forms.Form):
search_terms = forms.CharField(max_length=200)
Now we're going to want to add functionality for changing the type of search:
SEARCH_TYPES = (('web','Web'),('news','News'),('images','Images'))
class SearchForm(forms.Form):
search_terms = forms.CharField(max_length=200)
search_type = forms.ChoiceField(SEARCH_TYPES)
Enhancing search and index
Now lets improve search to accept a second parameter that determines what kind of search it will perform.
def search(str, type):
data = ysearch.search(str,vertical=type,count=10)
news = db.create(data=data)
return news.rows
And update index to feed search the value search_type captured by our handy SearchForm.
def index(request):
results = None
if request.method == "POST":
form = SearchForm(request.POST)
if form.is_valid():
search_terms = form.cleaned_data['search_terms']
search_type = form.cleaned_data['search_type']
results = search(search_terms,search_type)
else:
form = SearchForm()
return render_to_response('yahoo_search/index.html', {'form': form,'results': results})
Now, go ahead and run the development server.
python2.5 manage.py runserver
Then navigate over to http://127.0.0.1:8000/, and you'll see that you can now search the web, images, or Yahoo News. Pretty nifty. Now lets get cracking on paginating our search results.
Paginating Search Results
When you are using Django and you think paginating, your train of thought should immediately turn to the Paginator class, which is very helpful at dealing all pagination messiness. However, we're not dealing with a normal list (or a QuerySet, in which case we could use the QuerySetPaginator), so we're going to have to massage things a little bit.
We're going to do that by creating an intermediary class, named BossResultList that will implement the subset of Python list functionality that the Paginator needs to function. Fortunately, thats only three methods: __getitem__(self,i), __getslice__1 and __len__. Create a file in my_search/yahoo_search named boss_utils.py, and in that file we're going to insert this code:
from yos.yql import db
class BossResultList(object):
def init(self, response):
self.data = response
details = self.data['ysearchresponse']
self.__start = int(details['start'])
self.__count = int(details['count'])
self.__totalhits = int(details['totalhits'])
self.__results = db.create(data=self.data).rows
<span class="k">def</span> <span class="nf">__getitem__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span><span class="n">i</span><span class="p">):</span>
<span class="k">return</span> <span class="bp">self</span><span class="o">.</span><span class="n">__results</span><span class="p">[</span><span class="n">i</span> <span class="o">-</span> <span class="bp">self</span><span class="o">.</span><span class="n">__start</span><span class="p">]</span>
<span class="k">def</span> <span class="nf">__getslice__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">i</span><span class="p">,</span> <span class="n">j</span><span class="p">):</span>
<span class="k">return</span> <span class="bp">self</span><span class="o">.</span><span class="n">__results</span><span class="p">[</span><span class="n">i</span><span class="o">-</span><span class="bp">self</span><span class="o">.</span><span class="n">__start</span><span class="p">:</span><span class="n">j</span><span class="o">-</span><span class="bp">self</span><span class="o">.</span><span class="n">__start</span><span class="p">]</span>
<span class="k">def</span> <span class="nf">__len__</span><span class="p">(</span><span class="bp">self</span><span class="p">):</span>
<span class="k">return</span> <span class="bp">self</span><span class="o">.</span><span class="n">__totalhits</span>
The BossResultList takes the results of ysearch_search and uses them to mimic a list. This isn't a perfect abstraction, because it will only allow access to the subset of results that it is passed in its init function, however, it will be enough to take advantage of Paginator2.
Now lets go back to my_search/yahoo_search/views.py and add two imports:
from django.core.paginator import Paginator
from boss_utils import BossResultList
Then we'll fix up search to play nicely with our new BossResultList.
def search(str, type, count=10, start=0):
return ysearch.search(str,vertical=type,start=start,count=count)
This change is necessary because BossResultList needs data contained directly
within the returned results that isn't carried over after the results are converted
into a database using the db.create function. (Specifically, it needs access
to the totalhits field that lets us inform users how many pages of results we can
serve them for their search query.)
Now we just have two little details remaining before we finish updating our search app:
revamping the index function, and updating our index.html template. Updating the
template will be easy, but we can't do that until we write index, which happens to
involve a pretty complete rewrite. Because there are so many changes I'll post the function
first, let you read over it, and then comment on particularly salient details.
def index(request,count=10):
results,page,total_pages,terms,type = None,None,None,None,None
if request.method == "GET":
form = SearchForm(request.GET)
if form.is_valid():
page = (request.GET.has_key('page') and int(request.GET['page'])) or 1
start = (page-1) * count
terms = request.GET['search_terms']
type = request.GET['search_type']
brl = BossResultList(search(terms,type,count=count,start=start))
paginator = Paginator(brl,count)
total_pages = len(brl) / count
results = paginator.page(page)
else:
form = SearchForm()
return render_to_response('yahoo_search/index.html',
{'form': form,'results': results,
'term': terms,'type': type,
'current_page': page,
'total_pages': total_pages})
Okay, a few things to mention.
We are now using GET instead of POST. In fact, we never really should have been using POST to begin with. Sorry about that.
Because we are using GET it's harder to distinguish between when a user first lands on the page and when they are submitting a search. That is why our response to an invalid form is not to display the error messages generated by newforms, but instead to display an empty form: the only time we'll encounter an invalid form is when a user first comes to the page, and we don't want to greet new users with error messages.
Paginator'spagecount starts at 1 instead of at 0 which is why we calculatestartas(page-1)*countinstead of aspage*count.We need
total_pagesandpagebecause we want to let users know where they are in the midst of the search results. (For example, on page 5 of 412.)
Updating the index.html template
Much like the index function, the index.html template
has received a substantial overhaul as well. Fortunately, the
changes to the template are largely self-explanatory. After
its remodeling it's going to look like this:
<html> <head>
<title>My Search</title>
</head>
<body>
<h1>My Search</h1>
<form action="/" method="GET">
<table>
{ { form }}
<tr><td><input type="submit" value="Search"></td></tr>
</table>
{% if results %}
{% if results.has_previous %}
<a href="?page={ { results.previous_page_number }}&search_terms={ { term|urlencode }}&search_type={ { type|urlencode }}"> Previous </a>
{% endif %}
<span> Page { { current_page }} of { { total_pages}} pages. </span>
{% if results.has_next %}
<a href="?page={ { results.next_page_number }}&search_terms={ { term|urlencode }}&search_type={ { type|urlencode }}"> Next </a>
{% endif %}
<ol>
{% for result in results.object_list %}
<li>
<span class="title">
<a href="{ { result.clickurl }}">{ { result.title|safe }}</a>
</span>
<span class="date"> { { result.date }} </span>
<span class="time"> { { result.time }} </span>
<span class="source">
<a href="{ { result.sourceurl }}">{ { result.source }}</a>
</span>
<p class="abstract"> { { result.abstract|safe }} </p>
</li>
{% endfor %}
</ol>
{% endif %}
</body> </html>
The most complex part is for handling advancing and retreating between pages of results.
Here we are using the Page returned by our Paginator to handle most of the
complexity (in this template context our Page is named results), but it gets
a bit more complex because we need to keep track of the search terms and the type of the search.
Download
You can grab a copy of this code here. Note that you'll need to
follow the instructions in the first part of this tutorial to acquire
a Yahoo BOSS App Id and to fill in your details in my_project/config.json.
Trying it out
Okay, now we're ready to try it all out. Go to the my_search directory and run the devel server.
python2.5 manage.py runserver
And navigate over to http://127.0.0.1:8000/ and you'll see our improved search engine that looks like this:
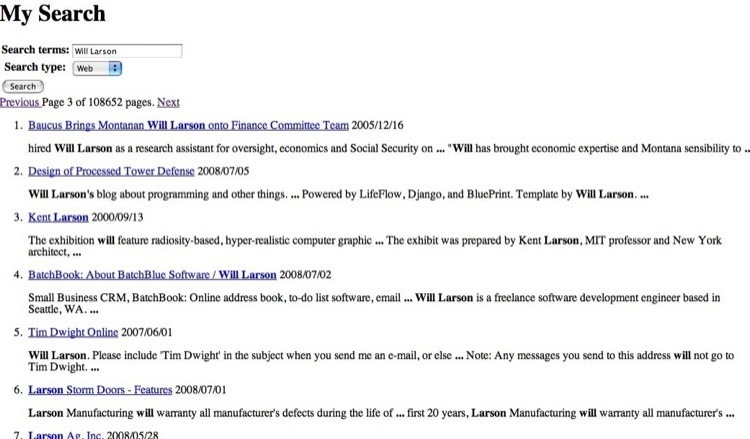
Pretty neat, wouldn't ya say? Hopefully this tutorial has been helpful, and let me know if you have any questions.
The Python documentation makes it pretty clear that
__getslice__is deprecated, but how to handle a 'slice object' as the documentation suggests is entirely unclear. As such, I am doing this the quick and easy way, while acknowledging it apparently isn't the preferable way to do so.↩Certainly implementing a fuller implementation that allows seamless access to the entire search result set would be a fun exercise, and if I have a bit of time I'll try to throw it together.↩