Providing pierceable abstractions.
Fail open and layer policy is a design principle for infrastructure, which emphasizes building flexible systems with a decoupled policy enforcement layer constraining usage. For example, building a Dockerfile based deployment system which can accept any Dockerfile, and then adding a validation step which only allows a certain set of base images.
This approach gets even more powerful when applied across a suite of solutions, as it allows you to reduce the flexibility in a particular platform while preserving user flexibility.
Imagine you’re running an “orchestration” team who is responsible for helping engineers at your company deploy and run their software. Your very first offering might be granting teams access to a server or VM. This works well, and is immensely flexible.
As the company you support grows, some of your users will start to ask if you can reduce the burden of managing individual servers for them (especially those running stateless applications). If you love your users, which of course you do, then eventually you find the time to roll out a service orchestration framework, say Kubernetes or Aurora, abstracting your users from individual server failures.
Later on, you may even get someone who “just wants to run a function” (well, you’ll definitely get people who want this on behalf of others, I’ve had fewer ask for this for themselves), and doesn’t even care about the transient state and dependency management provided by the service abstraction, leading you to roll out a lambda (in the AWS Lambda or Google Cloud Functions sense) platform.
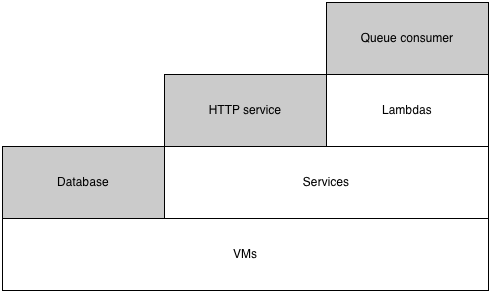
This layering effect allows platform builders to build opinionated infrastructure, while empowering their users to make the tradeoff between taking on more accidental complexity versus gaining the degree of control they want for their specific project. If you need persistent local disk storage, go ahead and pierce all the way down to the VM layer, but you’ll avoid a lot of accidental complexity if you can just use a stateless service.
This is a pretty obvious approach, look at the various cloud providers, but I think we often forget it when operating internally, and end up building overly opinionated solutions that age poorly (easily by not solving enough of users’ needs, or by taking on so many features that they become unmaintainable). Aging well is critical to quality infrastructure, because each system that is aging poorly reduces our ability to invest towards the future.
Some circumstances reasonably preclude building good infrastructure but when you do get the chance, build layers which compose together into a complete solution, rather than trying to have any given layer do everything for everyone.
A few more examples where you could apply this approach:
Storage. You might want to offer an eventually consistent key-value store which supports active-active replication across many regions, and then provide another offering which is strongly consistent but with reduced replication or availability properties.
Load balancing. 90% of applications can get away with very naive round-robin load balancing, and 90% of the remaining 10% can get away with least-conn based routing, but a few need something more bespoke (hashing on a key for increased data locality, etc). By decoupling the control and data plane, you can allow the vast majority of applications to use the load balancer directly, but allow the edge cases to directly communicate with the control plane and implement routing themselves.