Writing a reliability strategy: reason about complex things with system models.
A while ago I wrote about modeling a hiring funnel as an example of creating a system model, but that post doesn’t explore how the process of evolving a system model can be helpful.
As I find is often the case, inspiration came from my current work. We’re doing an annual strategy refresh on how we’ll approach security, reliability and such, and incorporating modeling into developing these strategies has been a surprisingly effective brainstorming tool.
Let’s use reliability as a specific example of how this approach works.
Infinite acknowledgements are due to my coworkers Taleena and Davin, among many others, for their insight and work on our understanding and approach to reliability.
Problem statement
We want to write a strategy describing our approach to reliability. The strategy document should convincingly answer four questions:
- What is the current state of reality? This is pulling in data and context to ensure that our approach accounts for our real needs and challenges. This also includes our targets.
- What are the guiding principles we’ll use to address the current state?
- What actions would those guiding principles direct us to take to address the current state?
- What actions are we actually going to take, considering our planning commitments?
Even if you’ve been working on this problem and at your current company for years, those questions can be difficult to answer concisely. Nor does it necessarily get easier if the products and infrastructure you support are scaling rapidly.
This is where systems modeling comes in.
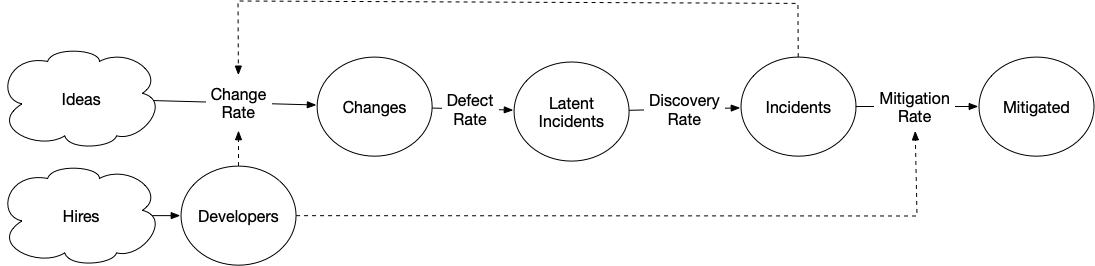
The following system models will be defined using the systems
library I wrote last year. Hopefully the syntax is readable, and the diagrams
have most of the details. The only caveat I’d mention is that flows, the bit following @,
are either rates or conversions.
Rates transfer from an input stock to an output stock, and are represented by integers or formulas. Conversions multiply the input stock by a conversion factor, add the result to the output stock, and empty the input stock. Conversions are represented by decimals.
See the code on Github, and interact with it on Binder.
Creating data about incidents
One place to start our reliability model might be from the perspective of incidents. Changes occur all the time in our software, some of which we control like deploying a new version, and many which we do not, such as hardware failures, discoveries of new vulnerabilities and so on.

Most changes go well, but some do not. When a change goes poorly, it sometimes becomes an incident. Each incident is an event where we miss our reliability goals, and once we’ve returned to meeting our reliability goals, we’ve mitigated the incident.
Starting with something very simple, let’s imagine that there is a fixed rate of changes becoming incidents, and a fixed rate of mitigating incidents:
[Changes] > Incidents @ 2
Incidents > Mitigated @ 1
In this model, we’d slowly accumulate more and more incidents, and the number of open incidents would consistently be higher than the number of lifetime mitigated incidents. Terrifying.
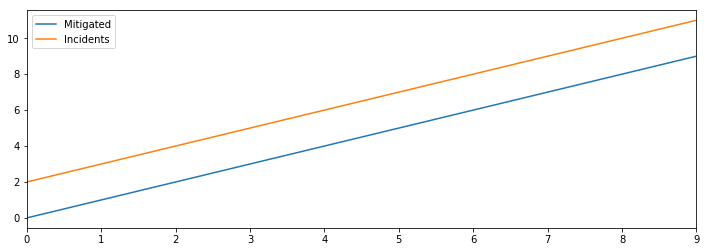
This is a very basic model, but I think there are still some useful things to learn even from it. For example:
- There are quite a few things we need to instrument and measure to understand our reliability. We need to measure the number of changes, incidents and remediations. If we can measure those precisely, then we can also find the real rates that our system is converting change into incidents and incidents into mitigated incidents.
- We don’t have any (acknowledged) feedback loops from incidents to changes, without which we’d expect to see number of unmitigated incidents grow over time.
- The rate at which we mitigate incidents seems like the most important flow in the overall system, particularly if we don’t want to reduce the rate of change, as most businesses depend on increasing the rate of change.
Already, this simple model has informed what the strategy document will need to be useful. In particular, it will highlight why an incident program is a prerequisite to managing your reliability: it’s the only way to get the data you need to have a fact-driven conversation about what is or isn’t working.
If you haven’t established something along those lines, my advice would be to stop reading, spend the next year establishing and running it, and come back once you have data. While how to establish an incident program is probably outside of what I can cover here, Tammy Butow’s post is an excellent introduction.
Developers change things
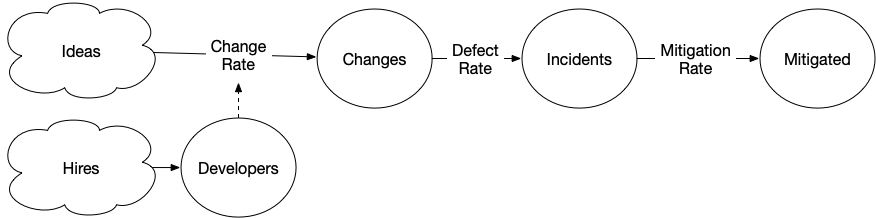
One weakness in the previous model, is that the number of incidents is probably not a fixed rate, but rather depends on the number of changes. The number of changes probably depends on your number of developers, and at a growing company that number is often going up.
[Hires] > Developers @ 1
[Plans] > Changes @ Developers * 2
Changes > Incidents @ 0.2
Incidents > Mitigated @ 1
This is where our lack of a feedback loop from unmitigated incidents to changes gets quite scary, as we can see the number of incidents growing rapidly over time, overtaking the rate of change.
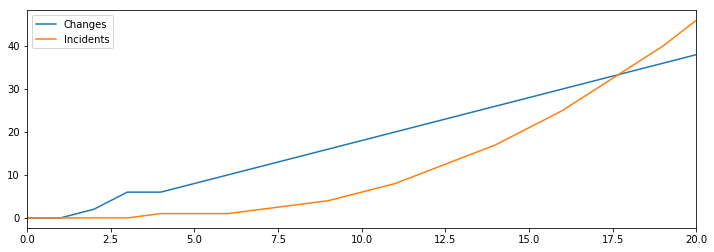
However, if you’ve worked at a company with many incidents, you know this isn’t quite what happens. As the number of incidents goes up, the rate of product changes goes down, as folks shift focus to work on remediations.
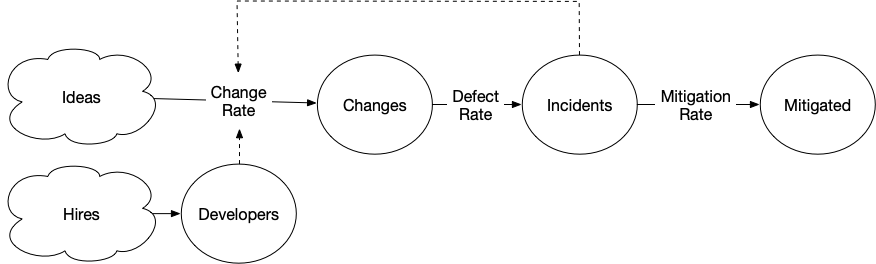
This is the feedback loop we’ve been looking for.
[Hires] > Developers @ 1
[Plans] > Changes @ (Developers * 2) - Incidents
Changes > Incidents @ 0.2
Incidents > Mitigated @ 1
If we model that dynamic as the flow from plans to changes being decreased by the number of open incidents, we find something surprising.
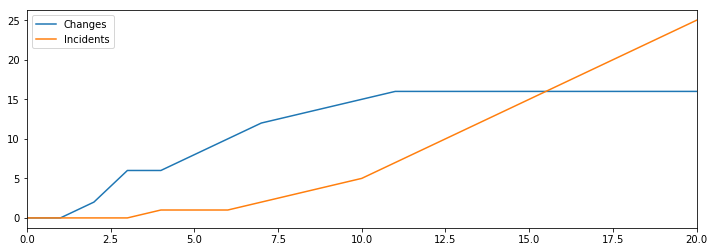
If we keep hiring more developers but don’t increase our capacity to mitigate incidents, then we’ll fairly quickly reach a point where additional hiring doesn’t allow us to make more changes.
This result leads us to an important guiding principle for our reliability strategy: hiring only increases productivity if we make equal improvements in our ability to mitigate incidents.
An aside: counter feedback loops
There is always a question of how detailed you want to make your model, and it’s worth noting that mitigation-inspired changes have a defect rate of their own as well. As such, it’s not entirely uncommon for incidents to spawn new incidents due to defective mitigation attempts, which becomes a counter feedback loop working against the feedback loop we just modeled.
I’ve chosen not to model this aspect, but it’s quite possible for your current situation that this bit is very important. Deciding what to model and what to leave out comes down to data-driven judgement, and effective reliability models at two different companies will include and omit different aspects.
Increasing mitigation bandwidth
Now that we’ve identified incidents as the constraint on both our reliability and productivity, let’s build out our model around reducing incidents. While a successful mitigation resolves an open incident, they typically don’t do much to prevent future incidents. Remediations eliminate categories of potential incidents, and we’ll need to model our capacity to both mitigate and remediate to understand our options for reducing open incidents.
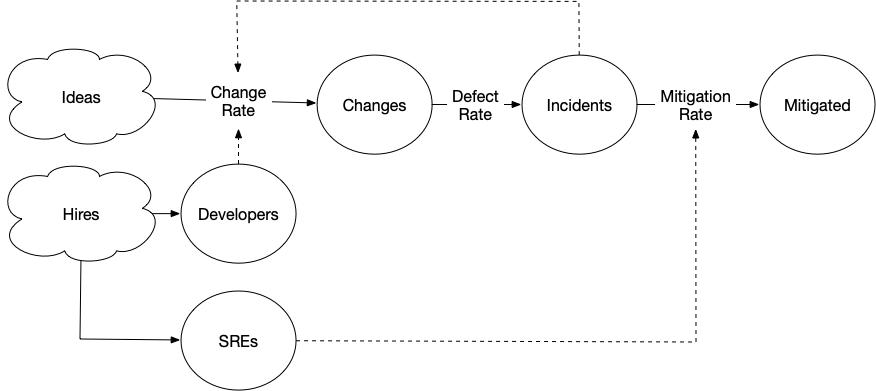
One strategy that many companies take is to introduce an SRE role that focuses on mitigating incidents. Let’s imagine that we hire one SRE for every five engineers, and then each SRE can manage two incidents.
[Hires] > Developers @ 5
[Hires] > SREs @ 1
[Plans] > Changes @ (Developers-Incidents) * 2
Changes > Incidents @ 0.2
Incidents > Mitigated @ SREs * 2
Hiring a one to five ratio of SREs to developers is quite high, but it seems like this should really fix things!
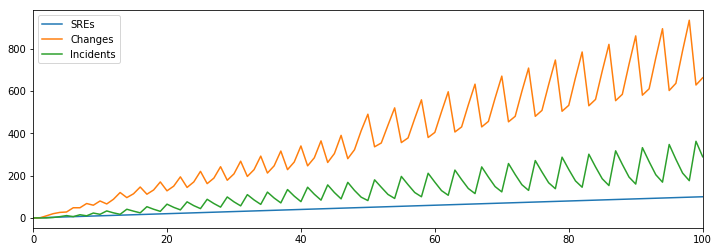
Interestingly, it does actually fix half the problem. We’ve avoided our previous change rate plateau, continuing to make more changes as we hire more developers, so our productivity is back on the rise. Unfortunately, our open incidents are still increasing as well, albeit at a much reduced rate. Hiring folks to mitigate incidents doesn’t seem to be a sufficient answer to our challenge.
Next let’s model in doing remediation work that reduces our defect rate, e.g. the rate at which changes lead to incidents. Here we model doing one remediation per round, and reduce defect rate as we do more remediations.
[Hires] > Developers @ 5
[Hires] > SREs @ 1
[Plans] > Changes @ (Developers-Incidents) * 2
Changes > Incidents @ Conversion(1 / (1 + Remediated))
Incidents > Mitigated @ SREs * 2
Mitigated > Remediated @ 1
All of the sudden, we’re back in business, and are able to maintain a bounded number of incidents despite continuing to make more and more changes.
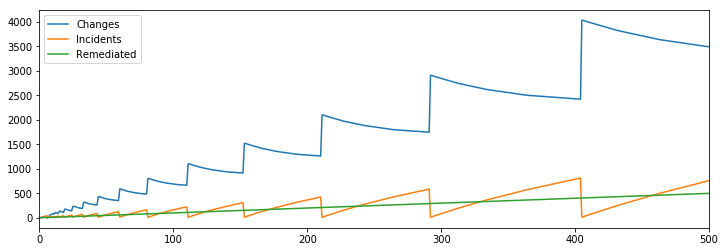
Given that we’ve been able to get the desired outcome with additional remediations, I wondered if we could actually remove the entire SRE aspect of the model and get to the same result while leaving our mitigation rate at one per round.
[Hires] > Developers @ 5
[Plans] > Changes @ (Developers-Incidents) * 2
Changes > Incidents @ Conversion(1 / (1 + Remediated))
Incidents > Mitigated @ 1
Mitigated > Remediated @ 1
That didn’t quite work, but interestingly even a very small fixed number of mitigations and remediations make it possible to benefit from increased hiring, which I find to be a surprising result.
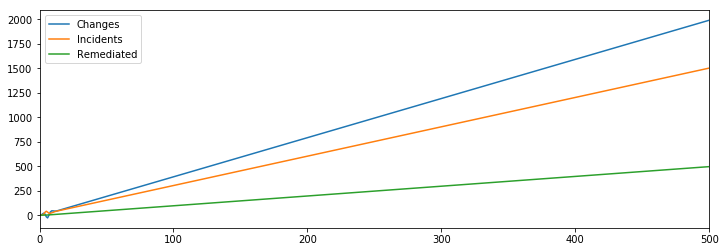
If we’re willing to make a small change though, saying that say every hundred engineers allow us to mitigate one additional incident, which doesn’t seem unreasonable given the model has pulled them away from making changes during incidents, then it turns out even that very small change fixes our reliability challenges.
[Hires] > Developers @ 5
[Plans] > Changes @ (Developers-Incidents) * 2
Changes > Incidents @ Conversion(1 / (1 + Remediated))
Incidents > Mitigated @ Rate(1 + (Developers / 100))
Mitigated > Remediated @ 1
Which allows continued improvement and a fixed number of incidents.
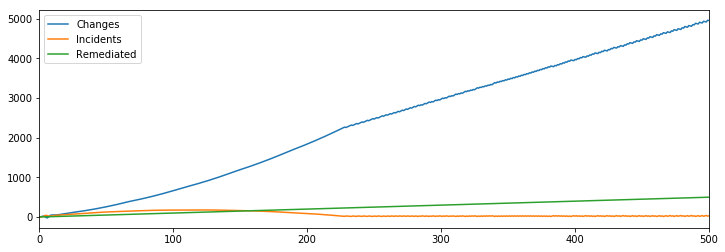
This is a very powerful result in my mind, as it implies a very small fixed investment into remediations will, in the steady state, support a reliable and productive environment if you can modestly scale your mitigation capabilities.
Reflecting on guiding principles we’d take away from this, the two that come to mind for me are ensuring we always have some investment into remediations that cannot be pulled away, and that a fixed-size mitigation model won’t work. We can’t simply hire an eight person SRE team that will handle all mitigations, and treat that as a solve. Conversely, we could accomplish our goals if we designed an SRE organization that is of a fixed relative size to the overall engineering, say one to twenty, that focused solely on mitigations.
It would be even more effective if they focused on mitigations and remediations, but interestingly it’s increased mitigation bandwidth that matters the most in the model, not increased remediations. If we hold mitigation bandwidth constant but scale up remediations, which sounds more effective, we get a somewhat unintuitive result.
[Hires] > Developers @ 5
[Plans] > Changes @ (Developers-Incidents) * 2
Changes > Incidents @ Conversion(1 / (1 + Remediated))
Incidents > Mitigated @ 1
Mitigated > Remediated @ Rate(1 + (Developers / 100))
This actually doesn’t accomplish our reliability goals.
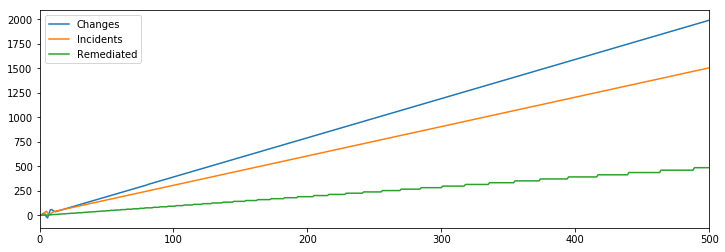
This is because each remediation prevents many future incidents, which makes them very leveraged in a fixed amount, but less leveraged at high volume. Conversely, mitigations are not very leveraged but remain necessary at any volume.
Latent incidents
One of the core observations of systems thinking is that often effective solutions don’t initially work because they are draining a large initial stock. This is often true around reliability efforts, where folks are concerned about reliability, and start instrumenting incidents, and a quarter later find they are having even more incidents.

This maddening experience is often the result of what I like to call latent incidents. These are problems waiting to happen, introduced by previous changes but which haven’t triggered the necessary edge cases to become a true incident. Folks starting a reliability program usually have a very large, invisible stock of latent incidents, and draining that stock often creates the impression that an effective reliability program is failing.
[Hires] > Developers(10) @ 5
[Plans] > Changes @ (Developers-Incidents) * 2
Changes > Latent(1000) @ Conversion(1 / (1 + Remediated))
Latent > Incidents @ 10
Incidents > Mitigated @ Rate(1 + (Developers / 100))
Mitigated > Remediated @ 1
Specifically, if we model a large stock of one thousand latent changes, then the initial data will reflect that we’re getting less reliable, and it’s only once the stock is drained that we’re able to stabilize reliability and productivity.
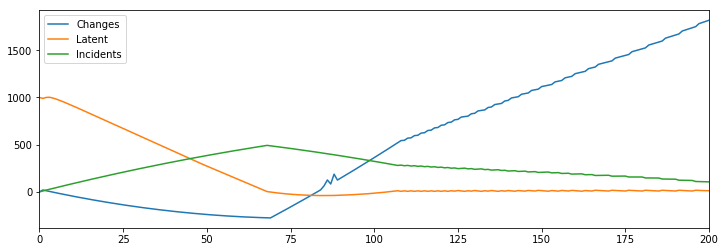
With this in mind, we’ll want our guiding principles to include measures to either reduce or at least measure latent incidents in our environments, or we’ll make inaccurate assessments of stability.
Some of the approaches that might work here are fault injection techniques from chaos engineering, integration testing, and so on.
And on it goes
This is just the beginning of ways to evolve a reliability model to help create a focused, effective strategy. A few ways you might imagine continuing to extend this model are:
- How does time to detect incidents contribute to time to mitigate?
- How do failed mitigation attempts create more incidents or reduce mitigation rate?
- How does training your engineers impact defect rate?
It’s not all about extending the model though, it’s also about using the model to prioritize your actions based on what will actually help. We can talk abstractly about how more remediations reduce the defect rate of future changes, but in reality there is probably one specific remediation that would reduce your future defect rate by 90%, and to identify it you have to review the root causes of your most frequent incidents.
The subtle power of modeling is that it makes it inexpensive to imagine a number of futures, and provides some light guidance in which are most likely to accomplish your goals. Next time you’re working on a particularly difficult problem, try evolving a simple model as a tool for steering your attention and evaluating your options.
They can be great for brainstorms as well, in particular to identify which pieces of information are important to know before picking your approach.
Some code from this exploration is on GitHub, which you can interact with on Binder.