Developing service oriented architectures.
After spending the last four years rolling out and maintaining service oriented architectures, it’s my hope that I’ve accumulated enough scars on the topic to approximate wisdom. This is an attempt to share some useful tidbits.
First I’ll briefly describe the two different SOAs I’ve been working on to provide some context, and then launch into the lessons I’ve learned and observations I’ve made.
Digg
At Digg our SOA consisted of many Python backend services communicating with each other as well as being used by our PHP frontend servers and Tornado API servers. They used Apache Thrift for defining the interfaces, clients and as the underlying protocol. We had three major services (user, story, comment), and a handful of smaller ones.
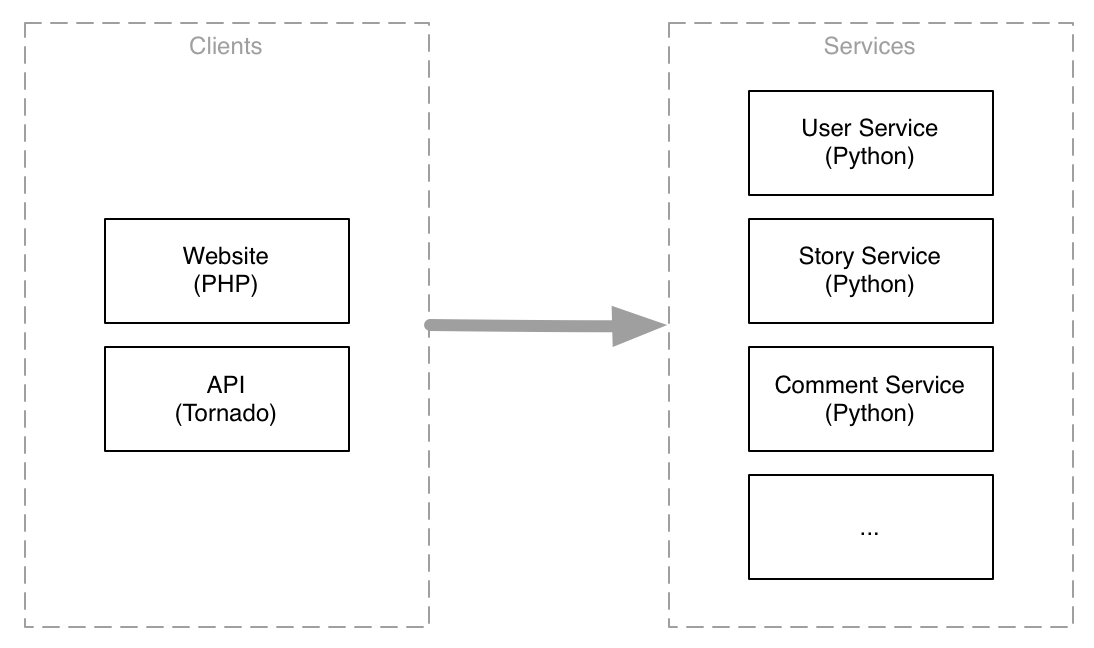
All backend services were hosted on one class of machine–frontend servers were a separate class–and all backend services were deployed in unison from a single Git repository.
SocialCode
Coming off the Digg SOA experience, we changed up a few things when it came to building the SOA at SocialCode. Backend services and APIs stayed in Python but rather than using Thrift we chose HTTP as the protocol, and we implemented the frontend products as JavaScript applications which communicated directly with the HTTP APIs, making the browser a native API client.
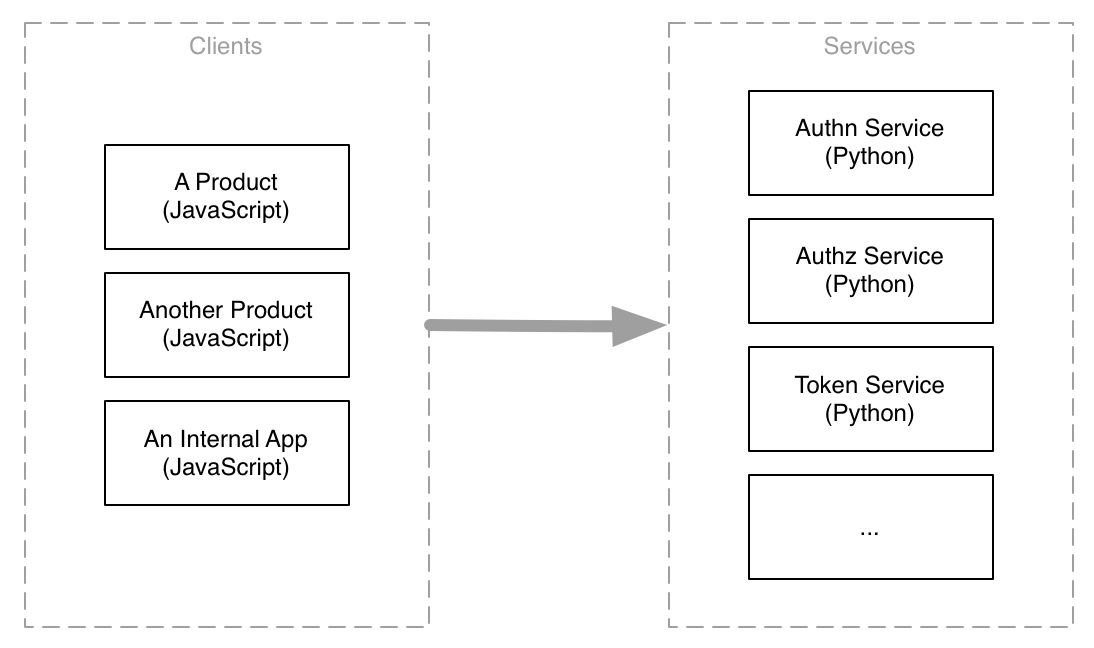
APIs are isolated to their own servers for decoupled debugging and scaling, have independent code bases, and are deployed individually.
With these two different approaches in mind, it’s time to work through the lessons learned through the development and maintenance of these systems:
SOAs are for scaling people
SOAs are not a panacea, rather they significantly complicate your architecture. Nor are they fundamentally a high performance architecture, they impede performance by adding more parts.
Essentially the only value they provide is an abstraction for large teams to work together effectively through two mechanisms: defined interfaces reduce communication and breakage costs, and hiding internals behind those interfaces makes it possible to incrementally invest into quality without any additional cross-team coordination (you can rewrite the internals for various improvements without impacting API clients as long as you don’t change the interfaces).
These advantages move mountains with large teams.
They don’t necessarily provide a lot of value for very small teams. My gut feel is that small teams seeing massive performance wins from moving to a SOA could probably have gotten those same wins through any system rewrite/overhaul, and that the SOA is a bit of a red herring.
Adopting a SOA is slow
If you shouldn’t immediately start with an SOA, then how do you move over to an SOA? The answer is “slowly and with great care.” You’ll either be moving over during a full rewrite–in which case, good luck!–or you’ll be incrementally transitioning from your existing monolithic architecture.
If you’re running a successful, growing company that requires splitting time between building out new features and infrastructure investment, then incremental migration is a likely strategy.
Start by adding simple and uncontroversial services, like a user identity and authentication service, and roll each service out to all your applications before adding another. Then add another, and another until you’ve reached the desired consistency. (Which might only be a couple of services early on. Don’t be afraid to go slowly.)
An interesting pattern to consider during migration is creating the new service API but having it share the existing database, allowing existing clients to migrate over to the new API incrementally. Once they’re fully on the new API (which is still using the same old database), then you can migrate off to an independent database. Especially if you’re dealing with four or five different teams with different development schedules, this technique can help you avoid data inconsistencies during a prolonged cutover.
Protocol matters
One of the most important decisions we made from Digg to SocialCode was switching from the Thrift protocol to HTTP. This allowed the browser to be a native client which uses the APIs directly, but more than that it also made debugging and experimentation easier because most software developers are extremely comfortable with HTTP and HTTP servers, whereas relatively few are comfortable with Thrift. (This also extends to reusing their existing expertise for optimizing and debugging web servers and requests.)
On the flip side, Thrift is extremely self-documenting, which can make it more pleasant to work with than many HTTP APIs (we’ve used tastypie to create consistent APIs, which has been phenomenal, but its APIs and datastructures are still more implicit and magical than comparable APIs built using Thrift).
Depending on the language you’re using, you’ll get different performance-per-hour-spent-optimizing between Thrift and HTTP. For Python I found it easier to get high performance using HTTP, simply because the ecosystem is extremely robust and the Python Thrift servers hadn’t seen nearly as much community investment into their performance. Conversely, I could easily imagine for more robust Thrift implementations, like probably the Java implementation, that the inherent compactness of the Thrift protocol would facilitate superior performance over HTTP.
The last element to consider is that even with HTTP you don’t get browser support for free. Rather, if you want to allow web browsers to access your APIs directly, then every single API endpoint will need to implement request authentication and authorization mechanisms. This is very doable (anecdote: we’re doing it), but takes some time and consideration versus offloading authn and authz to an authorization layer (at Digg this was our PHP and Tornado services which auth(n|z)ed the requests and then acted as trusted users of our internal APIs).
Dumb API clients, smart API clients
Hot on the heels of picking your SOA’s protocol is deciding the kind of API clients you’ll use for interacting with your APIs. Broadly, there is a tradeoff between using sophisticated clients which hide as much complexity as possible (buying ease of use at the loss of control or awareness) versus dumb clients which expose all the ugly details of the underlying API (control and awareness at expense of “normal case” implementation speed).
Personally, I’m a strong proponent of dumb API clients.
I believe smart clients encourage engineers to treat a SOA as a monolithic application, and that’s a leaky abstraction. For our current setup, each API request we perform–even within the same colocation–imposes about a 20ms cost simply for uWSGI to service the request (plus any additional time to perform logic or lookups within the API itself).
That’s a lot of overhead to abstract away.
If you and your team are experienced working with SOAs, then by all means use a smart client, but if you’re not then I tend to believe it’s important to be exposed to the underlying implementation costs until you can build a mental cost model for the new development style.
Cross-team hotspots are bad services
If your organization manages system architecture more through voluntary collaboration and evangelism than fiat, then the easiest way to prevent service adoption is creating a service which unifies a capability which several teams are actively implementing.
On first reflection, this seems obviously wrong: of course you should avoid writing the same component twice.
In practice though, if multiple teams are already implementing similar functionality and are committed to a schedule, then it’s probably too late to try to unify implementations without forcing one or both teams to discard their project’s schedule or design. After the various implementations are stable, then it’s a good time to use those as concrete requirements for building a shared service.
File this one under “getting to the destination faster by avoiding fruitless debate.”
Altogether, I believe moving to a service oriented architecture is an important phase of scaling your engineering team from approximately five to twenty. It probably also coincides with the transition from finding a product-market fit and scaling out the fitted business.
A few things I’ve been pondering a bit while writing this:
- What are other ways to efficiently scale your engineering team?
- What other important advice is there for creating an excellent SOA? Measurement and monitoring are probably a good topic to explore.
What else did I miss?