Infrastructure between cost center and ego trip
I recently asked an engineering manager candidate why she was considering leaving her current job, and she said something unfortunately relatable: her infrastructure engineering team had a great deal of work left to do, but no headcount available to do it.
Such is infrastructure as a cost center.
On the other hand, at quickly growing companies, I’ve also seen infrastructure teams become befuddled about their priorities and staff multiple, competing teams with the same goals. Or worse, staffing competing solutions to one problem, while not staffing their most urgent work at all. In such circumstances, critical production systems continue crashing, surrounded by heavily staffed glamour projects with unclear goals.
Such is the ego trip of infrastructure.
Although the perils of both extremes are fairly clear, finding a grounded thinking framework for prioritizing infrastructure remains challenging. Sufficiently challenging, that over time I’ve put together a thinking aid to help me prioritize incoming requests and determine which projects I should proactively initiate myself.
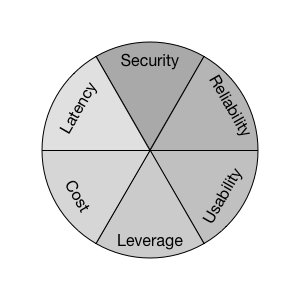
Intended usage is to think through your current offering, incoming feature requests and potential capabilities: for each, look for opportunities across each of these six dimensions. These are presented in loose priority ordering, although certainly your priorities likely aren’t exactly mine.
Infrastructure offers these six major features to company and client:
- Security is more than “locking things down”, it’s streamlining such that the same tasks can be accomplished more securely with the same level of effort. (BeyondCorp and Security Keys are nice reads if you’re looking for inspiration!)
- Reliability is more than uptime, harvest or yield, but also hardening your interfaces, and ensuring your oncall load is low enough that alerts are actioned instead of ignored.
- Usability is making your software easy to use correctly. If it takes twenty steps to provision a new service, how can you make it only take twelve? If creating an S3 bucket requires an approval, can you at least automatically preapprove a few common cases? If people consistently misunderstand your documentation or how to debug your system, how can you make it more intuitive? If engineers have to recite an incantation to deploy safely, how can you add safety bumpers to make doing it the right way easier than doing it the wrong way?
- Leverage is making the engineers on and off your team more productive by making your primitives and abstractions more potent (some would argue function-oriented computing is such an improvement over service-oriented computing), or by offering entirely new capabilities (for example, offering a task or batch processing system).
- Cost is offering your service for less. This can be reducing maintenance overhead to spend more time on features, and it can also be better picking of more appropriate AWS or GCP instances. At Stripe, we’ve been driving cost management as an infrastructure feature–sponsored by infrastructure engineering, as opposed to a financial initiative–and it’s been pretty exciting to see what Aditya, Cory and Davin have done to turn this into an enabling feature. (Relatedly, a bewildering post about cost as a cornerstone feature.)
- Latency is both reducing time to reach your servers (through points of presence, an active-active multi-region/datacenter topology, or connection pooling with established connections), and also time within your stack (via better load balancing strategies, request tracing to find latency hot spots, optimizing database queries).
This is certainly not a comprehensive framework, but I have found it to be quite useful during planning sessions. In particular, I find it useful for avoiding some of the frequent mistakes made by infrastructure engineering teams:
- Absconding responsibility for security to a much smaller Security team, when they themselves are building most of the platforms that need to be secure.
- Assuming that usability of infrastructure isn’t important because their users are engineers. This isn’t true: even engineers obey the laws of distraction, typos and time. Worse, it’s more common for internal users to churn off a platform because of usability than because of legitimate feature gaps (how many times have you been told that it “actually, is possible” to do X task on Y platform, and then heard a complicated work around?), so lack of investment here tends to cause significant–and in my opinion often mistaken–pressure to build new platforms.
- Prioritizing glamorous–and typically complex– projects which happen to solve a problem (a solution seeking a problem), rather than taking the direct path to addressing the problem at hand.
- Accepting the current status quo as good enough, and languishing with a decent system instead of continuing to push towards something phenomenal.
- Delegating cost awareness to another organization that doesn’t have insight into how your systems actually work, forcing that organization to try to drive cost reductions without enough context to do it well.
- (It turns out there are a lot of frequent mistakes.)
By systematically thinking through the six features during planning, I find it’s harder for me to fall into those alluring mental traps.
I’ve been using a loose approximation of this for the past six months or so, and have been pretty happy with it, although only in writing this post was I able to tease apart the nuance between usability and leverage, and I’ll undoubtedly keep iterating on it indefinitely. Do you use anything similar? How do you avoid falling into the common traps of infrastructure planning?