Incident response, programs and you(r startup).
During an incident at Digg, a coworker once quipped, “We serve funny cat pictures, who cares if we’re down for a little while?” If that’s your attitude towards reliability, then you probably don’t need to formalize handling incidents, but if you believe what you’re doing matters – and maybe today’s a good time to start planning how to walk out that door if you don’t – then at some point your company is going to have to become predictably reliable.
Having worked with a number of companies as they transition from heroic reliability to nonchalant reliability, there are a handful of transitions that can take years to navigate, but can also go much faster. Forewarning streamlines the timeline, skipping the frustration.
This friction stems from the demands on incident programs shifting as a company scales. They start out with an emphasis on effectively responding to incidents, but with growth they become increasingly responsible for defining the structure and rationale of the company’s investment into reliability. If you haven’t previously navigated these shifts, it can be bewildering to see what worked so well early on become the source of ire.
Here are my tips to fast-forward past the frustration.
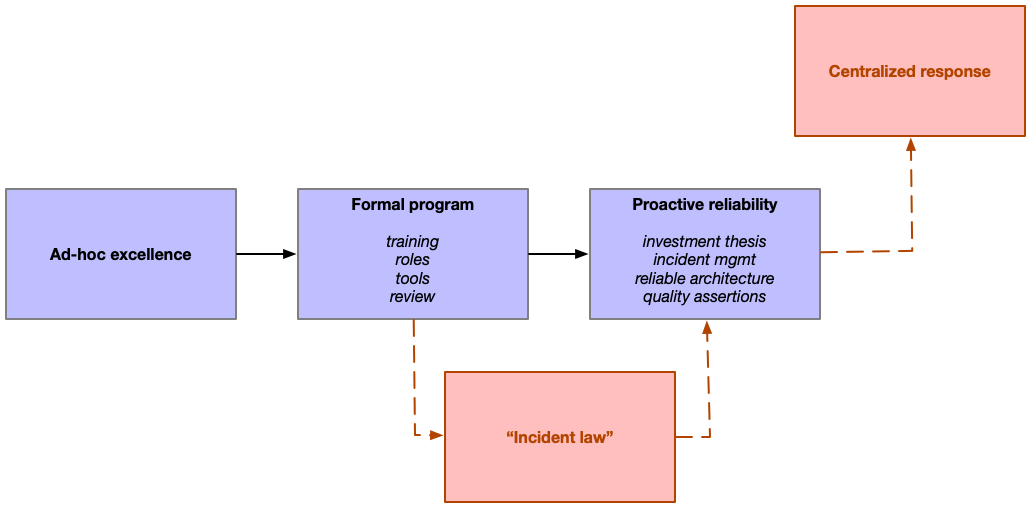
Ad-hoc excellence
Even the smallest companies ought to have an on-call rotation powered by a tool like PagerDuty. A pageable rotation is the starting point for incident response. In the best case, some sort of monitoring triggers an alert; in the slightly worse case, a human – often a human reading support tickets – will learn about a problem and automatically trigger an incident. In either case, that alert triggers a shared on-call rotation for the entire company, and folks leap into mitigation.
This approach works well in a company with a small surface area, as every engineer is familiar enough with the software that having a shared rotation still leads to effective response. It starts to fray as the company scales, where only an increasingly small pool of long-tenured engineers understand enough of the stack to respond to complex incidents.
This overreliance on a small, tenured group leads to resentment both directions. Long-tenured folks feel put upon and unsupported by the newer team, and newer folks feel like they’re not being given space to contribute. You’ll often start splitting into multiple on-call rotations for areas with clear interfaces and isolation, but most early codebases follow the big ball of mud pattern and resist decomposition.
Dependence on the long-tenured cohort becomes untenable as the company keeps growing, which eventually leads to the transition from this ad-hoc approach to a more structured system that promises to effectively incorporate more folks into incident response. By the time you reach two hundred engineers, it’s definitely time to make the next step, but even very small companies will benefit from abandoning the ad-hoc to the extent that they’re providing a critical service.
Formal program
Adopting a formal incident program doesn’t require a huge amount of process, but it certainly requires more process than the ad-hoc reimagination of incident response that previously occurred at the beginning of each incident. This can be challenging as early startups tend to equate structure and inefficiency.
The structure-is-inefficient mindset is particularly challenging in this case because the transition from “excellence in ad-hoc response” to “excellence in structured response” is hard. Hard enough that you’ll initially get significantly worse at response.
Consequently, the first step in this transition is building awareness that it’s going to get worse before it gets better. It’s going to get worse, but the alternative is that it stays bad, and in a short while you careen over a cliff as the long-tenured team you’re depending on revolts. There is simply no way for a small team of long-tenured engineers to support a company through continued rapid growth, and every company must make this transition.
Once you’ve built awareness that it’s going to be a rocky switch, you can start laying the foundation of a durable, scalable incident program. This program will be responsible for both responding to incidents as they happen (incident response), but also the full lifecycle of incidents from detection to mitigation (reducing or eliminating the user impact) to remediation (reducing or eliminating the impact of a repeat incident).
The pillars of your initial incident program rollout are:
- Incident training ensures every engineer goes through training on how incident response is handled, allowing them to learn the standardized approach. Equally important, ensure every employee goes through training on how to open an incident.
- Incident tooling to streamline opening and responding to incidents, as well as supporting the creation of a high-quality incident dataset. Early on you can conflate alerts with incidents, but as your systems’ complexity scales, you’ll have far more alerts than incidents, and some incidents that don’t trigger any alerts. Blameless is quite similar to the internal tooling most companies end up building.
- Incident roles define concrete roles during incidents, such as the incident commander, to create a clear separation of concerns between folks mitigating and folks coordinating. It also streamlines getting access to folks to fill each role for a given incident, for example an on-call rotation of incident commanders, an on-call rotation for folks who can do external communication during incidents, and so on.
- Incident review supports learning from every incident by authoring and discussing incident reports. I’ve found it best to review individual incidents in on-demand meetings that include folks with the most context (and time to think!), and use recurring meetings to review batches of similar incidents to extract broader learnings. (As an aside, I think there is a bit of a low-key industry crisis around whether typical approaches to incident review are actually very valuable. If you were to find one place to innovate instead of replicate, this might be it.)
Many companies roll out those components through a project working group, which works well for the first version, but excellence comes from iteratively adapting your approach to your company and systems. That sort of ongoing iteration works best with dedicated teams, which is why the companies that navigate this transition most effectively do so with an incident tooling team and an incident program manager.
The incident tooling team is responsible for building incident tooling, treating it as a critical product with workflows, and with the understanding that folks exclusively use their product while under duress. This team’s continued investment into tooling lowers the mental overhead for incident responders, allowing you to rely less on training as you scale, and more on tools that steer towards the right decisions.
The incident program manager coordinates the day-to-day and meta components of the incident program, studying how well the process is working for teams, and evolving it to better suit. They look at how the pieces fit together and align it with other organizational processes to ensure it works in harmony with the broader company systems.
If you roll out all of these pieces, you can likely get to about five hundred engineers before you run into the next challenge: the emergence of incident lawyers.
Incident law
Incidents are very stressful, and often prompt difficult questions like, “Why are we having so many incidents?” Often folks take that question to the team working on the incident program and tooling, curious to understand what they need to prevent more – or perhaps all – incidents. It’s quite common for the teams working on incidents to reply that what they need is compliance to the existing process: the system works, if only folks would follow it.
This leads to a phase of incident programs that I think of as the emergence of incident law, facilitated by a cohort of strict incident lawyers, who become so focused on executing the existing process that they lose track of whether the process works.
When you put too much pressure on any process or team, they start to double down on doing more of what they’re doing as opposed to changing what they’re doing to a new approach that might be more effective. This doubling down during duress traps many incident programs, shifting their full focus towards compliance with the existing process. If you don’t file your tickets on time, you get a strict follow up. If your incident report is missing details, you get a harsh reminder. Over time, the rift between the folks who design incident process and folks who follow incident process begins to widen.
Although I’m extremely sympathetic to folks who end up in the role of driving compliance, it’s misguided in the case of incident response. There is an asymmetry in exposure between the folks designing and following incident process.
The folks designing the process are deep in the details, looking at dozens of incident reports each week and drilling into the process gaps that hampered response. Conversely, the folks following incident response generally experience so few incidents that each incident feels like learning the process from scratch (because the process and tooling has often shifted since their last, infrequent, incident), and they bring good intent but little familiarity to the process. It simply isn’t practical to assume folks who rarely perform a frequently changing process will perform it with mastery, instead you have to assume that they’ll respond as experts on their own code but amateurs at the incident process itself.
The path out of this quagmire is switching mentality from owning a process to instead owning a product. Rather than setting goals around ticket completion rates, instead set goals around usability of your workflows. This is only possible with a dedicated engineering team with both a product and a reliability mindset working on tooling, along with an incident program management team who can bring accurate data and user voice into that product to ensure it’s effective.
Until you make the process to product evolution, you’ll increasingly focus on measures of compliance, which are linked to reliability by definition rather than by results.
As important as it is to escape this “form over function” approach, it’s not quite enough on its own. You also need to evolve from reactively investing in reliability to an approach that supports proactive investment. Unlike the previous phases, there is no organization size threshold you need to reach before you can leave incident law behind you, rather escaping these legalities is a matter of changing your perspective: sooner is much better than later.
Advocates of centralized incident response will note that you can have incident responders with mastery in the process by creating a centralized incident response or reliability engineering organization who respond to all (critical?) incidents. I’ll talk about this further down, but roughly my argument is (a) that is quite hard to do well at any scale, (b) it’s impossible to do well until your business lines start to mature, which isn’t yet the case for most 500 person engineering organizations undergoing hypergrowth.
Proactive reliability
Each incident is a gift of learning. From that learning, you’ll identify a bunch of work you could do to increase your reliability. Then you have another incident, and you learn more. You also identify more work. Then you have another incident and pretty soon there is far more work to be done then you’re able to commit resources towards. This often leads to the antipattern of identifying the same remediations for every incident. If the same remediations come up for every incident, doesn’t that mean they’re not useful remediation? Then why do we keep talking about them?
Any incident program operating at scale will generate more work than the organization can rationally resource at a given time. Reliability is a critical feature for your users, but it is not the _only _feature. As a result, you have to learn how to prioritize reliability work from a proactive perspective across all incidents, and to rely less on prioritizing reliability work reactively from a single-incident perspective.
There are four ingredients for doing this well: an investment thesis,_ incident management_,_ reliable architecture_, and_ quality assertions._
Your investment thesis is a structured set of goals and baselines (video version from SRECon) that you’ll use to determine the extent you should invest into reliability. This gives you a framework to tradeoff against other business priorities like feature development, market expansion, etc.
Incident management is reviewing incidents in bulk as opposed to individually. Understanding the trends in your incidents allows you to make improvements that prevent entire categories of issues rather than narrow one-off improvements. This allows you to shift from whackamole to creating technical leverage.
Reliable architecture is identifying the fundamental properties that make systems reliable and investing to bake those properties into the systems, workflows and tools that your engineers rely upon. This is the transition from asking folks to identify remediations a priori, to letting them benefit from your reliability team’s years of learning.
Quality assertions are an approach for maintaining a baseline of quality, allowing you to maintain important properties in your systems that make it possible to rely on common mitigation tools (e.g. to have confidence that requests are idempotent and it’s safe to shift traffic away from a failing node and reattempt it against a different node when canarying new code).
With all four of these techniques in play, you’re able to transition towards optimal reliability investments based on learnings from your entire cohort of incidents, and step away from treating each incident and remediation as equally important. You’re able to maximize reliability impact per engineering hour, and switch from the role of incident-chaser into the role of business partner making rational tradeoffs.
The language of process optimization simply doesn’t resonate with folks who don’t have a deep intuition around creating and operating reliable systems, which is why this transition is so important to make as your company grows to thousands of engineers. Many organizations never quite land this evolution, which is a shame, because reliability will never get the investment it needs until you’re speaking simultaneously in business impact and technical architecture.
Centralized mastery
Once you’ve guided your reliability efforts through these evolutions, you’ll find yourself at an interesting place. You’re making calculated investments into reliability that resonate with the business leaders. Your architecture channels systems towards predictable reliability. You have a healthy product powering incident response and review, that continues to evolve over time.
Things are looking good.
Many organizations choose to stop here, and personally I think it’s a rather good stopping place. Others decide that the financial or reputational impact of downtime is so extreme, that they want to continue reducing their time to mitigation by introducing a centralized team that performs incident response for critical systems as their core function rather than an auxiliary function. These teams, often called Site Reliability Engineering teams, become the line of first response for critical, mature systems.
The advantage of these teams is that they have enough repetition in incident response to develop mastery in the processes and tools. You no longer have to build incident response tools that are solely optimized for infrequent responders, but can instead expect a high level of consistency, practice and training. They’re also valuable for organizations which never created an incident tooling team to begin with, which often causes the impact of SRE teams and incident tooling teams to be conflated.
The downside of these teams are two fold. First, they often lack deep expertise in the systems they are managing, which can slow response to novel incidents (and in the long run of an effective incident program, the majority of incidents become novel). Second, they often create a release valve for accountability by the engineering teams building those products, as the feedback loop between implementing unreliable software and being accountable for unreliable software is dampened by the introduction of an additional team. These concerns are certainly fixable. For example, Google requires a minimum reliability threshold before their SRE teams take on the pager, but requires active management and support.
Expanding a bit on the first of those downsides, companies which are skilled at incident response focus their incident response on mitigating incidents rather than remediating incidents. It’s critical that the impact to your users or business is resolved, and if at all possible you’d much rather eliminate the impact before going through the steps to understand the contributing factors. As such, having a centralized team forces good hygiene as they’re less familiar with the code and rely more on standardized mitigation techniques like traffic shifting, circuit breaking and so on.
However, good incident programs use automation to mitigate known failure modes. This means if your program is working, the majority of your impactful incidents are novel. This means that centralized response teams are most effective within incident programs which aren’t working well. My perspective is that if your centralized team is highly effective in mitigating incidents, then it’s likely that your investment into remediating incidents is ineffective. Instead of investing into building out the response function, debug why you’re continuing to have repeat incidents and fix that.
Closing thoughts
The most important thing to keep in mind as you invest into reliability is to maintain an intentional balance between the many different perspectives that come into play. You should think of reliability from an organizational program perspective. You should think of it from an investment thesis perspective. You should think of it from the lens of code quality. You should think of it from a product perspective.
The only thing you must not do is to lean so heavily on any one perspective that you diminish the others. Keep an open mind, keep a broad set of skills on your team, and keep evolving: excellence is transient because good companies never stop changing.