How to invest in technical infrastructure.
I’m speaking at Velocity on June 12th, 2019 on How Stripe invests in technical infrastructure, and this post outlines the talk’s content. I’m quite excited about the talk, as it unifies many ideas that I’ve written previously, and which I’ve found to be consistently useful! This isn’t a transcript, the talk will be much more rooted in the particular examples than this outline is.
I’m Will Larson and I’m here to talk to you about investing in technical infrastructure, and in particular about how Stripe has evolved our approach to investing in our technical infrastructure. The ideas here represent much of what we’ve learned organizationally, as well as what I’ve learned personally, about prioritizing and implementing plans in infrastructure engineering teams.
If this goes right, you’ll leave with three or four useful tools to lead, plan and prioritize with your team.
Some quick background on me:
- I work at Stripe–where our mission is to increase the GDP of the internet–and I’ve been there for the past three years leading the Foundation engineering team, where we work on infrastructure, data, and on both internal and external developer tools.
- Before Stripe, I worked at Uber, starting the SRE and platform engineering groups.
- Just a couple weeks ago I released a book, An Elegant Puzzle, which covers several of the ideas that I’m going to discuss today.
Topics
What we’ll cover today, in roughly five minute chunks, is:
- Introduction: self-intro, what is infra, why does it matter
- Foundations: forced vs discretionary, short-term vs long-term
- Firefighting: digging out from fire fixation
- Investment: applying product management
- Principles: cover all your bases
- Unified approach: users, baselines and timeframes
- Closing: where are you now, where to start
Alright, let’s get started!
What is technical infrastructure?
At jobs past, I’ve occasionally met folks who viewed “infrastructure” as “anything my team doesn’t want to do”, but that turns out to be a surprisingly fluid definition. Let’s do better.
Technical infrastructure is the software and systems we use to create, evolve and operate our businesses. The more precise definition that this talk will use is, “Tools used by many teams for critical workloads.”
Some examples of technical infrastructure are:
- Cloud services: AWS, Azure, GCP
- Developer tools: build, compilers, deploy, editors, Git, Github
- Routing & Messaging: Envoy, gRPC, Thrift
- Data infrastructure: Kafka, Hadoop, Airflow, TensorFlow
- Glue: Chef, Consul, Puppet, Terraform
- Lots more stuff qualifies too!
As you can see, we’re working with a broad definition.
Why does infrastructure matter?
This sort of infrastructure is a rare opportunity to do truly leveraged work. If you make builds five minutes faster, and do a hundred builds a day, then you’ve saved eight hours of time that can be invested into something more useful.
The consequences of doing infrastructure poorly are equally profound. If you build unreliable software, your users won’t be able to take advantage of what you’re built. You and your peers will spend your time mitigating and remediating incidents instead of building things that your users will love.
Certainly my perspective is colored by my experiences, but I truly believe that behind every successful, scaled company is an excellent infrastructure team doing remarkable things. Companies simply cannot succeed at scale otherwise.
Foundations
Before we talk about how to invest and evolve, it’s helpful for us to have a shared vocabulary about types of work we’re asked to work on. Each company has its own euphemisms for these things, like “KTLO”, “research”, “prototype”, “tech debt”, “critical”, “most critical”, and so on.
Once we develop this vocabulary for a couple of minutes, we’re going to be able to start talking about the specific challenges and constraints Stripe’s infrastructure teams have run into over the years, and how we’ve adapted to and overcome each of them.

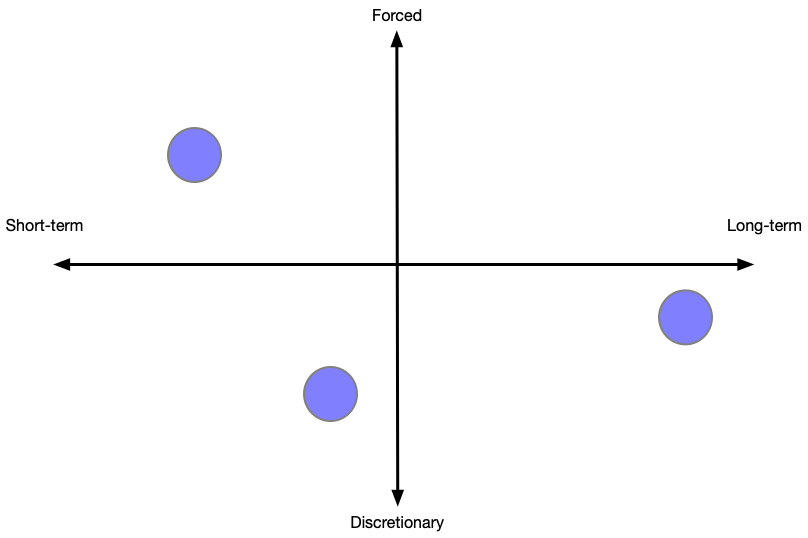
The first distinction that’s important to make is between forced and discretionary work. Forced work is stuff that simply must happen, and might be driven by a critical launch, a company-defining user, a security vulnerability, performance degredation, etc. Discretionary work is much more open ended, and is the sort of work where you’re able to pick from the entire universe of possibilities: new products, rewrites, introducing new technology, etc.

The second distinction is between short-term and long-term work. Short-term might be needing to patch all your servers this week for a new security vulnerability. Long-term might be building the automation and tooling to reduce the p99 age of your compute instances, which will make it quicker and safer to deploy patches in the future.
Then it starts to get really interesting when we combine these ideas.
Now we have this grid, with work existing within two continuums. You might argue that some of these combinations don’t exist, but I’m certain they all do, and that they’re all quite common:
- Forced, short-term - emergencies of all shapes and sizes.
- Forced, long-term - preparation for the mandatory future work that requires major investment. Acknowledging this sort of work can be subversive in some cultures, but it’s real, and creating visibility into its existence is a core aspect of properly investing in infrastructure.
- Discretionary, short-term - these tend to be small, user-feedback-driven tweaks avoid usability, targeted reliability remediations.
- Discretionary, long-term - often generational improvements to existing systems, like moving from batch to streaming computationparadigm, moving from a monolith to an SoA, and so on.
You can plot each project somewhere into this grid, and you can also plot teams’ into the grid. To plot a team, you just sort of sum together all the vectors of the team’s projects.
This opens up an interesting question, where do you want your team or organization to be within this grid?
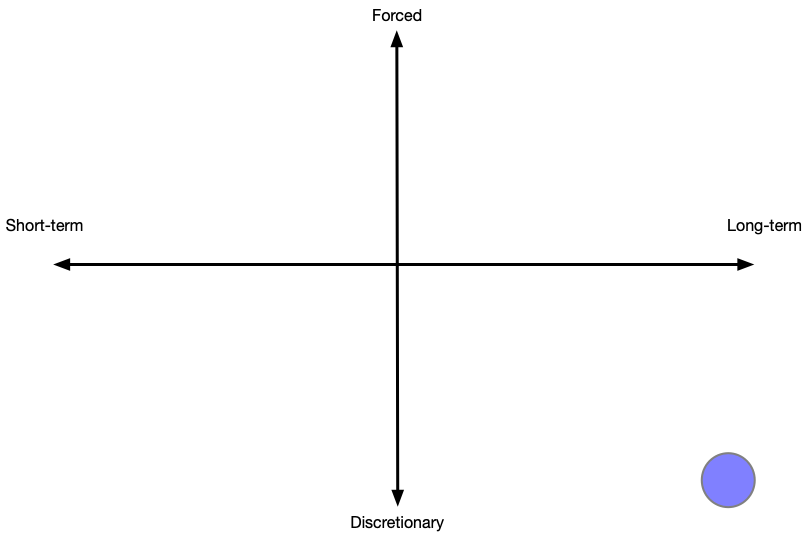
This is the sort of team that many folks initially think they want to join. However, the complete lack of forced and short-term work typically implies that there are few to zero folks using your software, or that the feedback loop between those users and the developers is entirely absent.
You often see this in teams that are described as “research teams.”

This is another common one, typically of teams which are underresourced to their purpose, hopping from fire to fire, trying to stabilize today with dreams of innovating in some distant tomorrow.
Not many folks want to join these teams, but sometimes folks regret leaving them, since these teams have a unique clarity of priority and leadership appreciation of their work.

This is where I think teams should strive to exist. You want some forced work, because they means that folks are using your system for something that matters. On the other hand, you also want some discretionary work, to ensure that you’re investing into building compounding technical leverage over time.
Alright, so we have a mental model, and now we can start to discuss the evolution of Stripe’s approach to infrastructure.
Firefighting
An important aspect of infrastructure engineering, often differentiating it from product engineering, is the percentage of work that simply must be done. The most common case is when a company is experiencing repeated outages, such as Twitter’s fail whale era.
I’m certain that most folks at Twitter didn’t want to be working on stability, but it got to the point where it simply wasn’t possible to prioritize anything else.
Within our framework, this is a team dominated by forced, short-term work, which goes by a variety of different names, firefighting being a popular one.
Key points:
- Prioritize as much work into the future as possible, shedding “forced” work.
- When you’re overloaded, it’s going to be hard. The most important question is whether there is evidence that you’re digging out–that it’s going to be better long-term–or if you’re falling behind.
- To start digging out, sometimes you can get creative, finding more leveraged approach, push on the constraints a few times to make sure you’re not being rigid. The goal here is to find work that addresses “forced” work that also reduces future “forced” work.
- Even small wins start compounding into digging out. My coworker Davin Bogan says that “Shipping is a habit” and I strongly agree!
- Related to shipping being a habit: do less! When Uma Chingunde started to lead Stripe’s Compute engineering team, she focused on consolidating a number of outstanding migration efforts into as few as possible, including pausing some. You only get value from finishing work, not from working on it.
- Other times you’ll find that the “forced” work isn’t possible to deprioritize, the reliability case again, or if you’re about to run out of money and need to cut down your AWS bill.
- If you can’t reduce forced work and you’re falling behind, you have to hire your way out. Keep hiring until you see evidence that you’re digging out. Don’t hire until you’ve dug out, that’ll both set you up for overhiring, and the extended hiring will require extended training, slowing down the time to recovery.
Examples for talk:
- Focusing concurrent migrations, including Kubernetes, Envoy, Ubuntu Xenial, etc
- Hardening and scaling MongoDB patterns, clients and clusters as we scaled data, users and applications
- Scaling your API with rate limiters
Related posts:
Investment
Once your team has fully dug out from fire fighting, you have a new problem: you can do anything! It seems wrong to describe this as a problem, but my experience is that most infrastructure teams really struggle when they make the shift from the very clear focus created by emergencies to the oppressively broad opportunity that comes from escaping the tyranny of forced, short-term work.
Indeed, it’s my belief that most infrastructure teams spend so little time operating in a long-term, discretionary that they stumble when they encounter it. These stumbles often land them back into the warm, clarity-filled hell of firefighting.
If you’re aware of this transition, you can manage it deliberately, and this is when things get really fun! You’ve gotta be intentional about it.
Key points:
You’re used to having clear priorities without much work: it’s easy to spot a fire. That’s not going to work anymore now, you’re going to have be very intentional about determining what to work on and how to approach it.
Really, what you’re about to do is start applying the fundamentals of product management: discover problems, prioritize across them, validate your planned approach.
Discovery. When you have surplus engineering capacity, folks tend to have a long backlog of stuff they’d like to work on, and many teams immediately jump on those, but I think it’s useful to fight that instinct and to step back and do deliberate discovery.
Cast a very broad net and don’t filter out seemingly bad ideas, capture as many ideas as possible. Some techniques that work: user surveys, coffee chats, user group discussions, agreeing on SLAs, peer-company chats, academic and industry research.
If you don’t have folks clamoring for what you’re trying to build–if other teams are not frustrated that you can’t deliver it sooner–than it’s quite possible that you’re solving the wrong problem.
Prioritization. You’ve got to rank the problems. I prefer return on investment as the sort order, but there are a bunch of options. To understand long-term ROI though, you really need to have two things: a clear understanding of what your users need, and a long-term vision for what your team hopes to accomplish (maybe three years or so).
If you’re prioritizing without your users’ voice in the room, your priorities are wrong.
Validation. Once you’ve selected the problems to start working on, you should go through a deliberate phase of trying to disprove your approach. You want to identify the hardest issues first, and then you can adapt your approach with a minimum of investment. Finding problems late is much. much worse.
Some techniques to user here are: embedding with user teams/companies, building prototypes, solving for the hardest user first (not the easiest one as some do), having clear success metrics and checking against them often.
Have to maintain enough mass to your team to stay in innovation. If you start innovation teams too small or destaff them for other work, they’ll not work out. One of our success criteria for new teams is that they immediately enter the innovation model, not the fire fighting one. We facilitate that through our consistent approach to sizing teams.
As a corollary, if you don’t do a good job of picking problems and solutions, then a well run company will destaff your team. It’s an earned and maintained opportunity to have significant discretionary budget.
Consider getting product managers into your infrastructure organization. Not every team needs them all the time, but having even a few who can help navigate the transition from firefighting to innovating is super helpful.
Some random asides related to this topic:
- When to use cloud services? When they are commoditized. Companies chase revenue and margin, and margin is compressed on commodities through competition, so companies then add differentiated new products to drive up margin, stay away from those and you’ll benefit!
- When should you run your own data center? When you have specialized server workloads with unusual capacity ratios, for example need very large quantities of hard disks. Google for example lets you design your own SKU, but underneath there are real servers, and as your company gets larger, you will get pulled into details of capacity planters. Rule of thumb is 30% cheaper to run it yourself, but economies of scale and competition are likely compressing this further. Plus, that’s the raw savings, ignoring opportunity cost, which is an important omission if your business is doing something useful.
- “Technological migrations.” Often you’ll see folks go from one company to another and bring their technology with them, and your entire innovation budget will get caught up changing things without clear goals. This ends in tears.
Examples:
- Learning to operate Kubernetes reliably
- Introducing Veneur: high performance and global aggregation metrics
- Service discovery at Stripe
Related posts:
Principles
So we’re getting to a point where we have a clear framework for getting teams out of firefighting, and a framework for helping teams succeed and remain in the innovation mode, so in theory everything should be great.
But, it’s often not.
Maybe it’s an obvious but ignored scalability problem bursting onto the scene. Or who didn’t hear about one company or another dropping everything to meet their GDPR obligations before the deadline? In both cases, I’ve found that it’s often the case that long-term, forced work goes unresourced becoming an avalanche of unexpected short-term, forced work.
We’ve adopted an approach that I call the “five principles of infrastructure” to help us think about these sorts of problems in a structured way.
Key points:
- Identify broad categories that capture the different properties you want to maintain in your infrastructure.
- For our infrastructure teams, we’ve been using: security, reliability, usability, efficiency and latency. For you, it’ll likely be something a bit different.
- For each of these properties, you need to identify a baseline of what acceptable performance is. For example, maybe for your infrastructure spend you want to set a goal that your cost per 1,000 transactions doesn’t exceed some absolute number, or maybe you want to have a fixed ratio of revenue to infrastructure dollars spent.
- Each time you do planning, review your baselines and how performance against those baselines is shifting.
- Then look one and two years ahead: how does your trendline look then?
- If you’re doing ok, then you’re golden, carry on with your innovation-oriented approach.
- If it’s trending in the wrong direction, then do a quick brainstorming session on the sorts of work that it’s going to require to get into a good place, and do a rough cost estimate on the amount of time it’ll take to get there.
- If it’s going to take multiple quarters to get right, and you’re only multiple quarters away from that deadline, then congratulations: you’ve discovered forced, long-term work!
- Oh yeah, you have to prioritize and actually get it done.
Examples:
- Railyard: how we rapidly train machine learning models with k8s
- Sorbet - a fast, powerful type checker designed for Ruby
- Running three hours of Ruby tests in under three minutes
- Stripe’s approach to AWS Reserved Instances
Related posts:
- Infrastructure between cost-center and before ego trip
- Infrastructure planning: users, baselines and timeframes
Unified approach
So we’ve covered quite a bit so far! Firefighting, innovation, baselines, and so on. If you’re working with one team or a smaller organization, then this is probably enough to guide your infrastructure team for the next year or two.
However, things get rather complicated when you’re responsible for coordinating an organization with a couple dozen infrastructure teams, which is the problem we were facing towards the end of last year.

Then challenge then is to take all these ideas, and find a way to provide useful guidance for many different teams when, that accounts for the fact that some of those teams are going to be in innovation mode, others firefighting, and others somewhere inbetween.
What we’re about to talk about is how Stripe’s Foundation engineering team of about two hundred engineers does our planning on behalf of Stripe’s roughly six hundred engineers.
Key points:
- “Users first” is one of Stripe’s operating principle, and it’s also where we start in our planning. What are the top five to ten prioritized asks from across the users that depend on you?
- We identify the baselines for each of our infrastructure properties (security, reliability, etc), looking at performance in both the near-term and long-term. What are the projects and investments we need to make in order to preserve these baselines?
- We pick two to three “key initiatives”, which are large projects that we’ll need a significant fraction of the Foundation organization to partner on in order to make progress. If we could only do a couple large projects, what are the most important? We constrain these to six months to maintain flexibility to react to new information coming up – the biggest opportunities today are unlikely to be the biggest opportunities six months from now if we’re executing well!
- We allocate 40% of time to user asks (things that directly solve users existing problems), 30% to platform quality (work to preserve our baselines), and 30% to the key initiatives.
- User asks and platform quality investments are prioritized at the individual team level, and key initiatives are prioritized at the Foundation leadership level. This breakdowns preserves the majority of team autonomy while also providing a budget for senior leadership to adapt.
- Overall, working pretty well! Biggest challenge in implementation is unplanned work from other teams that overflows teams’ “user asks” budget.
- This approach does provide some tools though, typically it the form of slipping on key initiative timelines. That is, unsurprisingly, not that fun, but it’s a large enough budget that it allows us to slip schedule clearly in one place, instead of slipping budget across numerous smaller projects, which increases predictability.
- Is this the last approach? I’d like to imagine it is, but history suggests it isn’t. I’m excited to see how we evolve this approach next.
Related articles:
Closing thought
Ok, so let’s recap what we’ve discussed a bit.
There’s no single approach to investing into infrastructure that’s going to work for you all of the time. Identifying an effective approach depends on recognizing your current constraitns, and then accounting for them properly. While no one has solved this, but there are a bunch of good patterns to reuse:
- If your team is doing forced, short-term work, then dig out by investing into your operational excellence.
- If your team is just starting to experience the thrills of discretionary, long-term work, then invest into your product management skills.
- If you have discretionary budget, but still find yourself running from one problem, then identify the principles to balance your approach, and set baselines for each principle.
Like any good strategy, the hard part here is really cultivating honest self-aware about your current situation. Once you understand your situation, design a solution just requires thorough thoughtfulness, rigorous studying of requirement, and continuing to refine the course.