Healthchecks at scale.
A couple of days ago at Stripe’s weekly incident review, we started a discussion on a topic that is always surprisingly controversial: healthchecks. I’ve been thinking about them since and have written up what I’ve learned about healthchecks.
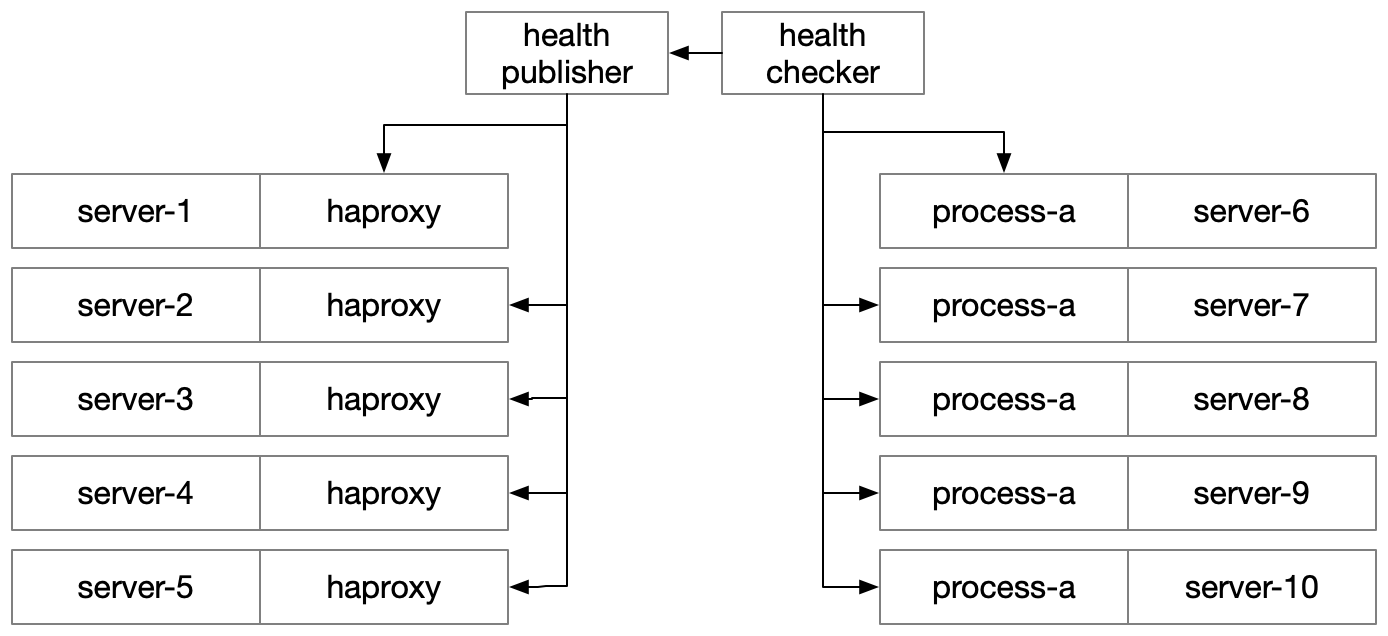
When I joined Uber, we relied on HAProxy to route traffic between processes. HAProxy was configured in what might now be described as the sidecar pattern.
We ran one instance of HAProxy on every server, and generated a server’s routing configuration by inspecting metadata stored within the configuration database Clusto, which has some similarities to Consul or etcd, but makes two different fundamental design choices, picking (a) strong consistency over availability and (b) abandonment over widespread, commercial success.
Within Clusto, each service declared (1) the port it should be reachable on, (2) which kinds of hosts should be able to route traffic to it, (3) which hosts it should run on, and (4) its healthcheck protocol and endpoint.
The aggregated metadata from Clusto was compiled into per-server
HAProxy configurations, such that a process running on a subscribing
host type would direct traffic to localhost:$DEST_SERVICE_PORT
and get routed to a healthy instance of the target service.
Each HAProxy instance was responsible for checking the health of
its downstream services. This was configurable, but for the vast
majority of services this meant sending an HTTP request to /health
and inspecting the response’s status code. If it was a 200, then
it was available for traffic, and otherwise it wasn’t.
Both humans and software could manipulate a process’ healthiness
by using scripts along the lines of status-down and status-up,
which would be inspected by /health when deciding on the appropriate status
code to return.
This approach has some nice properties.
It recovers quickly and without human action in the case of
network partition. You can build arbitrarily sophisticated
tooling to manipulate the status-down tooling to indicate a process
shouldn’t receive traffic, which was used by our deployment tooling to
drain traffic before upgrades.
Further, there are few moving parts in this solution, making it easy to maintain and extend.
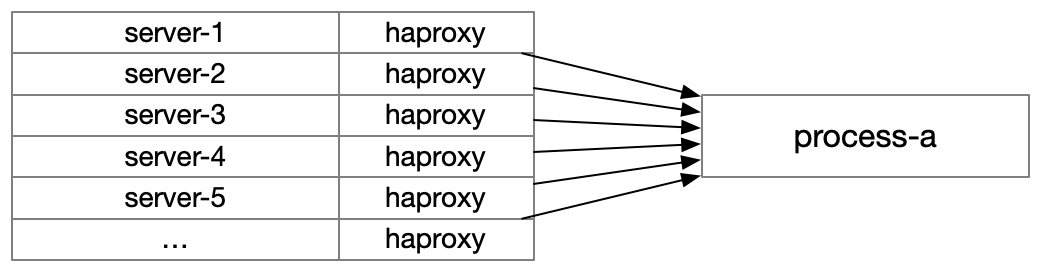
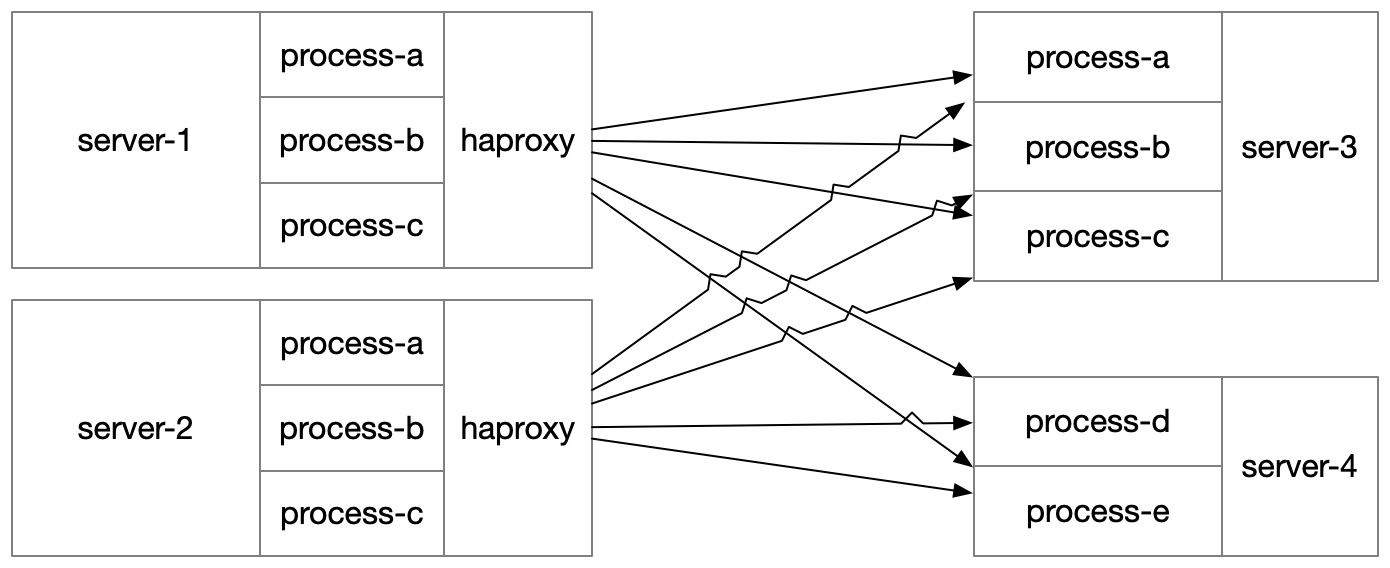
However, it also has some downsides: the number of healthchecks performed scales multiplicatively in combination with the number of services and hosts. Roughly, the calculation for the number of healthchecks performed is:
number of hosts *
average number of services per host *
average number of downstream services per service *
average number of instances per services
Plugging in some numbers, let’s imagine we have 100 hosts, each of which runs 10 services. Each service depends on 3 other services. Each service has 20 instances.
This gets us:
100 * 10 * 3 * 20 = 60,000 healthchecks per period
We don’t have to perform healthchecks every second, let’s say we’re willing to tolerate 15 seconds of delay, then we’re doing about 4,000 healthchecks per second. Keep in mind, these are very small numbers. In reality, we had far more hosts, far more services, far more downstreams and far more instances.
The numbers got big, quickly.
We added a high-performance healthcheck cache on each server which served cached responses, and refreshed healthcheck responses out of band to reduce load on servers implemented in slower languages like Python and Node.js, but ultimately the sheer volume of network traffic and cpu time spent healthchecking became a bottleneck.
At this point, you have three options: (1) you can start restricting discovery to operate within pods, (2) you can offload healthchecking to a centralized or partially centralized mechanism, or (3) you can rely on inspecting traffic, e.g. passive healthchecks, to determine healthiness instead of active healthchecks.
Uber experimented with and adopted elements of all three, and ultimately I’m going to make the argument that you should, at an appropriate level of scale and complexity, adopt all three, as well.
Pod-scoped routing
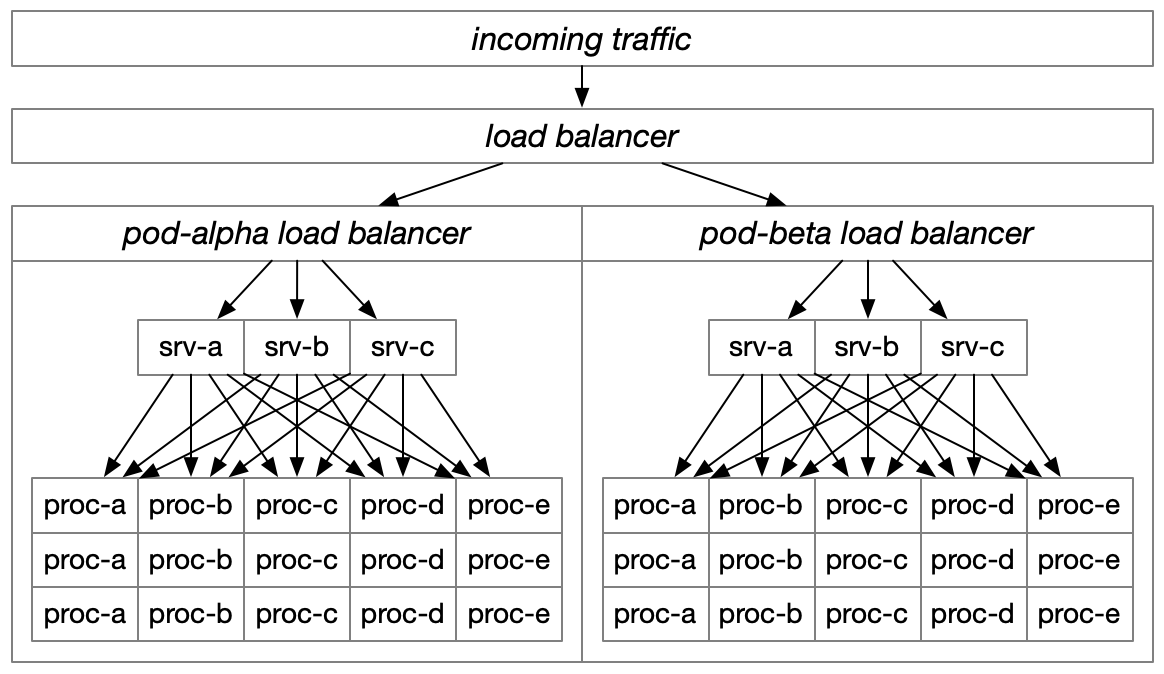
Reducing the servers which are able to communicate with each other, which I’m naming pod-scoped routing, has at least three distinct advantages.
Most importantly, this allows you to establish clear separation of fault domains, such that one pod can fail without impacting other pods performing similar work. The most common industry case of this is restricting cross-region traffic in a high-availability or disaster recovery architecture. These separate fault domains become particularly effective deployment targets, especially for slower infrastructure changes performed via Puppet or Terraform.
Pods also allow you to minimize latency by only allowing traffic to nearby hosts. With a particularly small pod size, it becomes possible to maintain established connections with downstream processes without the load distribution skew that comes from only establishing connections to a subset of downstream services, while also limiting the memory and cpu invested in connection overhead.
Finally, at a certain scale your network costs can become a major contributor to your overall infrastructure costs, if you’re not careful about architecting network traffic. Pod-aware routing is an effective way to minimize expensive network traffic.
As a quick note, some folks attempt to limit healthcheck overhead by restricting each host’s awareness to a random subset of downstreams. This is essentially an ad-hoc, difficult to reason about implementation of pods. It makes deployment strategies particularly difficult to reason about: even a small, incremental rollout might remove all capacity for some host that happens to only be aware of those particular hosts. In general, random subsetting is an approach to avoid if possible, although it’s workable as a sort-of, last-ditch approach to postponing an infrastructure apocalypse.
Centralized healthchecking

At the cost of some infrastructure complexity and somewhat reduced resiliency to network partitions, you can avoid the barrage of healthchecks by centralizing healthchecking responsibilities. Instead of each HAProxy instance (or whatever your proxy of choice might be) performing its own healthchecks, instead you have a centralized mechanism that performs the checks for you and either (a) broadcasts the healthiness data to subscribers or (b) provides an expressive interface to allow proxies to quickly and inexpensively retrieve the latest healthiness data for their particular interests.
There are considerable best-case versus worst-case optimizations you can make in the design of your centralized checker to minimize downsides of this approach. For example, you don’t have to go from thousands of proxies checking a downstream’s health to having just one process performing the check. You’d probably want to have each downstream’s health checked by three to five redundant processes to continue proper function if a checker degrades.
Most technology companies operating at moderate scale will end up implementing their own roughly equivalent version of Envoy’s approach, but the usecases here are pretty commodity and ripe for consolidation into fewer, common implementations.
In terms of easily accessible technology to support this approach, Envoy has good support for this pattern. You’d first implement a Endpoint Discovery Service that handles the healthchecking, and each Envoy instance would check against the EDS for routing data instead of performing local determinations.
Inspecting traffic
While active healthchecks are your primary tool for updating your routing tables to reflect intentional transitions such as a deployment, host upgrade or whatnot, it never pays to forget that the vast majority of active healthchecks are implemented along the lines of:
@route("/health")
def healthcheck(req):
if exists("/etc/status_down"):
return "DESPAIR", 500
return "OK", 200
This moderately useless standard implementation makes them poor representatives of the process’ actual condition. If you want to have responsive routing which quickly responds to degraded processes, active health checks are not enough.
You need to add passive healthchecks.
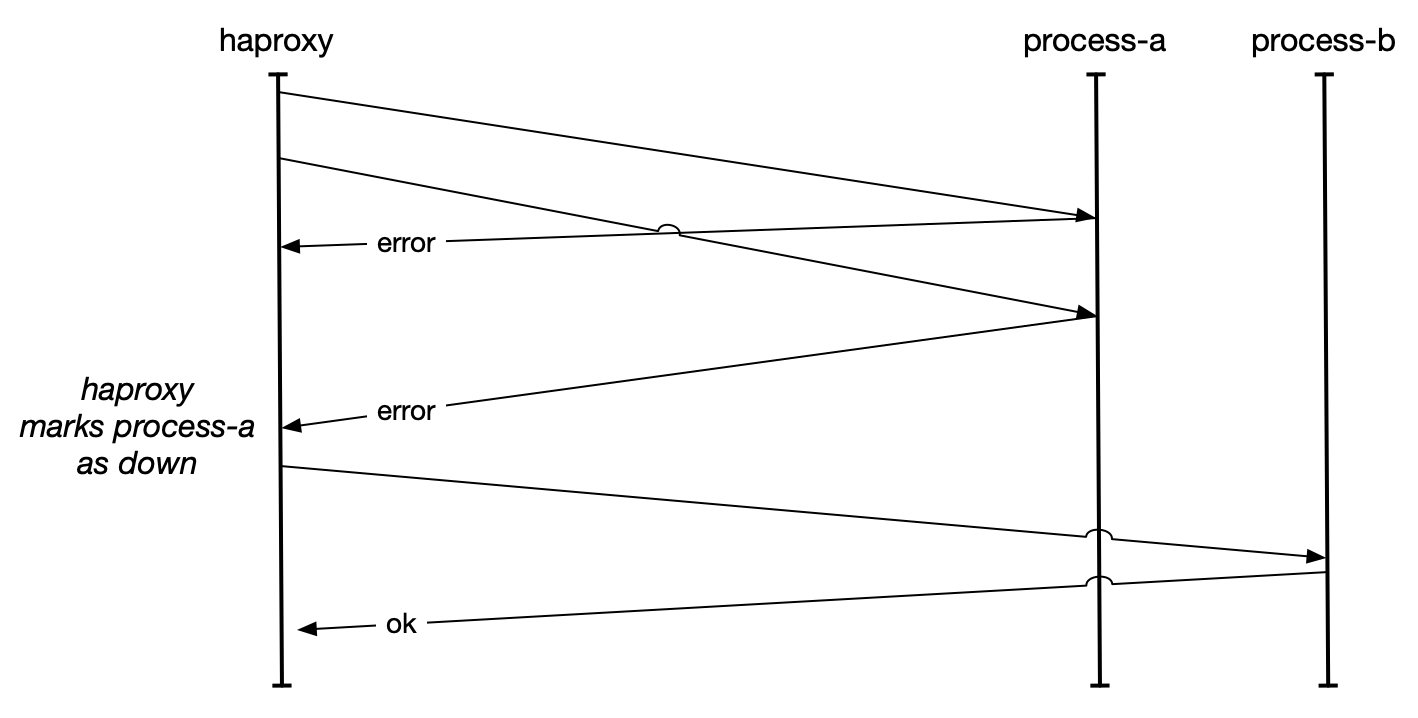
Passive healthchecks in this case can be as simple as inspecting the response codes from a downstream process and if they exceed a threshold, removing them from rotation. Even a very stringent threshold such as removing a downstream from rotation if more than 50% of requests return errors works surprisingly well. Envoy’s outlier detection mechanism is an interesting, real-world version.
The value of passive healthchecks is in minimizing the impact of errors to your upstream users and dependent processes. Consider the common canary deployment pattern used to verify software on a subset of hosts. You’ll start out by deploying a new version to five hosts, and if the error rates are similar to existing error rates, you’ll continue your deployment.
What happens if you canary deploy broken software, perhaps calling a method that exists in your
test environment but not in your production environment, such that 100% of requests handled
by canary hosts are failing. Your /health endpoint is unlikely to exercise that endpoint, and will
continue to happily give you the thumbs up, letting the canaries stay in rotation until you trigger a rollback.
Even in the best case, a rollback will often take a number of minutes, and if you have to fail forward with a new build, test and deploy cycle
(which is an anti-pattern, to be sure), then it might take considerably longer.
If that canary is taking 1% of traffic and you’re relying on active healthchecks for routing, then you’ll continue to fail 1% of user requests for several minutes until the revert completes. This is a bad outcome, even if your software is closer to the societal impact of serving funny cat videos than saving lives. Conversely, even very conservative passive healthchecking thresholds would identify these hosts as misbehaving and remove them from rotation in less than a minute.
This separation of mitigation–removing the bad hosts from rotation–from remediation–reverting to a better version–is essential to rapid recovery and minimizing user impact. This is even more true when you consider slower changes such as rolling out puppet configuration, proving a new database version in production or what not, where shifting routing away remains quick but reverting is dangerous and slow. Most critically, though, this allows you to recover before you diagnose, and in complex distributed systems the diagnosis is typically the slowest step.
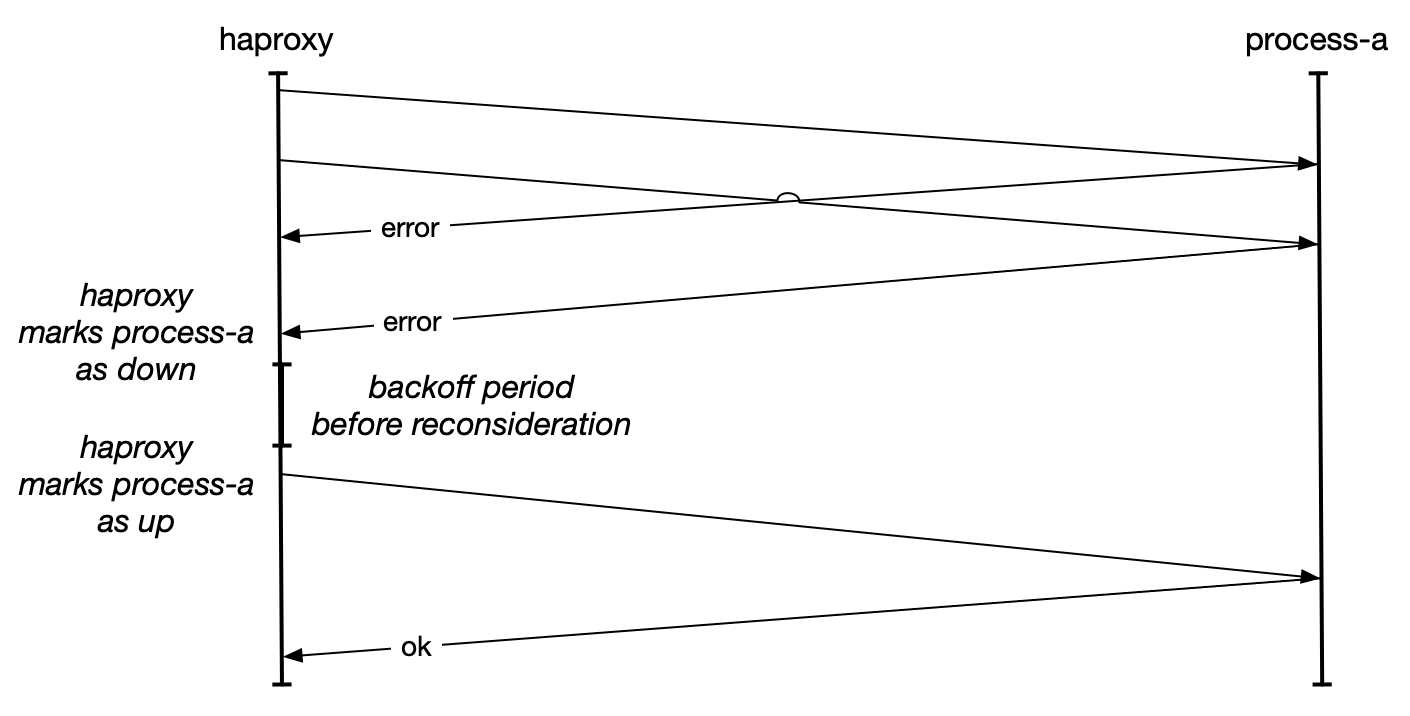
Once a downstream process is marked as unhealthy, recovery works along the lines of the circuit breaker pattern. You’ll wait for a while, then send a fixed number of probing requests to the unhealthy downstream. If they respond favorably then you’ll mark it as healthy and continue sending it traffic.
Sometimes folks get caught up in the complexity of updating their routing configuration to perform
passive healthchecks, but this can also
be accomplished by extending your /health equivalent
to look at a local cache of response codes and to modify the health based on recent results.
This approach suffers from the curse of per-process customization, but does allow you to roll
out passive healthchecks without modifying your existing routing and healthchecking
infrastructure too much.
Uber’s defunct Hyperbahn leaned particularly heavily into passive healthchecks, eliminating the concept of a proxy performing active healthchecks entirely (although, as described above, the ability for a centralized healthchecking system to inform proxies of updates to their routable downstreams can provide most benefits of active healthchecks).
Instead, it relied entirely on whether downstream processes were responding properly to incoming traffic, removing them from rotation if not. This combined with clear semantics around automatic retries for idempotent operations was able to minimize leakage of failures to upstreams. It also intended to use the same semantics to implement some of the preemptive retries approaches described in The Tail at Scale, although I forget if that ended up getting implemented.
You should use all three
In the long-run, I’m pretty confident that any sizable deployment is going to find itself wanting to perform active and passive healthchecks, route within fault-domain-scoped pods, and centralize healthchecks to reduce healthcheck volume. I’m certain there are folks who have managed to postpone doing some of these for quite a long time, but each provides so much utility that I’d recommend adopting them as early as possible rather than later.