Global secondary indexes.
At work we’ve been planning the next phase of our storage infrastructure, and a big part of that conversation has been around global secondary indexes (GSIs), a technique used by horizontally scalable datastores like Cassandra, DynamoDB and Couchbase. While I was super comfortable nodding along, I wasn’t sure I actually understand the concept particularly well, so I’ve spent some time learning more about them, and wrote up some notes.
Secondary indexes
Most applications start out storing their data in a single node datastore of some kind, perhaps MySQL or PostgreSQL. In workloads with more reads than writes, the typical next step is to adopt a primary-secondary replication strategy, with all data mirrored across multiple nodes. Each additional node has a full copy of the data, and supplies additional CPUs, memory and disks that can be put to work retrieving that data.
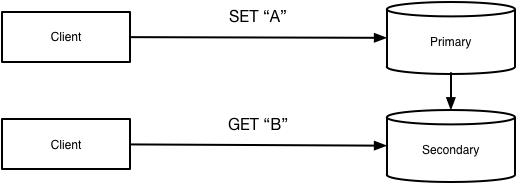
Reads and writes against the primary can be strongly consistent, and you can even add transactions to atomically add or modify multiple rows. In most databases, each table is represented as a B+ tree, allowing you to perform efficient queries against rows’ primary key.
You can add additional indexes to your tables, which materialize more columns into a new B+ tree to support efficient queries against columns other than the primary key. Even better, because all your writes are occuring on a single server, you can transactionally update indexes with their rows.
Because your data and its indexes are stored in the same place, there is almost no latency penalty for providing strong consistency: a simple in-memory lock can provide all the guarantees you need.
You rarely want to leave the primary-secondary model, but success typically gives you little choice. For a while you can scale vertically with more larger servers and data compression, but eventually the write throughput or data size will overwhelm even the largest server and most thoughtful configuration.
Sharding
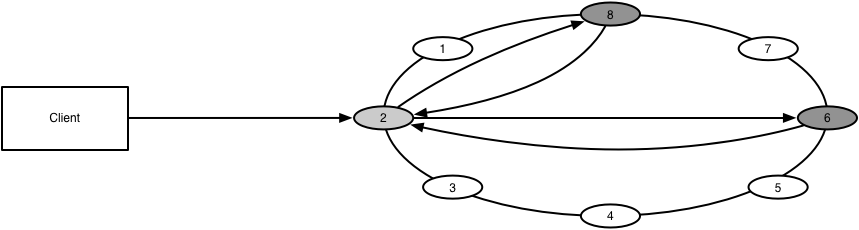
The partitioning data across nodes is called sharding. The top priority for most companies when they start sharding is to minimize rewriting existing application logic, so they tend to identify a logical object they can use to shard every table. For example, in the above table, depending on your queries, you’d probably shard by company.
Let’s say you do choose company as your shard key. Then for every query you’d first determine which node stores that company, and then direct your query to that database. The mechanism that routes to the correct node is sometimes called a coordinator, but can also be as simple as your client using consistent hashing on the shard key. In some implementations, and in this article’s diagrams, every node fills the double duty of storing data and routing incoming requests to the correct node.
A node would have all the data for a company, and probably a bunch of other companies, but wouldn’t have all the data for say, Seattle, because data is being grouped by company and not by city.
Local secondary indexes
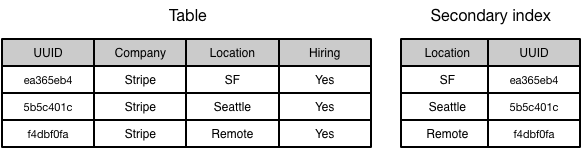
This pattern, cotenanting an object’s data and indexes on the same node, is known as local secondary indexes. Depending on your underlying datastore, e.g. MySQL or PostgreSQL, you’ll get transactions and strong consistency when operating with a single node. For example, you could store an index that lets you search for a given company’s jobs on the same data node as the rest of the company’s data, allowing you to atomically update that local secondary index along with the data.
The downside is that these indexes are scoped to a given shard key, and consequently can answer questions like “what are jobs for Stripe?”, but not questions like “what companies have jobs in Seattle?” without scanning every single node, which is a pretty expensive operation.
As long as the data for a given shard key remains small, this strategy scales indefinitely by adding more data nodes. However, many folks eventually find individual shards that grow beyond what a single node can store. Others become tired with the query restrictions created by only being able to query across the data for a single shard key.
Global secondary indexes
This is where global secondary indexes come in.
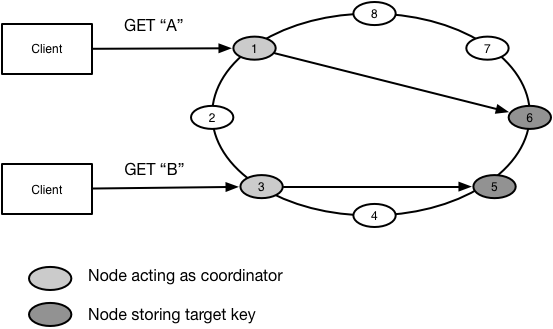
The idea is to create a second table that uses a different column for its shard key, and store the primary table’s shard key in a column. This makes it possible to go to the secondary index, retrieve the primary key, and then do a second lookup to retrieve the row.
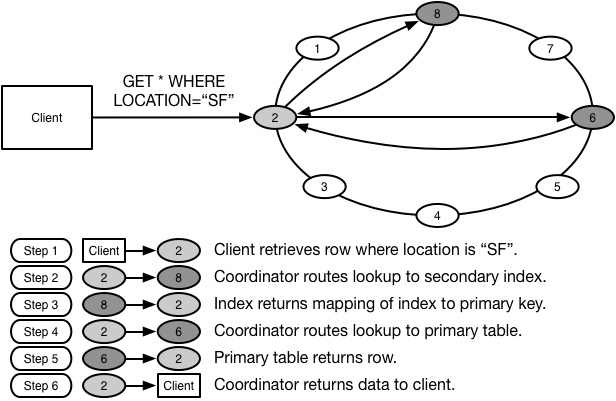
Now we can query by company, city or any other field that we choose to build a GSI on. We’re also able to shard these secondary indexes across all nodes, reducing the amount of data we need to store in any individual shard. This horizontally scales reads, writes and disk storage further than we could in our local secondary index model.
But we do have a new constraint.
Each secondary index is being sharded by a different shard key, so we can no longer guarantee data for a given company is on the same node. Updates to an object with multiple secondary indexes will likely require writes across a number of shards. Those writes will occur under the constraints of the CAP theorem and subject to the latency costs of traversing between nodes. The data itself is still on a single node, just not its indexes, so it’s still possible to have strong consistency around updating the object, but most implementations (e.g. Cassandra, DynamoDB, Couchbase) choose eventual consistency for secondary indexe updates to avoid incurring significant latency.
Some proprietary implementations, particularly Cosmos DB and [Cloud Spanner]((https://cloud.google.com/spanner/), do provide strong consistency across both the sharded objects and the GSIs storing their data, but I’m not familiar with any open source implementations that do so.
Even in the case of these proprietary systems, it’s perhaps worth reflecting on aphyr’s jepsen articles, which document how many distributed systems can sometimes fail to live up to their claims.
Final thoughts
Overall, I hope these notes help explain global secondary indexes, and in particular show they’re something pretty simple and approachable. Maybe it’s even inspired you to spin up a Cassandra cluster to give their GSIs a whirl, or start hacking together your own take on the FriendFeed sharded MySQL strategy.
While writing this post, I found these resources super helpful:
- Dynamo paper, the precursor to Cassandra and AWS Dynamo DB
- AWS Dynamo DB’s Global Secondary Indexes documentation
- Azure Cosmos DB’s documentation about consistency
- How FriendFeed uses MySQL to store schemaless data
- Scalable, Distributed Secondary Indexing in Scylla
- Couchbase’s global secondary indexes documentation