From lambda to kappa and dataflow paradigms.
I’ve spent some time coming up to speed on the state of modern data infrastructure lately, and this is an attempt to weld the notes I took along the way into a cohesive narrative. I’m quite certain there are a number of mistakes and omissions, and I’d love to hear what folks think could be expanded or fixed!
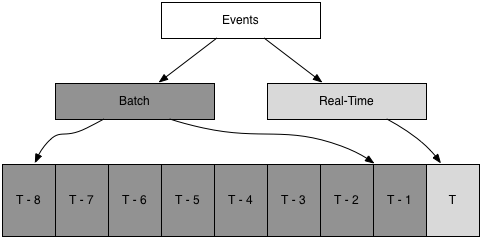
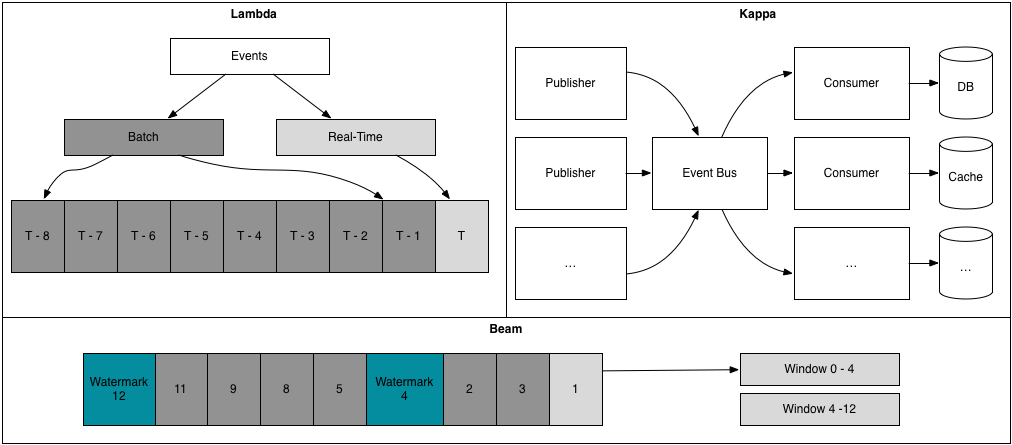
Lambda architectures started coming into widespread awareness in 2013, thanks to work by Nathan Marz, and subsequently became a popular architecture. Their particular advantage was using real-time stream processing to calculate recent windows, and using batch processing to calculate final values for windows as they aged out. Batch is also used to backfill new or modified calculations.
One of the principle technologies in this wave was Storm, first released in 2011, which reached wide adoption as the real-time component of lambda architectures, often paired with Kafka for storing logs, and the Hadoop ecosystem for batch processing.
As more companies adopted these patterns, three primary concerns started to emerge:
- dual implementations: the streaming and batch components tended to diverge significantly enough that they required logic to be implemented twice, in different paradigms.
- weak real-time correctness guarantees: not only was the batch computation necessary to handle backfills, it was also necessary to reach a high degree of data correctness, as the real-time components only supported at-most-once and at-least-once guarantees.
- operational toil: while the Hadoop ecosystem has had years to trend towards maintainability, these real-time components were less mature and tended to introduce significant operational toil, in particular Storm’s dependency on Mesos and ZooKeeper frustrated some adopters.
While the lambda architectures played out in the industry’s public eye, innovation was germinating behind closed doors, and two years later in 2015, at least three interesting threads dropped fruit:
Google published The Dataflow Model, which proposed a unified approach to streaming, micro-batch and batch processing, which in particular gave guarantees around exactly-once processing.
Twitter operationalized the lambda model. They took two paths: building Heron, an operationally improved version of Storm which shared its correctness limitations, and investing into summingbird which allowed the same code to run on Storm (or Heron) and Cascading (in particular, Scalding), a batch processing library that ran on Hadoop.
At approximately the same time, Jay Kreps’ log evangelism was maturing into a Kafka implementation that would eventually offer exactly-once guarantees, the stream processing framework Samza which offered exactly-once stream computation, and more generally the Kappa architecture (where all traffic goes through a centralized event bus rather than requiring publishers to understand behavior and needs of their downstream consumers).

(This presentation looks at one adoption of a Kappa architecture.)
In the two years since, something of a data infrastructure renaissance has flourished into a dynamic ecosystem. The new generation of tools trends towards low-latency data pipelines through both micro-batching (as seen in Spark Streaming) and native-streaming (as seen in Flink Streaming), and new strategies to enforce exactly-once event processing, which has allowed stream processing to achieve levels of correctness that previously required batch processing.
While most lambda architecture technologies are seeing reduced adoption (e.g. Storm), some have managed to jump generations to become standard building blocks. In particular, Kafka, Hadoop YARN and HDFS remain entrenched. YARN and HDFS are interesting as technologies which originally entered the ecosystem in the even earlier map-reduce wave, and have now survived two generational shifts.
YARN appears the most fragile of the three, with most frameworks offering standalone modes of operation, in addition to continued competition from more general schedulers like Mesos, although Mesos itself feels like it’s losing significant mindshare to Kubernetes (despite Mesos and Kubernetes being meaningfully different tools to address different needs).
Of those technologies making the generational leap, Kafka in particular is expanding its feature set in a bid to differentiate and grow its mindshare. The clearest example of this is Kafka Streams, which is effectively an Apache Storm competitor with fewer dependencies, fewer concepts (can be reasoned about as consuming a Kafka topic and outputting a compacted Kafka topic), and exactly-once guarantees. By design, it’s not a direct competitor with the more complete streaming frameworks:
The gap we see Kafka Streams filling is less the analytics-focused domain these frameworks focus on and more building core applications and microservices that process real time data streams… building stream processing applications of this type requires addressing needs that are very different from the analytical or ETL domain of the typical MapReduce or Spark job. They need to go through the same processes that normal applications go through in terms of configuration, deployment, monitoring, etc. In short, they are more like microservices (overloaded word, I know) than MapReduce jobs. It’s just that this type of data streaming app processes asynchronous event streams from Kafka instead of HTTP requests.
Beyond Kafka Streams, Confluent is actively working to expand the Kafka ecosystem by plugging gaps in their tooling ecosystem with efforts like Kafka Connect, which tries to address common Kafka rollout dependencies like schema management and abstracting Kafka’s low-level APIs.
Moving away from Kafka Streams and their intentionally narrow scope, the two analytics-focused frameworks that appear to be winning this generation’s mindshare are Spark and Flink.
Both tools are receiving wide adoption, with an edge to Spark for batch/bounded processing, and to Flink for streaming/unbounded processing (in particular, as Flink supports native streaming and Spark relies on micro-batching, which incurs a latency penalty that may inhibit some usecases). More conceptually, Flink is an explicit inheritor of Google’s Dataflow (now rebranded Beam) model, whereas Spark’s novelty comes from its resilient distributed datasets.

At the same time, Google is making an interesting play to abstract away both Spark and Flink through their Beam library, which provides a library to implement dataflow paradigm programs that run on top of a variety of runners (include Flink and Spark, but also Google Cloud’s Cloud Dataflow product). There are some very interesting ideas in the dataflow approach, and I particularly appreciated these explanations of windowing, snapshots and session windowing.
Overall, it’s quite an interesting time to be paying attention to data infrastructure, and I’m quite excited to see how things pan out.