Notes from fifth blog rewrite
One of my projects for 2017 has been cleaning up my online accounts. This started out with closing things I didn’t use, moving to a password manager, buying YubiKeys, and setting up 2FA everywhere.
It got slightly more complex with moving all my domains from GoDaddy over to AWS Route53 as the domain registrar, and finally I’ve moved from Linode to AWS for my VMs. (No quibbles with Linode, just looking for more of everything than they have to offer.)
Like usual, this ended in me rewriting my blog.
(Amazingly, I realized after finishing it, this is my second blog post in which I claim to have rewritten my blog five times. Maybe the precedent here is to claim all future rewrites are the fifth.)
For capricious and arbitrary reasons, every year or two I end up rewriting my blog. Mostly I use it as an opportunity to learn about a programming language, a set of libraries, or hosting infrastructure.
Over the years it’d changed from an extraordinarily complex Django app running on Slicehost (honestly, it also ran on DreamHost for a while) to a Go app on Linode, and finally over the past few weeks I’ve rewritten it again into a simpler Go app and migrated over to AWS.
The old architecture was extraordinarily simple:

Essentially, this was a single Linode with a public IP address which took direct traffic. It had Nginx fronting a net/http Go server, and relied on a local Redis instance for all persistence. Redis tracked real-time analytics to determine trending stories, and a command line tool inserted markdown posts from a Git repository into Redis.
And the new implementation remains pretty simple, although it has a few more pieces.
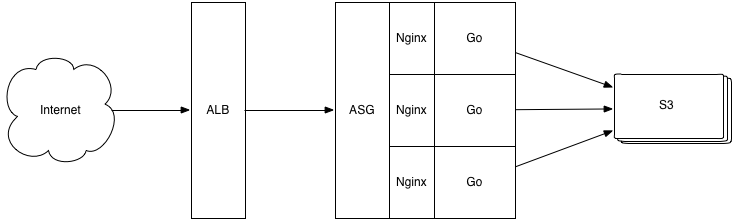
Incoming traffic hits an AWS ALB, which is load-balanced across an ASG, populated by AMIs that are running a Go server. (A rewritten and simplified Go server, but pretty similar overall.) The AMIs are built via Packer (I got annoyed half way through using Terraform for the overall AWS configuration, but will probably go back and redo it later).
I pondered how to manage state between instances in the ASG, and ended up with a pretty basic strategy:
- As a variation on the Jekyll strategy, take an
index.yamlfile and the blog posts to compile apacked.yaml. Thepacked.yamlfile contains all the data necessary to run the blog, and (along with a path to static assets) is all the state maintained by instances. - Run a periodic sync script which syncs
packed.yamland static assets down from S3 to each instance. - Use Google Analytics instead of managing my own analytics in Redis. As a corollary, give up on inferring trending posts and move to specifically curating popular posts. At its best, a trending approach should have simply been a faster and wiser version of featuring posts, but in practice I never tuned the algorithm, and old posts stagnated at the top indefinitely.
When the ASG spins up a new instance, it fails its healthchecks until it has successfully completed a content sync, allowing the above strategy to work cleanly with new instances as well. (Although, my healthchecking logic appears to have a gap somewhere that inconsistently causes it to succeed too early, I’ll need to dig in at some point.)
A few other highlights:
- Added HTTPs, and redirect all HTTP requests over to HTTPs.
- Search actually works properly now. Previously Blekko (Go library) frequently got stale for unclear reasons.
- Introduced concept of a hero header image, and added Opengraph tag for it to get crawled properly.
- Moved the sidebar off the front page, more room for hero images, etc.
- Gave up on trending algorithms and moved to curation. I think this is “on internet trend”, but that’s entirely a coincidence.
Finally, some before and after shots.
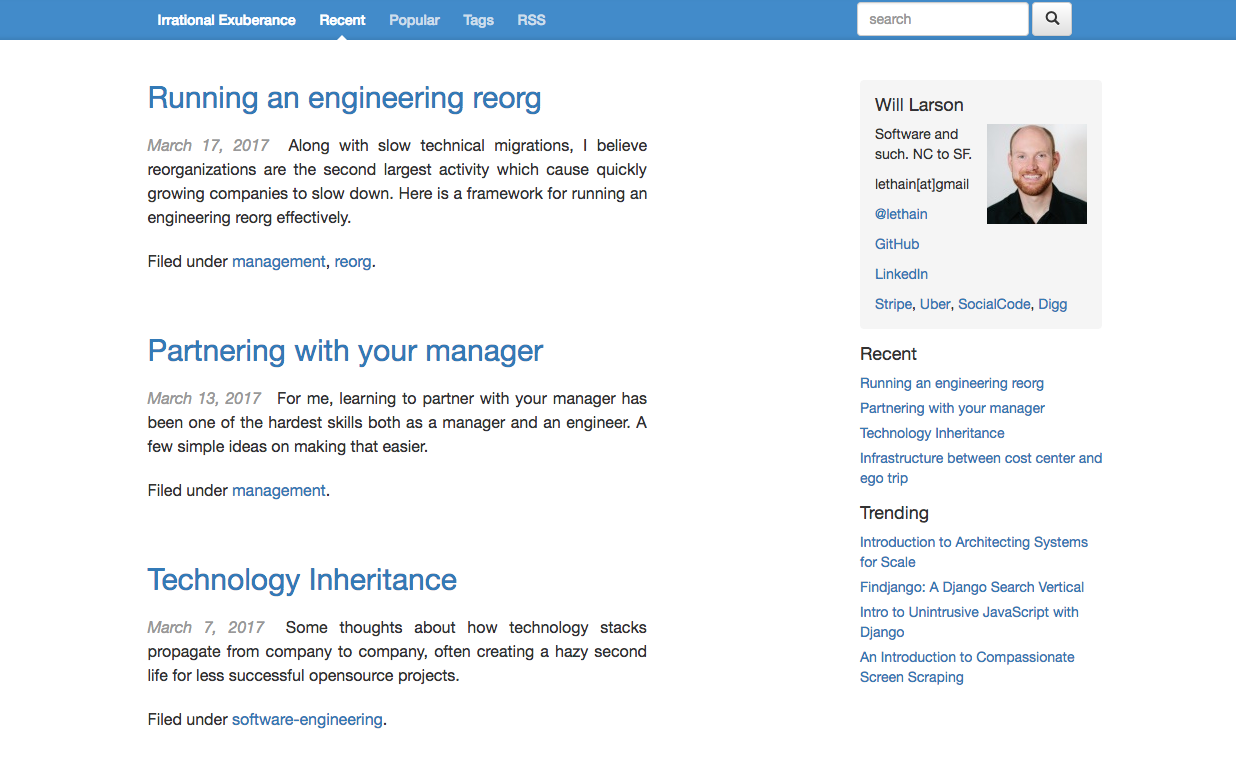
The old list of posts page:
The new list of posts page:
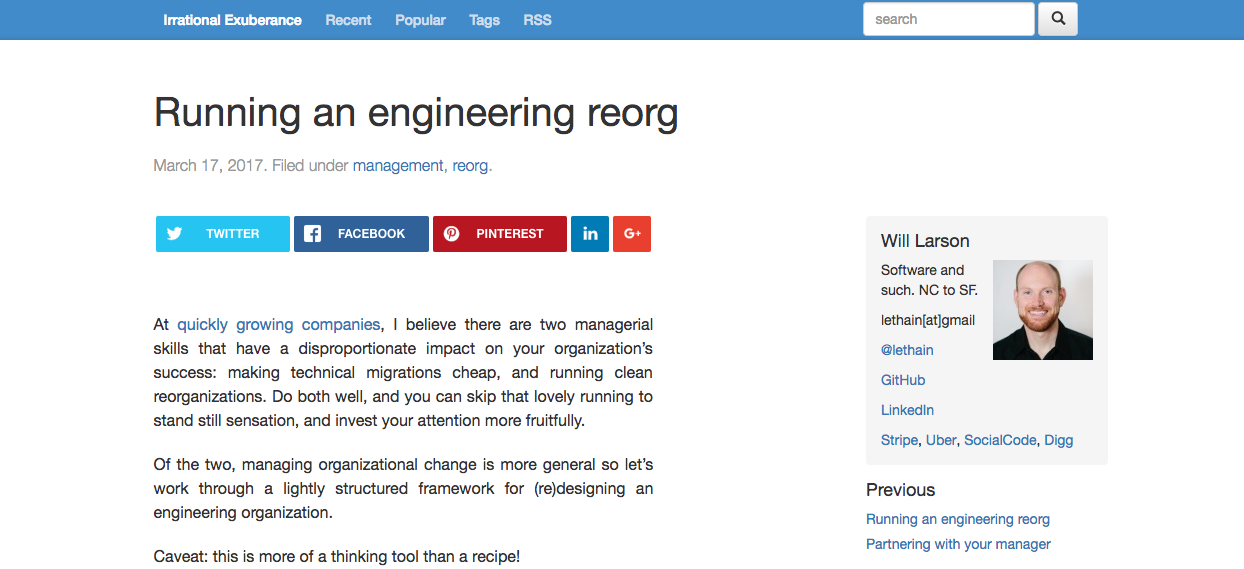
A picture of an old post, without hero images:
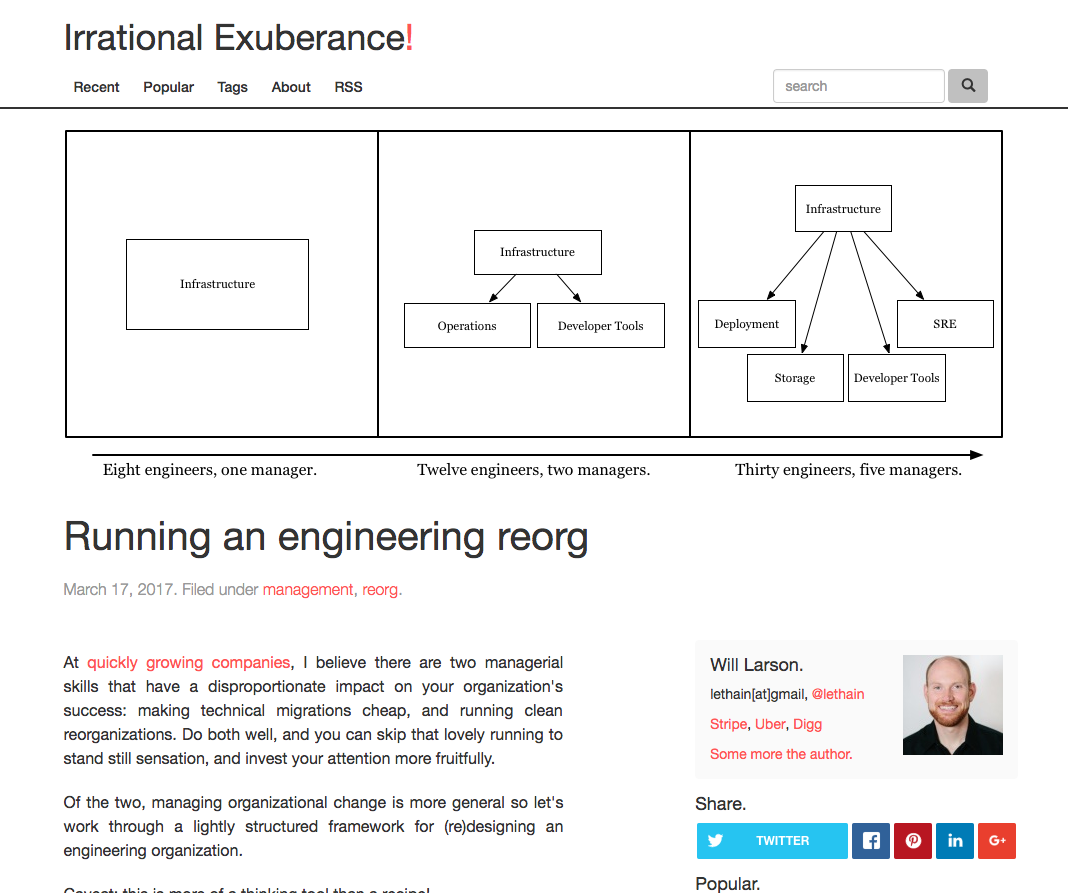
A picture of a new post, with hero images:
Altogether, it’s still ludicrous that I run my own blog and spend more time rewriting and managing it than I do writing on it, but, ah, such as the little pleasures in life.