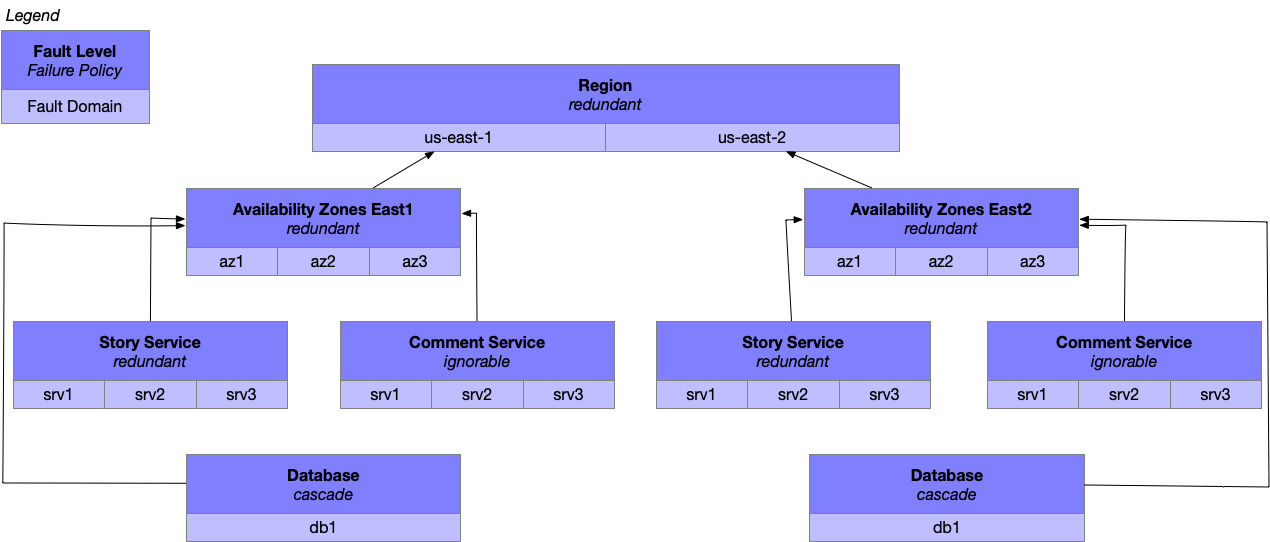
Describing fault domains.
Fault domains are one of the most useful concepts I’ve found in architecting reliable systems, and don’t get enough attention. If you want to make your software predictably reliable, including measuring your reliability risk, then it’s an extremely useful concept to spend some time with.
A fault domain is a collection of functionality, services or components with a shared single point of failure. A fault level is a set of one or more fault domains serving the same purpose, for example if you ran active-active across multiple AWS Regions, then “AWS Region” would be your fault level and the specific regions such as “us-east1” and “us-east2” would be your fault domains.
Each fault level exists within a fault hierarchy, where smaller fault levels (a database replica) nest under larger (a database cluster). This nesting allows larger levels to provide defense in depth against failures within those smaller levels.
Each fault level has one of three failure policies that describe the correct behavior when the level fails:
- redundant means that fault domains within the level can take over responsibility for a failed domain’s responsibilities. Some examples here are nodes in a Cassandra or Memcache cluster, or an architecture design that supports the loss of an AWS Availability Zone. (With one or fewer fault domains within a redundant level, it follows the behavior described below under the cascade policy.)
- ignorable requires that fault levels higher in the fault hierarchy can continue operating if this fault level fails. An example might be a website that can annotate stories with social actions by your friends, but which stops showing that social context if the database they’re stored in becomes unavailable, while continuing to render the remainder of the page.
- cascade warns that when this fault level fails, it is neither redundant nor ignorable, and consequently the fault level above it in the fault hierarchy must take responsibility for the failure. Any single point of failure is going to operate this way, for example a traditional MySQL setup without automated failover would cascade, as would a Cassandra cluster running with read-majority configuration which was no longer able to complete majority reads.
Ok, so now we have an interesting vocabulary, let’s play with it a bit.
It is a truth universally acknowledged, that an article about distributed systems must be in want of a summary section about CAP and ACID, so I wrote one here.
h/t to bobby, doug and westen for these ideas.
Example: social news website
Let’s start by working through an example of applying these ideas to an application, using the example of a social news website such as Reddit or Digg running on Amazon Web Services.
When you’re prototyping the application without much user traffic, your initial setup probably has two components: the web server rendering pages and a database storing data to be rendered.
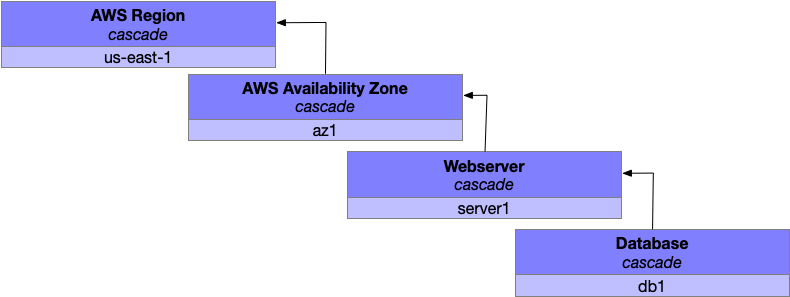
Those two components translate into four fault levels (database, webserver, availabilty zone, region) each of which is composed of a fragile singleton fault domain which will cascade upwards on failure. In this configuration, any failure in any fault level will result in the entire fault hierarchy failing.
That doesn’t sound great, so your next step would be to find the easiest fix to the most problematic fault level, which for most companies means running a number of webservers spread across a number of availability zones. This would allow your webserver to survive one of its fault domains failing, and even to survive the failing of an availability zone.
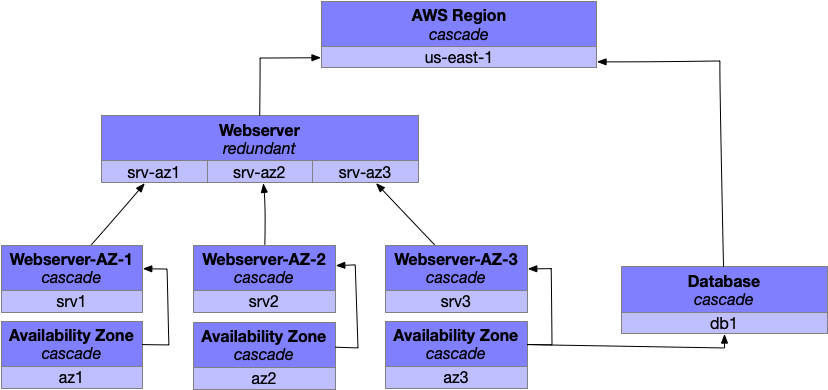
This introduces several new fault levels, specifically a new fault level for each availability zone and another for each zone’s web servers. Each of those new levels cascades upwards to a webserver fault level, which is no longer a cascading fault level but instead a redundant fault level. If one of the fault domains within webserver fails, the other two fault domains will continue to function and stop the failure from propagating up the hierarchy. (If all three zones fail, then yah, you’re still hosed.)
On the other hand, our database is still exposed to the failure of a single availability zone, which is pretty undesirable. You could move to a highly available database configuration using, say, Cassandra which would allow you to be resilient to any availability zone failure.
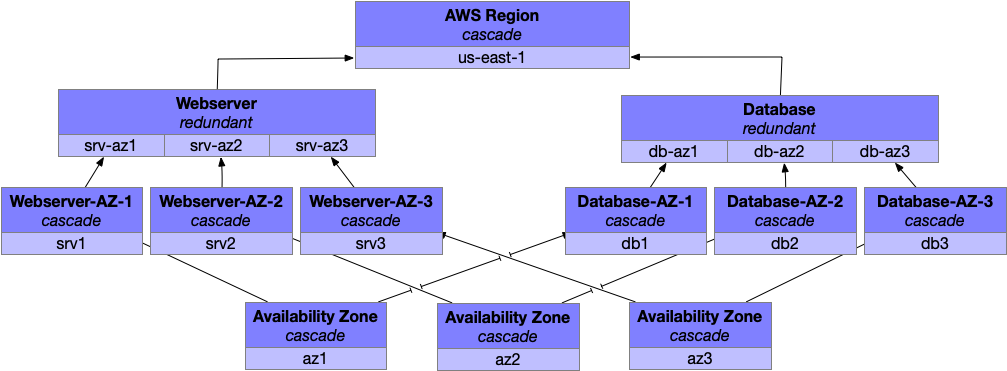
Now you’re in a pretty solid place, although the work is never done. You can always add more fault levels to the top (that cascading AWS Region is looking a bit intimidating now), and even adding more at the bottom is quite valuable as failure rates begin to increase.
Shouldn’t the arrows go the other way?
As I’ve drawn more and more of these fault hierarchy diagrams, I’ve come to believe that lines can be justified flowing in almost any direction, and either direction is surprising to some readers.
The guiding principle I use for directing arrows is that smaller fault levels should point in the direction that they cascade. If you have two fault domains, and one can fail without the other failing, then the one that can survive the others failure is the “parent level” and the line should point towards the parent.
Conversely, if two fault levels are mutually failing (e.g. if either level fails then the other fails), then it’s fine to point the arrows either direction: both directions will help you properly reason about the underlying systems.
Why bother with small fault levels?
Once you have a redundant fault level in the higher reaches of your fault hierarchy, a common question is whether it’s worthwhile to invest in making lower fault levels redundant. Each redundant fault level masks the failures of lower levels, so this is a pretty good question.
There are two reasons why you should continue investing across your fault levels:
- even within ignorable and redundant fault levels, it’s quite common that there is a short but noticeable degradation when a fault domain fails. (For example, failing over from a primary to secondary database might take you fifteen seconds, which is short enough to argue that you have redundancy, but long enough that it impacts your users.)
- the fault domains at a higher level can mask a failure within the contained levels, but if you imagine your three availability zones, then you can only tolerate three concurrent failures across all your contained fault levels which isn’t a lot when you start to consider a sufficiently large and complex system. By having layers of redundancy you’re better able to weather those unexpected moments of concurrent unrelated failures.
Putting those together, you absolutely do need a few large redundant fault levels, but you’re still at considerable risk if you don’t invest across the entire hierarchy.
Hierarchy violations
A common challenge with fault levels is hierarchy violations, where higher fault levels are subtly dependent on lower levels. A great example of this would be moving to a multi-region setup but in a way where your database replication scheme makes the database cluster a higher fault level than the regions, such that a cluster failure brings down all regions. Oops.
The way to ensure you’ve not committed hierarchy violations is to routinely exercise each of your fault levels, particularly the levels which are the core of your redundancy. If you’re not exercising each of those levels frequently, then you’ll introduce hierarchy violations that cause surprising cascading failures.
Architecture reviews are another somewhat effective mechanism for reducing hierarchy violations, but depend on humans being consistently perfect, which is rarely a long-term success strategy.
Measuring reliability risk
A final use for fault levels is they can be an effective approach for measuring the unmeasurable, at least for reliability.
Once you have your fault hierarchy, you’re able to articulate how many cascading levels you have, each of which represents a source of reliability risk, tracking that number is the first aspect of measuring your overall reliability (essentially tracking single points of failure in a structured way).
The second piece is measuring the frequency at which you’re exercising each of your redundant and ignorable fault levels. If they haven’t been exercised recently, they’re likely not to work properly.
Combining those two, you get a pretty useful score to measure your reliability over time: how many cascading fault levels do you have, and how long since you exercised your redundant fault levels?
This moves you away from the challenges of measuring nines of uptime, etc, which are output metrics that can be the result of luck rather than effective planning, and towards measures that you can directly invest into and impact.
If you’re not using fault domains to reason about your software, then I recommend taking a few days to sketch out your initial fault hierarchy, and in particular understand the policies for each domain and examine your hierarchy violations. This will give you a much clearer understanding of your risk than you previously had, the ability to measure progress, and some much needed perspective.