Thoughts on Envoy's Design
A couple days ago Lyft released Envoy, which is a pretty exciting take on a layer 7 proxy. This is an area that I’ve been thinking about a fair amount, both in terms of rolling out widespread quality of service, as well as request routing in heavily polyglot environments.
Before getting into my thoughts, let’s take a quick recap of common load balancing strategies.
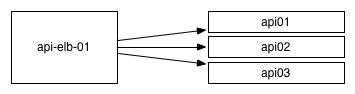
Historically, the most common approach to load balancing was to use a centralized load balancer of some kind and to route all traffic to it. These LBs can be done at a per-service level like ELBs, or can be very sophisticated hardware like F5s.
Increasingly these seem to be going out of style.
In part due to their cost and complexity, but my take is that their lack of popularity is more driven by a lack of flexiblity and control. As a programmer, it’s relatively intuitive to programmatically manage HAProxy, in a way that most centralized load balancers don’t offer. (And it’s not even that easy to manage HAProxy programmatically, although it’s making steady progress.)
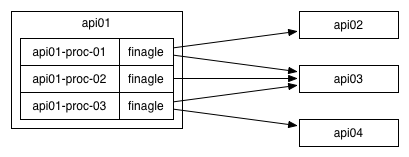
On the other end of the continuum, there is per-process load balancing like Finagle, where each one of your processes maintains its own health-checking and routing tables. This tends to allow a truly epic level of customization and control, but requires that you solve the fairly intimidating domain of library management.
For companies who are operating in one language or runtime, typically the JVM, and who are operating from a monorepo, the challenges of library management are pretty tractable. For most everyone else–those with three or more languages or with service per repo–these problems require very significant ecosystem investment.
Some companies who are devoted to supporting many language and many repositories (like Netflix, Uber) are slowly building the infrastructure to make it possible, but in general this isn’t a problem you want to take on, which has been the prime motivation to develop the sidecar approach.
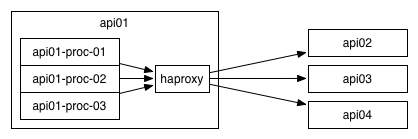
The sidecar model is to have a process running per server, and to have all processes on a server communicate through that local process. Many companies–including any company that ever hired a Digg systems engineer–have been running HAProxy in this mode for quite a while, and it gives a good combination of allowing flexibility without requiring that you solve the library management problem.
One of the downsides of the sidecar router has traditionally been poor support for anything other than HTTP/1.0 and HTTP/1.1, and very few options which are both high performance and highly customizable (HAProxy has amazing performance but becomes fairly brittle as you try to do more sophisticated things).
That is where Envoy fits in.
Ok! So, let’s start with the stuff that Envoy does really well.
First, the docs are simply excellent. They do a wonderful job in particular of explaining the high-level architecture and giving a sense of the design constraints which steered them towards that architecture. I imagine it was a hard discussion to decide to delay releasing the project until the documentation was polished to this state, but I’m really glad they did.
The approach to supporting ratelimiting is also great. So many systems require adopting their ecosystem of supporting tools (Kafka, requiring that you also roll out Zookeeper, is a good example of this), but Envoy defines a GRPC interface that a ratelimiting server needs to provide, and thus abstracts itself from the details of how ratelimiting is implemented. I’d love to see more systems take this approach to allow greater interoperability. (Very long term, I look forward to a future where we have shared standard interfaces for common functionality like ratelimiting, updating routing tables, login, tracing, and so on.)
Using asynchronous DNS resolution is a very clever design decision as well.
Synchronous DNS resolution can be slow, but also means if your DNS resolution
becomes unavailable (which has absolutely happened to me a number of times,
mostly with bind saturating its CPU core) then you’ll continue routing to the
last known response. This approach also allows you to avoid learning the
intricacies of your various languages’ DNS resolvers, which turn out to be
incorrect or unavailable in excitingly unique ways.
Hot restart using a unix domain socket is interesting as well, in particular how containers have become a first-class design constraint. Instead of something hacked on later, “How will this work with container deployment?” is asked at the start of new system design!
For a long time it felt like Thrift was the front-running IDL, but lately it’s hard to argue with GRPC: it has good language support and the decision to build on HTTP/2 means it has been able to introduce streaming bidirectional communication as a foundational building block for services. It’s very exciting to see Envoy betting on GRPC in a way which will reduce the overhead of adopting GRPC and HTTP/2 for companies which are already running sidecar routers.
All of those excellent things aside, I think what’s most interesting is the possibility of a broader ecosystem developing on top of the HTTP and TCP filter mechanisms. The approach seems sufficiently generalized that someone will be able to add more protocols and to customize behavior to their needs (to trade out the centralized ratelimiting for a local ratelimiter or the local circuit breaker for a centralized circuit breaker, etc).
You can imagine an ecosystem with MySQL and PostgreSQL protocol aware TCP filters, a more comprehensive suite of back pressure tooling for latency injection, global circuit breaking along the lines of Hystrix (would be pretty amazing to integrate with Hystrix’s dashboard versus needing to recreate something similar), and even the ability to manually block specific IPs to provide easier protection from badly behaving clients (certainly not at the level of a DDoS, rather a runaway script or some such).
In terms of a specific example of a gap in the initial offering, my experience is that distributed healthchecking–even with local caching of health check results–is too expensive at some scale (as a shot in the dark, let’s say somewhere around the scale of 10,000 servers with 10 services per server). Providing a centralized healthcheck cache would be an extremely valuable extension to Envoy for very large-scale deployments. (Many people will never run into this issue, either due to not needing that many servers and services, or because you scope your failure zones to something smaller. It’s probably true that a proactive engineering team with enough resources would never need this functionality. If someone does want to take a stab at this, the RAFT protocol has some pretty nice thoughts around decentralized health checking.)
One other quick thought is that I don’t see any coverage of the concept of checking identity in addition to checking health. Bad deploys and bad configuration can sometimes end up with a service running in an unexpected place, and in the worst case that unexpected place is the expected place for some unrelated process. Ideally your load balancer can ask your service to identify itself (both some kind of unique identifier along with its version), helping avoid some very specific and very confusing to debug scenarios.
Altogether, it feels like discovery and routing is becoming a very busy space as the most interesting ideas from Twitter and Google become mainstream, and I’m very excited to see Envoy make its mark.
As always, I’m very interested to hear your thoughts about load balancing, proxying and reliability! Send me an email (email is in the top-right column), or tweet me @lethain.