Foundation of collaboration (with an LLM to use a book)
There are many things that LLMs are not particularly good at, and generating a great engineering strategy is one of them. If you ask an LLM to generate your company’s engineering strategy, I’m quite confident you are going to be disappointed with what it generates.
However, I am extremely confident that an LLM is already an excellent companion to help you develop an effective engineering strategy. Used thoughtfully, an LLM can generate and analyze systems models, help you in each step of writing, and point out the areas your strategy needs to be reinforced. This companion will walk you through the techniques to accomplish each of those things, starting with this chapter which walks through configuring an environment to collaborate with Crafting Engineering Strategy and an LLM of your choice.
In this chapter we’ll cover
- Practices for prompting an LLM effective, including meta-prompting, and in-context learning
- Working with large corpuses, like this book, with an LLM, from Claude projects
to the
llmlibrary. - Providing tools to LLMs via the Model Context Protocol (MCP) servers. These tools extend what the LLM can accomplish by offering new capabilities such as web search or document retrieval
After working through these foundations, we’ll be ready for the following chapters where we use Crafting Engineering Strategy as a co-pilot for creating strategies.
This is a draft chapter from the The AI Companion to Crafting Engineering Strategy, which discusses how to use Crafting Engineering Strategy in an LLM to draft, refine, and improve engineering strategies.
Prompting LLMs effectively
If you want thorough coverage of working with LLMs, then I’d recommend Chip Huyen’s AI Engineering: Building Applications with Foundation Models. However, most folks are getting started with LLMs by building their intuition chatting with them directly, which I’ve found rather effective. On the assumption that you’ve spent some time using LLMs already, I will limit myself to emphasizing three particularly valuable techniques: thinking of your LLM as a newly hired intern, improving prompts via meta prompting, and using in-context learning (such as Crafting Engineering Strategy example strategies) to improve output.
LLM-as-Intern
The closest reference point most folks have for prompting is using a search engine like Google.
Search indexes are powerful creatures, and generally you can get exactly what you want by typing
in a few uncommon words related to your topic. Seasoned searchers might often know the resource
they want to retrieve the content from, for example reddit best restaurants sf.
However, LLMs generally don’t perform well with these sorts of terse prompts. For example, we can look at two prompts for creating a Python command-line tool that annotates a Markdown image with a description underneath it.
The first prompt uses the LLM-as-Search mental model, providing a very general prompt under the impression that you are retrieving the response from an existing data source:
I need a Python function to add images descriptions to Markdown.
Description should be in a paragraph tag beneath the image.
Using ChatGPT 4o, this generates a Python script, but it doesn’t really generate the right Python script.
This is evident solely from the function definition:
def add_image_descriptions(markdown_text, description_func=None):
...
I wanted a script that used the existing image definition within the Markdown image specification, but because I made a general query–as if I were retrieving an existing answer–I got the wrong thing entirely.
Now let’s try the second sort of prompt, this one taking a much more verbose approach, which I would describe as the LLM-as-Intern mental model. Here, you are providing very detailed instructions, as if you were writing a ticket for a newly hired intern for their first job writing software:
Write a Python3 function with the definition:
def add_image_descriptions(text: str) -> str:
This function should use Python's re library to extract the
description text for Markdown images, and add it as floating
text beneath the image, for example it should replace this:

With this:

<p>Initial sketch of API</p>
It should do that every every Markdown image in the text.
It should _not_ do that for any Markdown links that start
with [, only images which start with 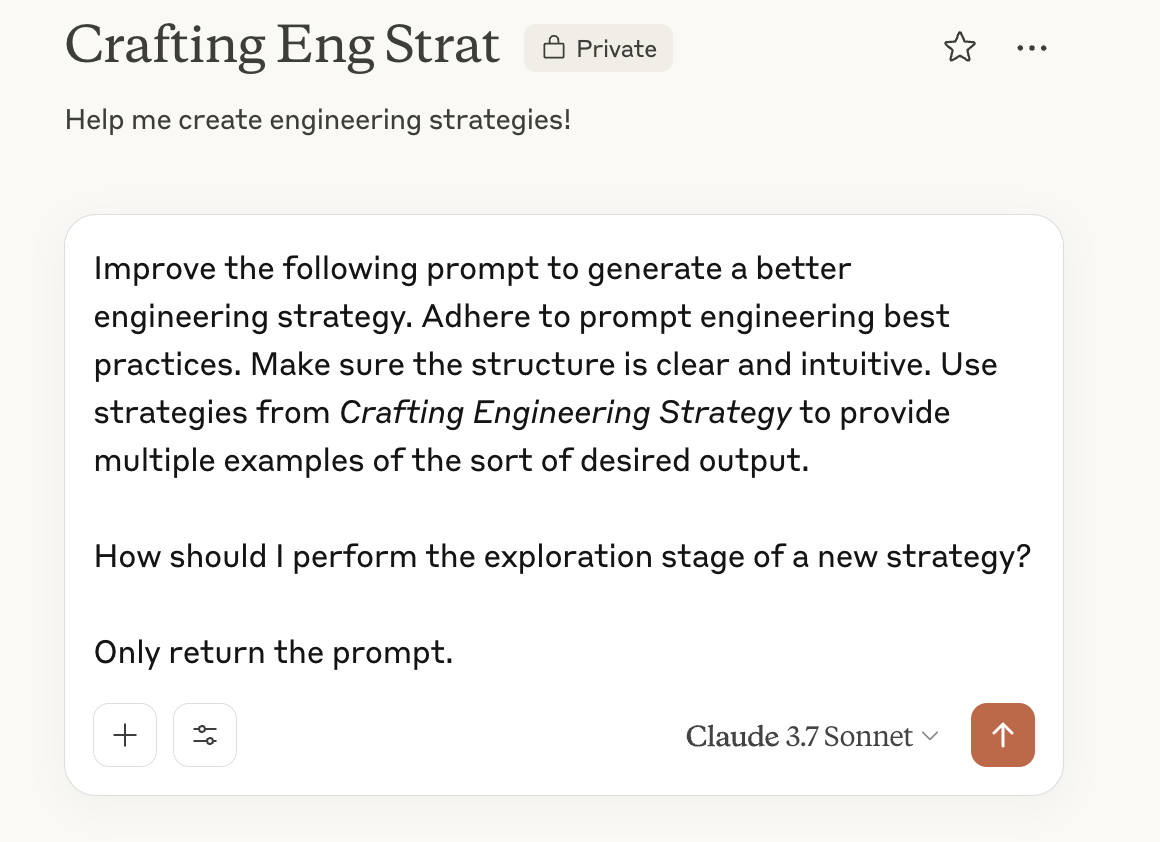
The meta prompt takes that simple initial prompt and turns it into a significantly more detailed prompt. Writing out all of those steps by hand would have taken a while, but no time at all with the appropriate meta prompt.

The meta prompt I developed here is an improvement, but still fairly basic. From this starting point, you should experiment with your own variations that work best for you.
In-Context Learning
The final technique I’ll discuss in this section is in-context learning (ICL), which is essentially providing a number of examples of what you want the LLM to generate for you. These examples help prime the LLM to understand exactly the sort of response you want. The more examples you include, the better the prompt will typically perform. As I’ve iterated on deploying LLMs into production systems, I’ve found that ICL solves most problems that meta prompting alone cannot solve.
You can use this book both to support generating ICL examples and then include those examples to better support generating your desired output. With the book in your context window, your prompt to generate examples can be straight forward, for example:
Provide 10 examples of diagnoses from Crafting Engineering Strategy's
example strategies.
Format them as a bulleted list of examples.
This will then generate a list of appropriate examples of diagnoses.

Once you have those examples, include them in your next prompt to improve the output it generates.
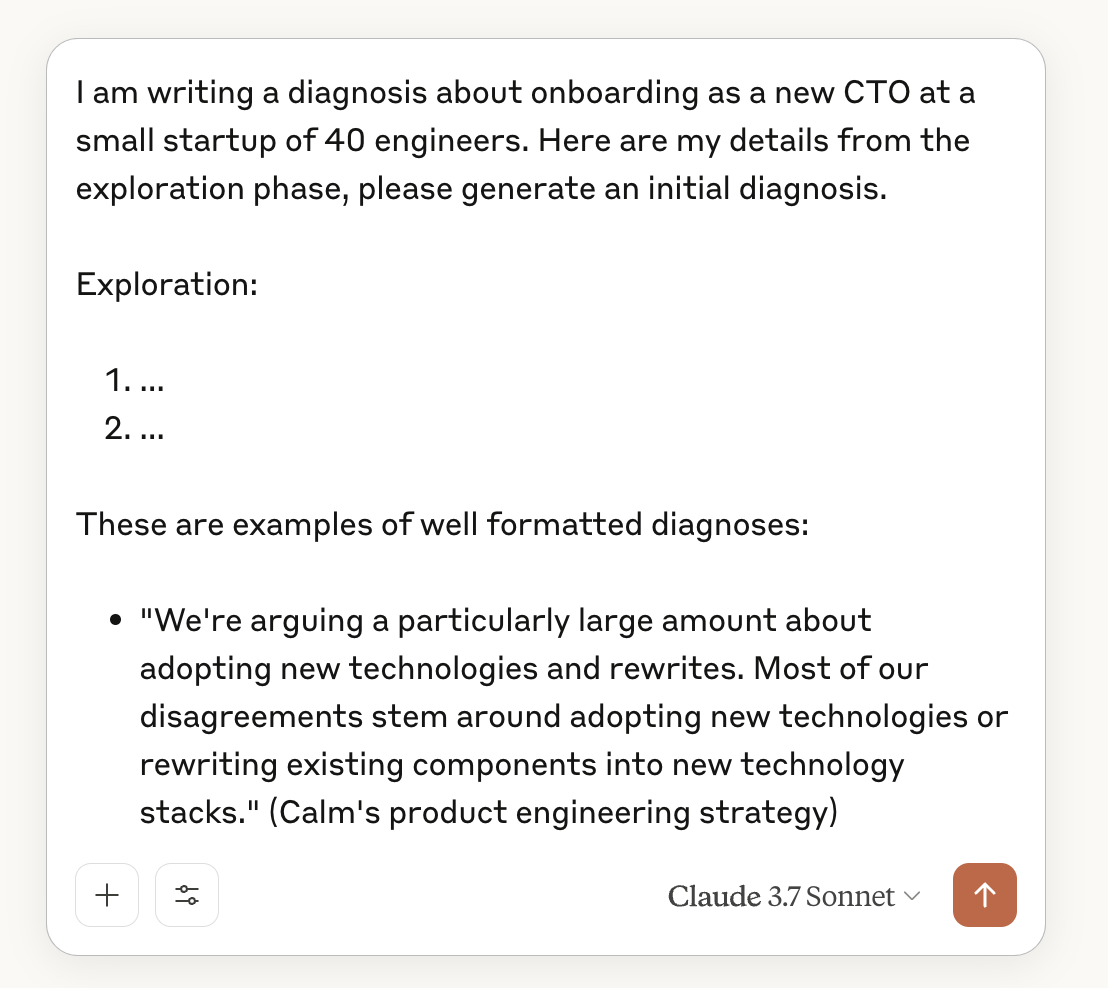
Note that the prompt shown here is sparse to improve readability. In practice, you’d likely want to apply meta prompting to improve this prompt as well.
Working with a book in an LLM
In order to follow along with this book’s examples,
you will need to setup an environment to prompt against the book.
While there are an infinite number of options,
here we’ll look at three setups:
using Anthropic’s Claude.ai Projects, using
OpenAI ChatGPT Projects, and using the llm library
with a model of your choosing (albeit restricted to models that
accept at least ~180k tokens in their input window, such as
most modern Gemini or Anthropic models, gpt-4.1-mini, and many others).
If you’re indifferent to which approach to use, I encourage using Claude.ai Projects as they work best with local Model Context Protocol (MCP) servers, which are discussed in the next section, but outside of MCP support all options are quite reasonable. Similarly, it’s reasonable to assume that MCP support will be widely available in the other environments in a relatively short timeframe.
Claude.ai Projects
In June 2024, Anthropic’s Claude.ai introduced the concept of Projects, which allow you to associate files with a project. These files are included in the Project’s chats’ context window, and at 200k tokens is large enough to support this book’s 170k tokens.
Get started by creating a Claude.ai account and navigating to the Projects page.
Once there, use the New Project button to create a new project.
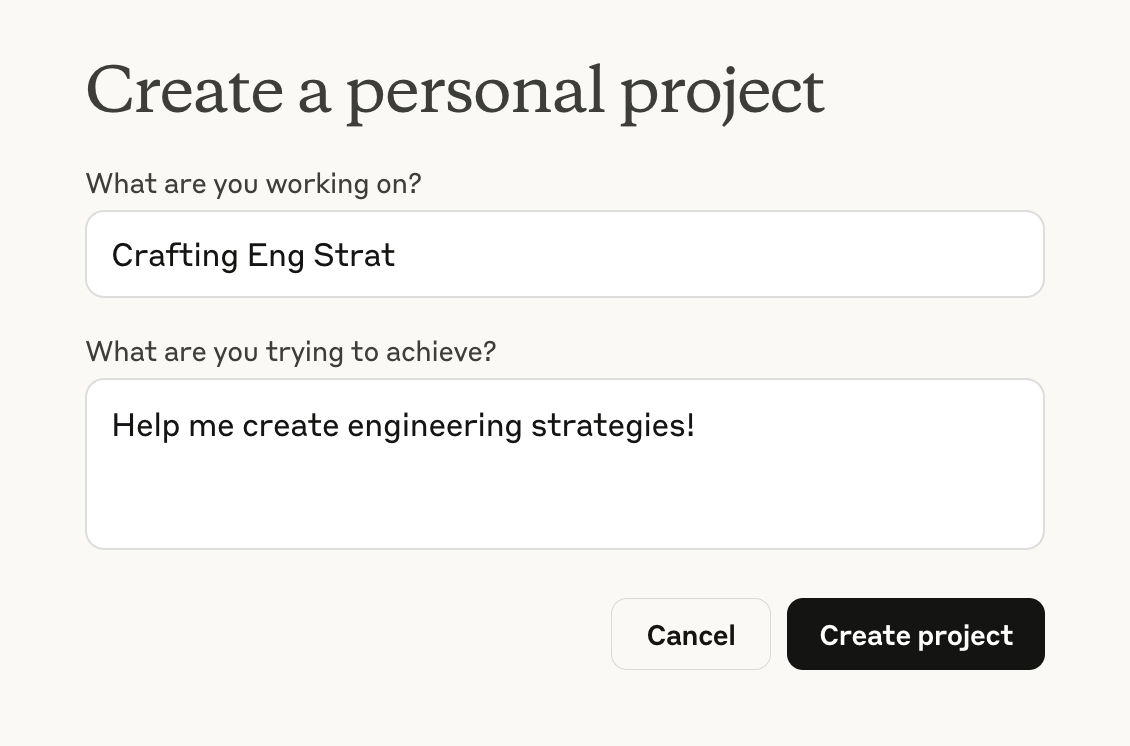
After selecting New Project, you will be shown a short form
to describe the project. Include a memorable name, e.g. “Crafting Eng Strat”
and optionally a short description.
After creating the project, you will be redirected to your new project. Then you’ll want to use the plus button to add a new file to the project.
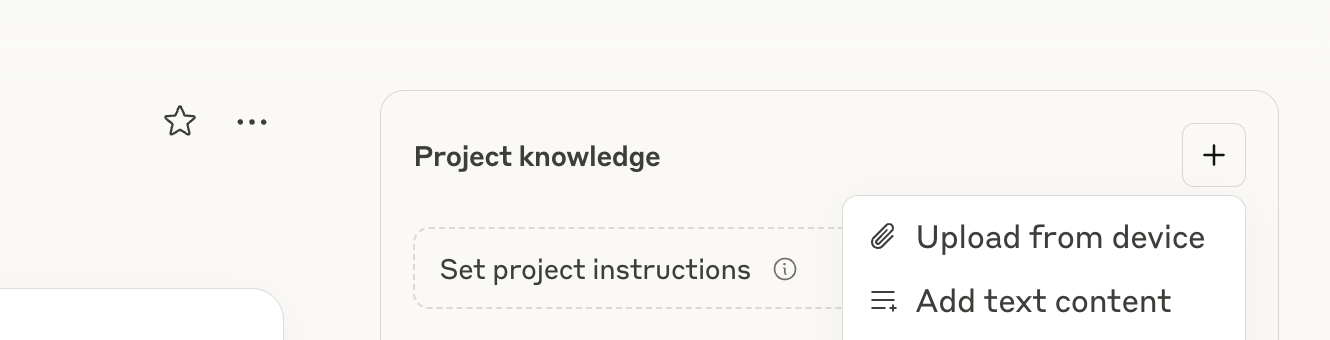
Select “Upload from device” and select the ces_llm.md file that you’ve already
retrieved following the Preface’s instructions.
After doing so, you’ll see that about 80% of your project’s capacity is taken
up by the book.
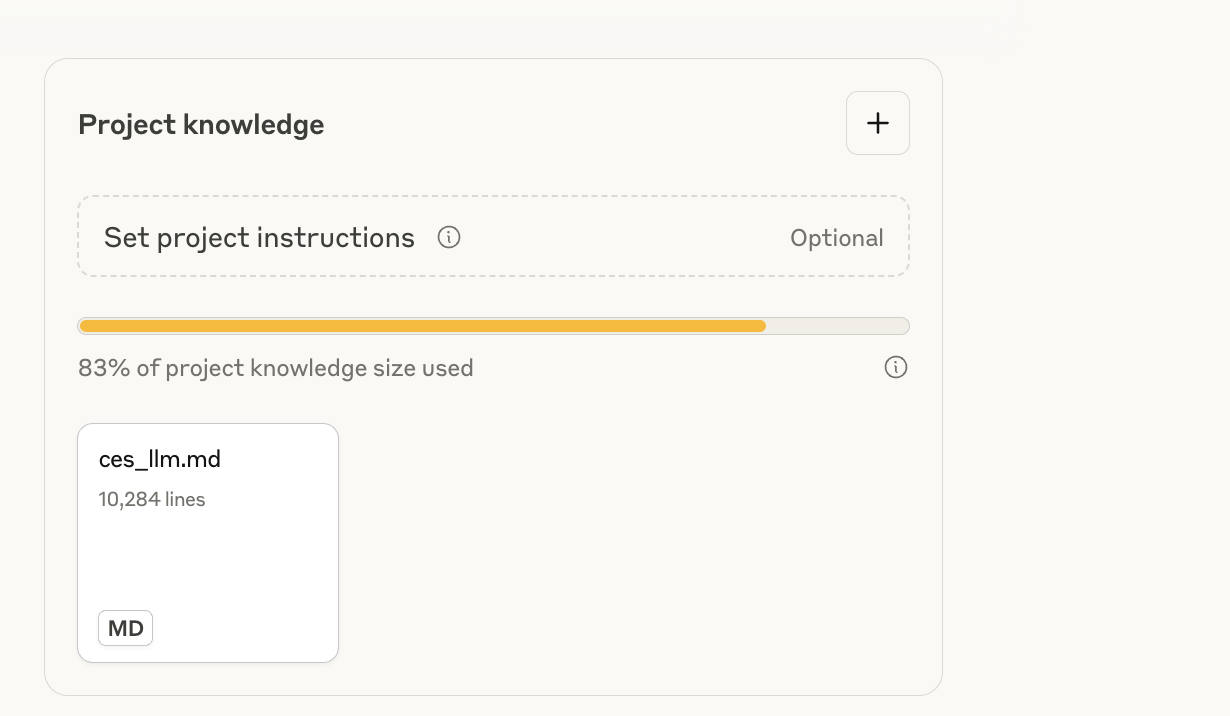
At this point, any prompt you run within the project will include the full context of the book in addition to the prompt that you add. This allows you to query the book directly.

At this point, you are ready to use this project to interact with the book as explored in subsequent chapters.
As a final note, it’s valuable to recognize that these projects are not performing Retrieval Augmented Generation (RAG), a technique which often uses search algorithms to select a subset of a corpus to include with your prompt. Instead, it is including the entirety of the book. Anything included in the book, ought to be accessible, even sections which might not semantically relate to your initial prompt.
ChatGPT Projects
Much like Claude.ai, ChatGPT has also introduced a Projects feature to allow interacting with a corpus of resources. It functions quite similarly to Claude.ai’s projects.
Get started by going to ChatGPT and logging in.
Note that at the time of writing, ChatGPT projects are available with any paid plan, but not on the free plan.
After logging in, click the New project button.
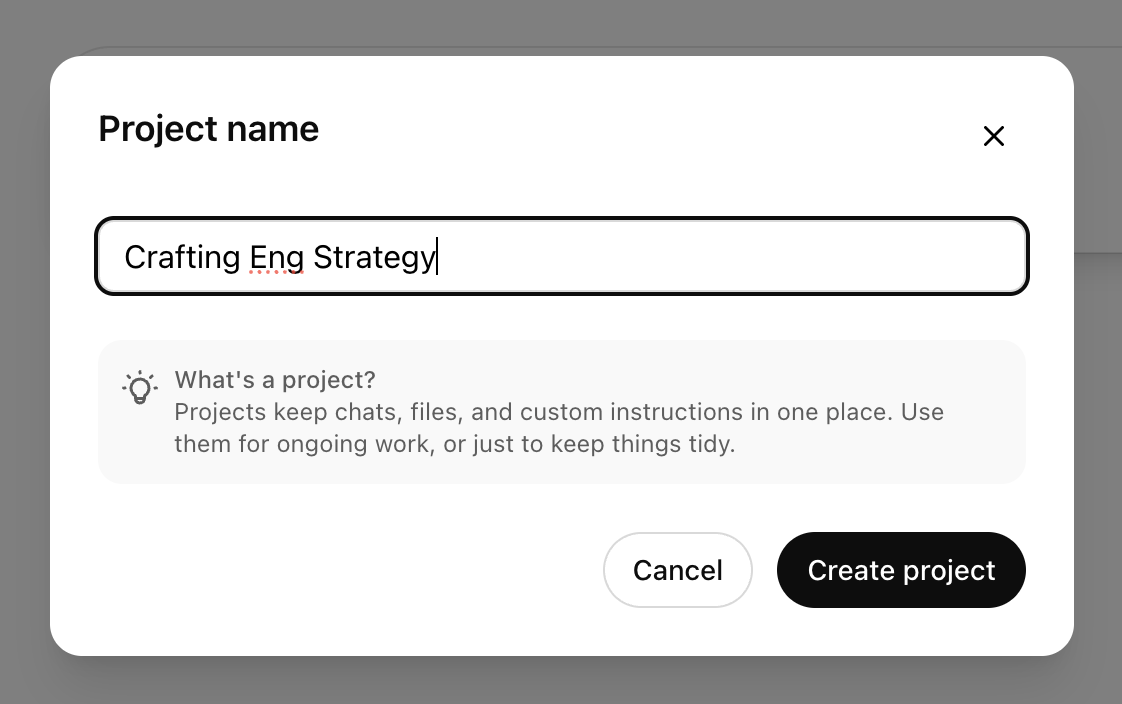
After clicking the “New project” button, you’ll be presented with a form
to provide a name for your project. Although you can use whatever name you
prefer, for this example I used Crafting Eng Strategy.
After you click the Create project button, you’ll be automatically redirected
to the new project’s page. On that page, you click the Add files button to upload
a copy of the book.
After clicking Add files, you’ll land on the Project files page which lists all
uploaded files. When there, you can use the Add files button or simply drag
your copy of ces_llm.md into the project. (Reminder, downloading ces_llm.md
is covered in the Preface.)
After uploading the file, you will get a warning that the large file may impact responses. This is a real concern. First, OpenAI models have token window limitations described in their documentation. Second, OpenAI has rate limits for some models which may restrict which models work for such a large project. You’ll be fine working with either GPT-4.1 mini or GPT-4o mini. Many other models will work as well, but some models might not.
At this point, you’re able to query the project including the entire uploaded book in the
context window. (Note that this prompt was performed using ChatGPT-4.1 mini.)

At this point, you have the ChatGPT project fully configured and are ready to query against it.
llm.py
Now that we’ve used the two UX-driven project interfaces,
we can also configure a project to use the llm
library via the command-line as a third configuration option.
While the examples here are specifically using OpenAI’s APIs, they would
work equally well with Anthropic, Gemini, or a self-hosted model.
You would just have to specify slightly different parameters for the model and API keys
in the command line.
Start by downloading your copy of the LLM-optimized
Crafting Engineering Strategy as discussed in the Preface.
These instructions will assume you’ve moved the copy into a file in the current
directory named ces_llm.md.
Then follow the llm library setup instructions.
I’ll rely on uv to manage installation,
but you’re welcome to use pip or any other Python package management.
Make sure you set your OpenAI API keys:
uvx llm keys set openai
Then run a short prompt to verify your setup:
uvx llm -m gpt-4.1-mini \
'what are the steps to write an engineering strategy?'
Assuming that works, now you’re ready to work with the book as well:
cat ./ces_llm.md | \
uvx llm -m gpt-4.1-mini \
'what are the steps to write an engineering strategy?'
This will include the entire book ahead of your prompt, and will provide a quite different response than the previous prompt without the book included.
Using tools via MCP
In the rare scenarios where meta prompting and in-context learning are insufficient to make a prompt work effectively, the final technique is providing purpose-built tools to your LLM that allow the LLM to do what it does best–manipulate textual representations–and push other sorts of complexity into the tool itself, especially tasks that require complex math or image rendering.
Two chapters in this companion dig into generating systems models with LLMs and generating Wardley maps with LLMs. Both include approaches that rely on using Model Context Protocol servers to access additional tools. Although all major LLM providers intend to support MCP servers in the future, as things stand today Claude Desktop is the only tool that provides straightforward support for allowing your project to interact with custom MCP servers.
The instructions at modelcontextprotocol.io/quickstart/user
are the best available for setting up your local Claude Desktop to use custom tools.
You can see similar instructions in the lethain/systems repository,
which is used in this companion’s chapter on generating systems models.
If you are wholly disinterested in running Claude Desktop, but do want to experiment with MCP servers, one other option to consider is the OpenAI Agents SDK. This will require writing custom code, but is the exact sort of code that an LLM is effective at writing if you include the relevant documentation in your prompt.
Summary
In this chapter, we’ve worked through three foundational prompting techniques to make your prompts more effective: LLM-as-Intern, meta prompting, and in-context learning. We’ve also worked through three different viable setups for interacting with large context windows, including the LLM-optimized format of Crafting Engineering Strategy.
With a configured environment, you’re now ready to move on to improving strategy with your LLM copilot.