Building a Software Deployment Pipeline
When the engineering team at Digg was acquired into SocialCode, we had a generous supply of technical and cultural puzzles to think through, but the most immediate challenge was scaling process for an engineering team whose membership doubled overnight.
While I’ve argued that service oriented architectures are for scaling people, they probably aren’t the mechanism of first resort for scaling your team and process. A reproducible deployment pipeline is your first and best tool for scaling an engineering team.
A great deployment pipeline:
- lets a new hire deploy to production on their first day,
- stops a bad changeset before it reaches your clients,
- replaces deployment mysticism with a mundane, predictable system,
- speeds up development.
Well, what does that look like?
[TOC]
The Toolchain
Our approach is going to require a handful of tools:
- a repository for your code (git, hg, …),
- a mechanism for code review, with hooks (gerrit, bitbucket, github, …),
- a build server or service (Jenkins, Travis CI, …),
- a mechanism for moving the code to your servers (chef, clusto, …).

The combination of tools you choose will have a significant impact, but any selection will be able to support a reasonable deployment pipeline. I’ve had great experience with Git, Github, Jenkins and Chef, and would recommend that as a good starting point.
(Gerrit is likely not a good starting point unless you own yak shears.)
The Submitter’s Workflow
Armed with those tools, let’s put ourselves in the shoes of an engineer looking to deploy their code to production. Their workflow looks like this (assuming for the moment that this particular change is non-controversial, and doesn’t break any tests):
- They develop the changes in a personal code repository.
- When ready for review, they push their changeset into the code review system, which automatically notifies their colleagues there is a new changeset ready for review.
- Once the code is reviewed, the submitter merges their changeset into the authoritative code repository.
- The build server emails once the changes are deployed to the alpha environment’s servers.
- The QA team or engineer checks a bit on the alpha environment, then clicks a button on the build server to deploy to staging.
- The build server emails once the changes are deployed in staging.
- They click another button and promote the code into production.
- When the build server notifies them their code is in production, they validate all is well in the production environment.
- Success.
The submitter’s gift of time and attention to this deployment is fairly minimal, and just as importantly they are straightforward actions that require neither exceptional displays of judgement nor feats of memorization.
The Toolchain’s Workflow
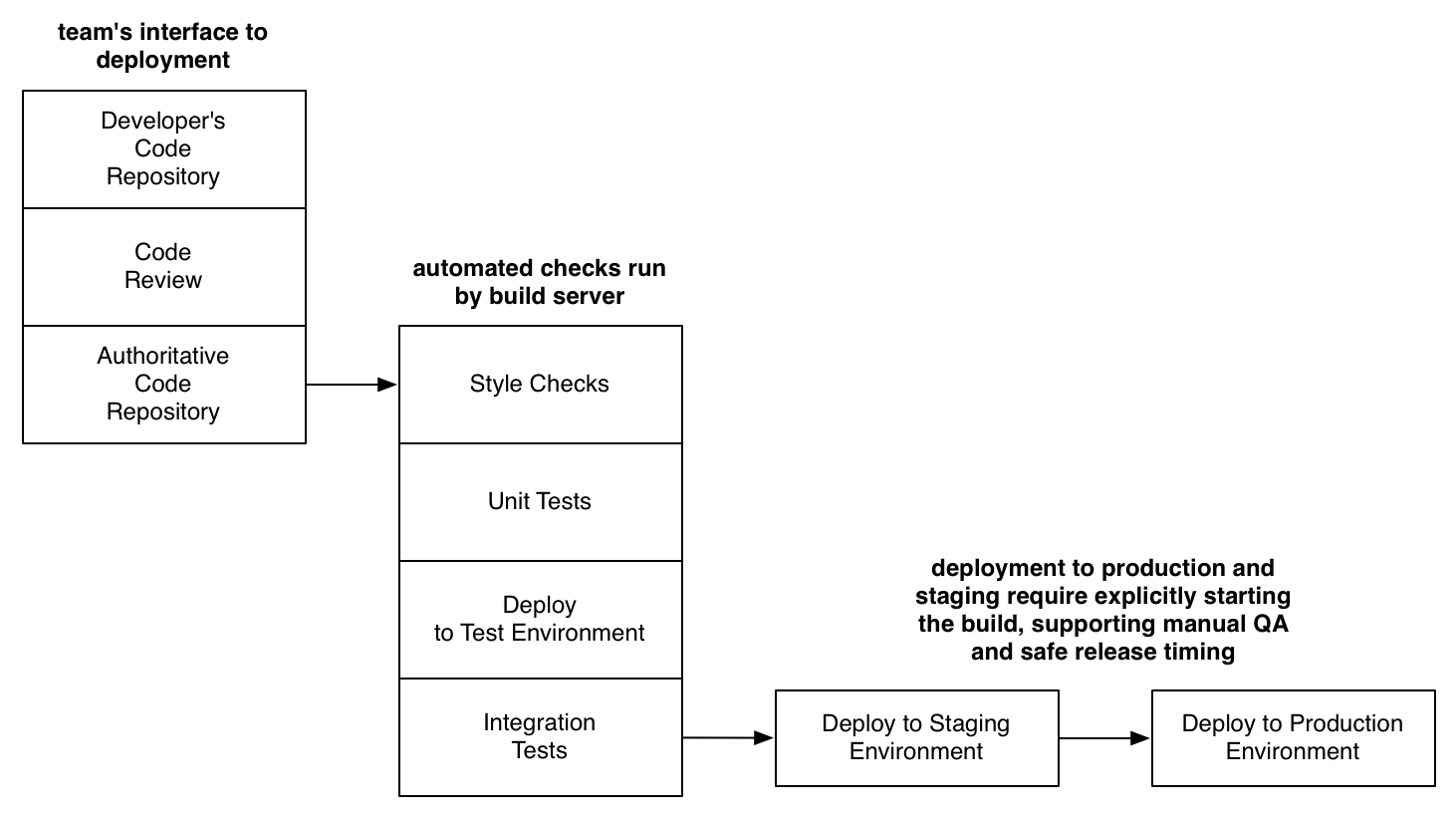
Now, let’s look at the same flow from the tool’s perspective:
- The code review tool receives changes and notifies the team.
- Once the code review is finished, the code review tool merges the changes into the
alphabranch. - The build server detects new changes on
alphaand:- runs a syntax and style checker,
- runs unit tests,
- notifies the server config tool to deploy
alphato alpha servers, - after deployment, runs integration tests against alpha.
- When someone manually triggers the staging build:
- merges
alphaintostaging, - notifies the server config tool to deploy
stagingto staging servers, - after deployment, runs integration tests against staging.
- merges
- When someone manually triggers the production build:
- merges
stagingintoproduction, - notifies the server config tool to deploy
productionto prod servers, - after deployment, runs integration tests against production.
- merges
- Success.
Each step taken by the toolchain is a step that an engineer no longer needs to perform, as well as steps they can neither screw up, omit or forget. This is how deployment pipelines improve predictability while also increasing developer throughput.
Managing Speed Versus Safety Tradeoffs
As your team and organization grows, things will change in ways you can’t productively anticipate: you may decide that you need a manual QA team, you may adopt a different programming language, you may move to static JavaScript frontends with separate codebases, or a dozen other things.
Your deployment pipeline needs to be able to handle that unknowable future.
You can layer in additional tools and manage your speed versus safety tradeoff through these mechanisms:
- A small and experienced team could skip code review and merge directly into the authoritative code repository.
- Each build can pick the tools it enables:
- Each project has a distinct build for each environment, allowing you to run different validations
depending on:
- the environment you’re deploying to (perhaps only run tests on changed files for alpha, but run the full test suite before merging to the staging environment),
- the project: an internal only tool might not need much validation.
- Having three environments (alpha, staging, production) is fairly common but also fairly arbitrary. A rule of thumb: if you have more than three engineers you probably want two environments, and if you have manual QA or want to stagger production releases by more than a couple days, then you probably want three environments.
- The transitions from alpha to staging and from staging to production can be automatic. Making the transitions manual offers more control of launch timing and also facilitates manual testing, but the choice is yours!
With a build server like Jenkins, your build is just a script which is executed when certain conditions are met, giving you a great deal of flexibility to optimize for your circumstances. As such, limitations are mostly those of imagination… or because your build server is still running Ubuntu 12.04.
Additional Tips and Commentary
Here are some additional thoughts which don’t merit a full section:
- When should you add a deployment pipeline? If you’re a small founding team of two or three engineers, and especially if none of you are particularly comfortable with system administration, then the overhead of maintaining the pipeline may be high enough to overshadow the benefits. Once you start hiring non-founding engineers, it’s probably time to take the dive.
- What about bypassing safeguards for urgent and emergency pushes? The normal pathway for deployment should be the optimal pathway especially during a moment of urgency. If it isn’t, reflect on how you need to adjust your deployment so that is true. (You’ve probably become acclimatized to a significant performance problem in your current build pipeline, or your unit tests are written in such a way that they are dependent on external resources. Both of those are bad and worthy of fixing.)
- Why not continuous deployment? This approach uses continuous deployment to the alpha environment, but then requires manual approval before going further. Experience suggests that coupling merging code and deployment to production validates the quality of your tests in the most unpleasant way possible. (If the guilty party went home in the interim, this also does an excellent job of identifying veins in your coworkers’ foreheads.)
- An unexpected benefit of automated builds is reducing your obligation to provide syntax and style feedback, which can make both you and the person you’re giving feedback to question their chosen profession. Instead, you rely on the build server to be pedantic, which—as a soulless automaton—it does extremely well.
The deployment pipeline I’ve described here is basic, and ripe for improvement, but having witnessed the impact of rolling out a pleasant deployment pipeline, it’s absolutely the first thing on my checklist for scaling out a team and improving engineers' quality of life.
Well, hopefully there are some useful tidbits here, and as always I’m interested to hear suggestions and alternative approaches!