Async processing with sync semantics?
Lately I’ve been thinking more about kappa architectures, and particularly how you’d design a moderately complicated web application to rely exclusively on an immutable log, with log processors that managed materialized views.
Some of the interesting questions are:
- is there a good way to do this?
- can you do it without tight coupling of implementations between the processes that publish the events and those that process the events?
- is there a way for publishers to be unaware of write logic and to provide synchronous behavior?
This seemed like a good time to learn how to use docker-compose, so I spent some time over the weekend playing around with a simple cluster of Docker containers running Kafka, Redis and Python processes. The code and docker configs are in Github, and below are some notes/thoughts.
Synchronous
First, I put together a base case of a Python app writing to Redis.

The sequence diagram is pretty simple.
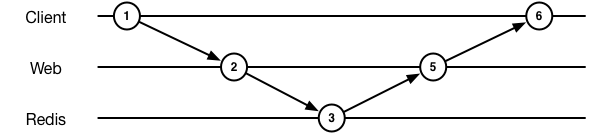
A slightly simplified version (real version here) looks like:
@app.route('/<path:path>')
def hello(path):
r = redis.Redis(host='redis')
ts = int(time.time())
r.zadd(RECENT_KEY, path, ts)
r.zincrby(TOP_KEY, path, 1)
recent = r.zrange(RECENT_KEY, 0, 10, desc=True, withscores=True)
top = r.zrange(TOP_KEY, 0, 10, desc=True, withscores=True)
now = datetime.datetime.now()
return render_template('index.html', path=path, recent=recent,
top=top, elapsed=elapsed, now=now)
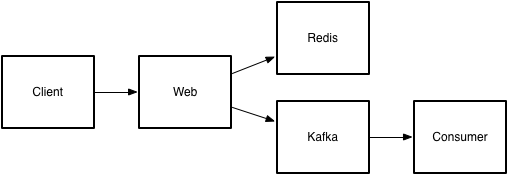
This works well! Logic is contained in a single place, but we’re mutating state directly and don’t have a log of events. It’s easy to add an event log (real func):
publish(client, VIEW_TOPIC, path)
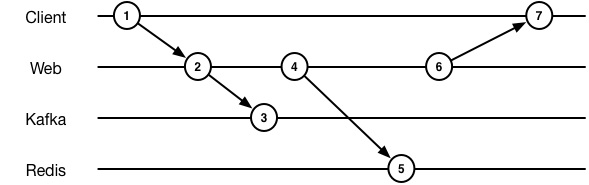
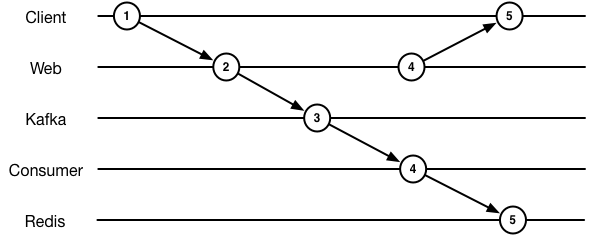
At which point our diagram gets a little more interesting:
But still pretty simple, with synchronous operations.
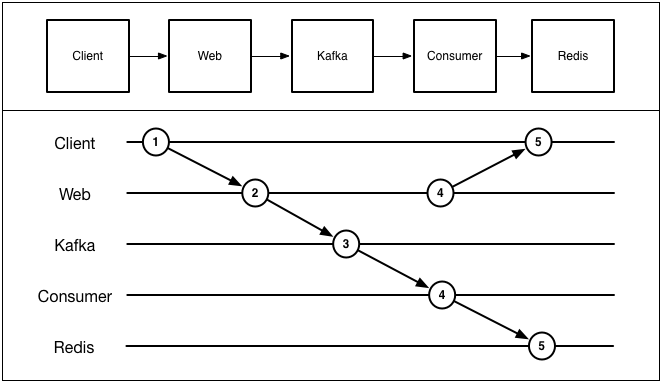
Now we do have an event log, but state is not being generated from it. This means we can’t recreate state from replaying the log, which defeats the entire point. (Although at least it would get the data into your data ecosystem for processing later!)
Asynchronous
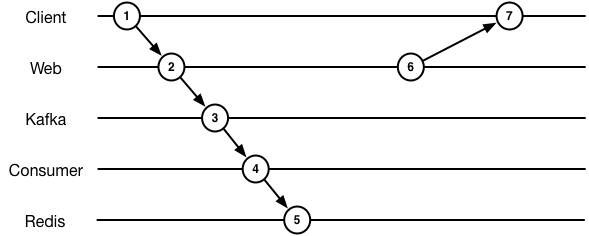
The simplest way to move into a world with an event log that is computed into data is to move all processing into a consumer.

This is simple, but we can no longer sequence our response to the client
to ensure it happens after we’ve finished processing.
Now the web app is:
@app.route('/<path:path>')
def hello(path):
publish(client, VIEW_TOPIC, path)
r = redis.Redis(host='redis')
recent = r.zrange(RECENT_KEY, 0, 10, desc=True, withscores=True)
top = r.zrange(TOP_KEY, 0, 10, desc=True, withscores=True)
now = datetime.datetime.now()
return render_template('index.html', path=path, recent=recent,
top=top, elapsed=elapsed, now=now)
And the write logic is moved into a kafka consumer:
cli = get_client()
topic = cli.topics[VIEW_TOPIC]
consumer = topic.get_simple_consumer(reset_offset_on_start=True,
queued_max_messages=1)
for message in consumer:
path = message.value.decode('utf-8')
r = redis.Redis(host='redis')
ts = int(time.time())
r.zadd(RECENT_KEY, path, ts)
r.zincrby(TOP_KEY, path, 1)
Not only have we lost control over timing, we also have a fairly awkward scenario where read and write logic is split. We’ve picked up an exciting property of an immutable event log that we can replay to generate state, but the application no longer works properly and is more complicated to reason about.
Decoupled and synchronous
What we really want is the ability for the web process to behave synchronously from the client’s perspective until downstream processing has completed, without introducing any tight coupling.
Hmm, the rare case we want action at a distance?
You can think of implementation specific ways to do this, e.g. in this case you could use Redis pubsub and subscribe to a channel that acks writes for a given event. That’s an interesting step, but tightly couples implementation between the web and consumer processes, discounting some of the interesting advantages of the kappa architecture.
I’m honestly not aware of tooling that does what I want, but you could imagine a somewhat handwavy implementation along these lines:
websends message to asyncprocess.syncpushes intokafka, injecting a unique identifier into each message, and keeping the connection towebopen.Various
consumerprocesses “ack” completion back tosync.syncwould either have a manifest of consumers that should acknowledge (hopefully built from static analysis, rather than being manually maintained), or would sample system behavior to learn the expected number of acks.The idea of sampling feels a bit overdesigned, but in practice I think you’d want p99 timings which you’d use to fail-fast and move forward with processing. Actually, as an interesting hack, for a lightweight implementation, I imagine you could probably only rely on the p95 timings and not implement the “ack” at all.
The “ack” concept here can probably be viewed as a particular example of
the challenge of implementing back pressure in asynchronous processing.
For example, what you’re kind of hoping for is to synchronously block the
web process until all downstream consumers have processed all messages that
started due to messages at or before the time the message was published.
(This kind of reminds me of watermarks.)
Ending thoughts
Altogether, I think solving this problem–strongly decoupling implementations of publishers and consumers while allowing timing coordination–isn’t solved very well by any existing tools, but there aren’t any obvious reasons it couldn’t be, just a bit awkward today.
I imagine we’ll see some interesting experiments soon!