Ambush Code Review Learns Code Diffs
Today I spent a couple of hours reworking Ambush Code Review, and it's turned into something much better than the first implementation. There are two important changes:
- It's easier to use.
- It actually does something interesting.
Before, it was pretty awkward to post a response to a code snippet. I mean, I sure as hell knew how it worked, but I'm not sure if anyone else knew, and it was a pretty unhappy compromise anyway. Now, it's just two button clicks to update a posted snippet with your changes. But the really interesting new feature is that it now generates the diffs between different revisions of a snippet, and displays them beneath the current version of the snippet.
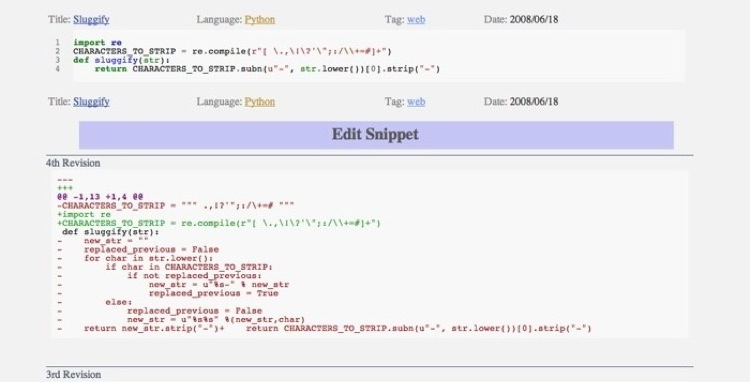
You can go take a look at the snippet that screenshot is from, and I think it turns out to be a pretty compelling feature, since the whole point of ACR is to make it easier for people to suggest improvements to snippets (for example, when people post snippets into an IRC chatroom looking for help, wouldn't it be nice to actually be able to show them how to fix it?).
I'd be glad to hear any responses, now that it's taken a step from being a shoddy me too service to something slightly more interesting.
Implementing the Code Diffs
Now for a quick discussion about implementing the diffs between different revisions. Things didn't quite go as expected, in the sense that it was easy in the places I thought it would be hard, and hard in the places where I thought it would be easy. Live and learn.
The easy part was actually generating the snippets themselves. The difflib module, part of the standard Python library, really makes this task trivial. The relevant code looks something like this (go here to improve upon this snippet, I'm kind of baffled about how to correctly handle the generator returned by the unified_diff function..):
from difflib import unified_diff
def set_content(self, new_content):
'Handles all details of updating snippet content.'
# if this is not a new Snippet
if self.rendered != None:
result = unified_diff(self.content.splitlines(1),
new_content.splitlines(1))
try:
txt = reduce(lambda a,b: u"%s%s" % (a,b), result)
self.add_diff(txt)
except TypeError:
pass
self.content = new_content
lexer = get_lexer_by_name(find_lexer(self.highlighter))
self.rendered = highlight(self.content,lexer,HtmlFormatter(linenos='table'))
Which is to say, that I don't really do anything at all to generate the code diffs, other than simply calling a module function. But things did get a little bit trickier afterwards.
The problem began because the db.ListProperty property used to describe a field in BigTable requires a type argument. Sure, no problem. And it requires that it be one of a specific list. Sure, tons of choices there, no problem. And it needs all the entries in one list to be of the same type. Hey, I only want to store diffs, so they'll all be the same, no problem. And it apparently ignores you when you set the db.Text property type and complains that unicode types can't store more than 500 bytes in the database. Well, thats a problem.
Instead, I jury-rigged my own list with some old style ingenuity and some new style obliviousness to the consequences. Using... simplejson to serialize and deserialize.
from django.utils import simplejson
def add_diff(self, diff):
if self.diffs == None:
diffs = []
else:
diffs = simplejson.loads(self.diffs)
diffs.insert(0, diff)
self.diffs = simplejson.dumps(diffs)
def get_diffs(self):
'Unserializes and returns the contents of self.diffs'
return simplejson.loads(self.diffs)
I wouldn't say that this is a brilliant solution, or even a good solution, but it is a good enough solution, which seems to be what web applications boil down to eventually. Hits to the database are minimized, and CPU is almost never the restrictive factor in web development. You may wonder why I went with simplejson instead of using pickle, and it turns out the answer is quite simple. As in, simplejson is very convenient to work with, and saved me from having to use a StringIO to mimic a file for pickle to serialize and deserialize with.
Hope this breakdown of the code was slightly interesting, and let me know if there are any questions.