Recurring Events and Message Passing
When working with asynchronous communication like Erlang actors and Clojure agents, one of my points of contemplation has been how does one schedule recurring events in asynchronous systems?
The simplest approach to recurring events is to use loop with a sleep statement inside,
import time
while True:
print("hello")
time.sleep(1)
but triggering your asynchronous system via an external script just doesn't feel quite right. What I really wanted was a mechanism for the asynchronous distributed system to maintain perpetual motion without external intrusion.
With a bit of time it's possible to come up with a number of perpetual asynchronous loops, which with a bit of tweaking can offer a variety of different properties.
The simplest of these perpetual motions is the ping-pong loop.
Ping Pong
In a system with only two actors, the actors can maintain perpetual motion by performing their action and then pinging the other actor.
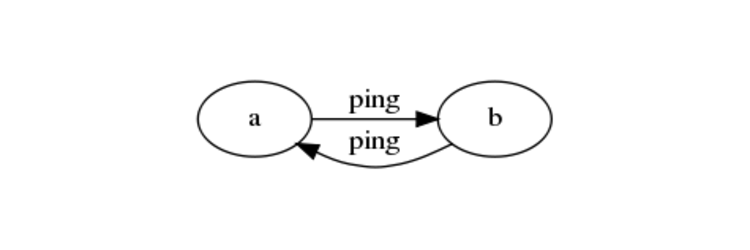
This approach benefits from being rather simple to implement, but in the end it's hard not to view it as an entirely artificial construct.
An Erlang implementation of Ping-Pong.
-module(ping).
-export([ping/1, test/0]).
ping(Delay) ->
receive
{ping, Target} ->
io:format("received ping from ~p…~n", [Target]),
timer:sleep(Delay),
Target ! {ping, self()},
ping(Delay)
end.
test() ->
A = spawn(ping, ping, [2500]),
B = spawn(ping, ping, [500]),
A ! {ping, B}.
A Clojure implementation of Ping-Pong
(defn ping [state]
(println "ping")
(. java.lang.Thread sleep (:delay state))
(send (:target state) ping)
state)
(def a (agent {:delay 1000, :target nil}))
(def b (agent {:delay 1000, :target a}))
(send a #(assoc % :target b))
(nil? (send a ping))
(Note that I wrap the final send with nil? because
the attempt to generate the print value of the send generates
an infinite loop as each agent has the other agent in its state,
and causes a stack overflow error.)
Circle
Although addressed separately, it's more accurate to think of ping-pong as a circle with two nodes. However, the circle is a bit more realistic than ping-pong as it accommodates a variable number of nodes.

The circle is a good mechanism for checking liveliness amongst many nodes, and also for ferrying updates across all nodes such that all nodes are guaranteed to eventually receive the latest data.
An Erlang implementation of Circle
-module(circle).
-export([ping/2, test/0]).
ping(Target, Delay) ->
receive
ping ->
io:format("~p pinged by ~p…~n", [self(), Target]),
timer:sleep(Delay),
Target ! ping,
ping(Target, Delay);
{target, NewTarget} ->
NewTarget ! ping,
ping(NewTarget, Delay)
end.
test() ->
A = spawn(circle, ping, [nil, 2500]),
B = spawn(circle, ping, [A, 500]),
C = spawn(circle, ping, [B, 1000]),
D = spawn(circle, ping, [C, 100]),
A ! {target, D}.
A Clojure implementation of Circle
(defn ping [state]
(println (str "ping " (:name state)))
(. java.lang.Thread sleep (:delay state))
(send (:target state) ping)
state)
(def a (agent {:delay 100, :target nil, :name "a"}))
(def b (agent {:delay 1000, :target a, :name "b"}))
(def c (agent {:delay 4000, :target b, :name "c"}))
(def d (agent {:delay 2000, :target c, :name "d"}))
(send a #(assoc % :target d))
(nil? (send a ping))
Coordinator
Breaking from the circle pattern, the coordinator centralizes the role of pinger, where only a single node needs to contain the logic for pinging out, and the other nodes simply listen for pings.
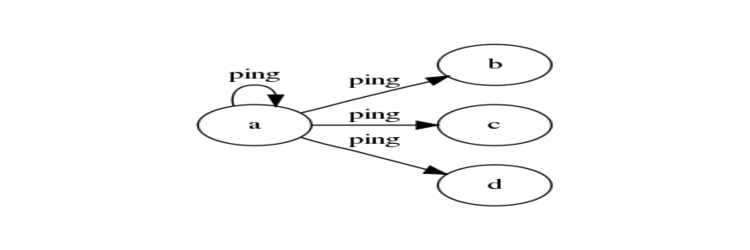
When your task only requires scheduling, then the coordinator is useful as it removes pinging logic from the majority of nodes, and also makes it possible to send heartbeats to all nodes at the same logical time (although when the receiving actors honors the ping may vary greatly). However, by default the coordinator lacks the data synchronization / update propagation aspects of the circle.
If update propagation was an essential feature, it would be possible to have all nodes ping the coordinator with updates, which the coordinator would broadcast every interval (with a guarantee that any update would be propagated to all nodes within two intervals of the time it was received).
An Erlang implementation of Coordinator
module(coordinator).
-export([coordinator/2, listener/0, test/0]).
listener() ->
receive
{ping, Sender} ->
io:format("~p received ping from pn", [self(), Sender]),
listener()
end.
coordinator(Targets, Delay) ->
receive
ping ->
lists:foreach(fun(X) ->
X ! {ping, self()}
end, Targets),
timer:sleep(Delay),
self() ! ping,
coordinator(Targets, Delay)
end.
test() ->
A = lists:map(fun(_) ->
spawn(coordinator, listener, [])
end, lists:seq(0, 10)),
B = spawn(coordinator, coordinator, [A, 1000]),
B ! ping.
A Clojure implementation of Coordinator
defn ping [state sender]
(println (str state " pinged by " (:name sender)))
state)
(defn coordinate [state]
(. java.lang.Thread sleep (:delay state))
(doseq [listener (:listeners state)]
(send listener ping state))
(send (:target state) coordinate)
state)
(def coord (agent {:delay 2500, :name "a"}))
(def listeners (list (agent "b") (agent "c")))
(send coord #(assoc (assoc % :target coord) :listeners listeners))
(nil? (send coord coordinate))
Gossip
The gossip approach has much in common with the circle, but with less rigidity, fewer guarantees and more resilience in the face of node failure.
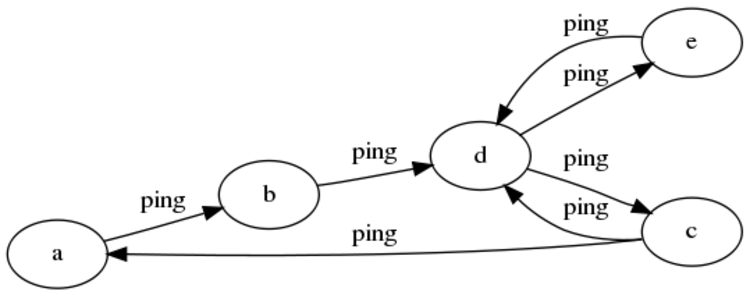
The graph begins at node C in the image above.
With gossip, when a node receives a ping, it picks another node to ping at random. To increase the rate of propagation (and to combat failure if a single node goes down), it is possible for nodes to notify several other nodes with each ping, but care must be taken to prevent the number of pings per interval from increasing.
This approach is useful because it can survive node loss, whereas the circle can't handle the loss of any nodes, and the coordinator is vulnerable to the loss of the pinging node.
More interesting than the overly simple gossip mechanism suggested here would be a combination of the coordinator and gossip. Each node would ping another random node, then ping itself and sleep for a period of time. While sleeping, nodes would receivie updates from other nodes who are also performing the same process. After waking up it would process pings from other nodes (actually, it would process only those pings received before it scheduled its ping, the rest would be processed after the ping was sent but before the subsequent ping is sent), and perform the same cycle once again.
An Erlang implementation of Gossip
-module(gossip).
-export([ping/1, test/0]).
ping(Delay) ->
receive
{ping, Sender, Targets} ->
io:format("~p received ping from ~p…~n", [Sender, self()]),
timer:sleep(Delay),
lists:nth(random:uniform(length(Targets)), Targets) ! {ping, self(), Targets},
ping(Delay)
end.
test() ->
Pids = lists:map(fun(_) ->
spawn(gossip, ping, [1000])
end, lists:seq(0, 10)),
hd(Pids) ! {ping, self(), Pids}.
A Clojure implementation of Gossip
(defn ping [state sender]
(println (str (:name state) " pinged by " (:name sender)))
(. java.lang.Thread sleep (:delay state))
(send (nth (:agents state)
(rand-int (count (:agents state)))) ping state)
state)
(def agents (doall (map #(agent {:name (str "agent_" %),
:delay 1000})
(range 0 10))))
(doseq [agent agents]
(send agent #(assoc % :agents agents)))
(nil? (send (first agents) ping {:name "start"}))
Ending Thoughts
It is possible to think of perpetually moving asynchronous systems as participating in a form of distributed tail recursion. The semantics may be more complicated than a while-loop, but the potential of these approaches are more interesting as well.
They can insulate the perpetual motion against single machine crash, as well as making it possible to have multiple timers running concurrently without requiring custom logic (i.e. finding the soonest timer to fire, sleeping until it fires, reschedule it, find the next soonest timer, and so on).
As I spend more time considering distributed systems with heartbeats, I'm sure I'll come to appreciate more nuanced opinions on these very simple approaches discussed here, but for the time being they seem like useful tools in the design of distributed systems.