Digg v4's Architecture and Development Processes
A month ago history reset with the second launch of Digg v1, and memories are starting to fade since much of the Digg team joined SocialCode four months ago, so it seemed like a good time to describe the system and team architecture which ran and developed Digg.com from May 2010 until May 2012.
There won’t be controversy here, not even much of a narrative, just a description of how we were working and the architecture we built out.
Team Structure, Size and Organization
We have to start with a bit of context surrounding the company’s size, how the teams were organized, and how the structure was impacted by a series of layoffs and subsequent hiring.
For focus I’m not covering the Sales, Finance, Ad Management, Design, HR, BD teams and such; they were important pieces of the company and how it functioned, just not central to this particular story.
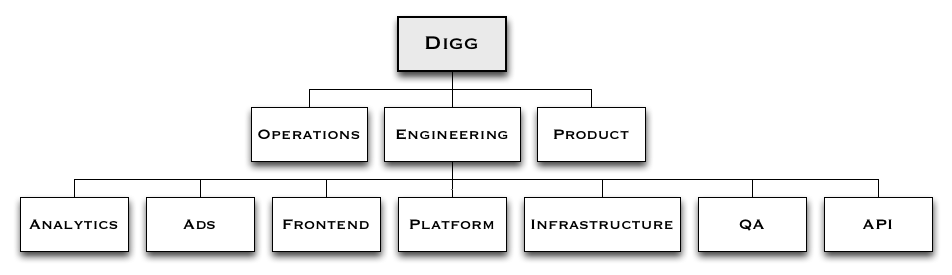
Our story starts with a fairly traditional company layout, with distinct Product, Engineering and Operations leadership. The Product team was rather small with four members, the Operations team was about eight engineers, QA about six engineers, and the Development team was around twenty developers.
The development team itself was structured around four horizontal teams (frontend, API, platform and infrastructure), and two vertical team (ads, analytics). The Product team operated with vertical ownership over pieces of functionality, coordinating between the various horizontal development teams.
Over the course of several layoffs and subsequent departures, the organization structure eventually reflected a return to simpler times.
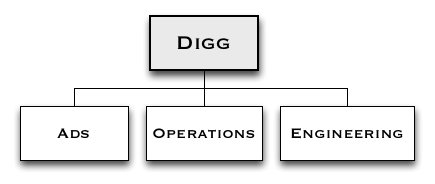
For the last year, our Operations team was three people, the Engineering team was seven people, and the Ads Engineering team was four.
Code Review and Continuous Deployment
A small set of core development practices allowed us to scale up to forty engineers, and then from forty engineers to fourteen. Let’s look at our development practices, starting with how we deployed merged, reviewed and deployed code.
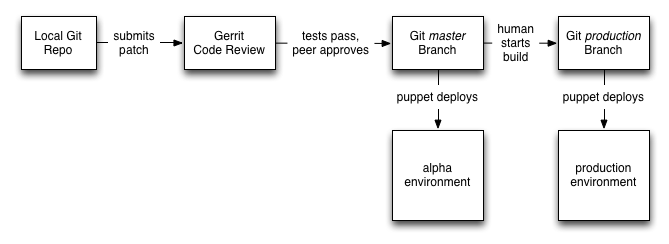
To expand upon the diagram a bit:
We used Git for source control, and Gerrit for code review. Every piece of code had be reviewed and approved by a peer, as well as pass all unittests.
Each time a patchset was submitted to Gerrit for code review, Jenkins would automatically runs its unittests, and when the tests finished would update Gerrit with the success or failure of the tests.
This meant that code reviewers didn’t have to waste their time reviewing failing patches. It also meant that we never merged unittest broken code into our Git repositories.
Once a Gerrit patchset passed its tests and was approved by a code reviewer, then it would be merged into the Git
masterbranch, and would be automatically deployed via Puppet to our alpha environment. The final step of deployment to the alpha environment (and after successfully running integration tests against the alpha environment), the new patchset would also be merged into theproductionbranch in Git.We deployed to our production environment by manually building a Jenkins job, which would then work with Puppet to deploy the updated code.
We started out with continuous deployment to production, but after a few disasterous late night deployments we decided that having a human in the loop before going to production was going to work better for us.
If we had stuck with continuous deployment, we would have eventually improved our tests to the extent that very few bad changes got through, but that didn’t seem like the right investment of time for us at that point.
This system for reviewing, testing and deploying code was–to my mind anyway–the most important and successful piece of developing code at Digg. It was structured enough to code standards high and consistent with our forty person team, and later on it was lightweight enough to not bog down the much smaller team.
Emergent Processes and Practices
There were a smattering of other practices which we employed, but most of these evolved from practice rather than being deliberate decisions.
We started out with extremely high unittest coverage, but as the team shrank, we ended up writing very few new tests. This wasn’t an explicit policy, but stemmed from the belief that unittests didn’t help prevent the types of breakages we experienced most: systemic failures involving multiple components under production load, and frontend rendering issues.
Unlike our unittests which continued providing value years later, our Selenium tests rotted almost immediately once we stopped actively maintaining them, and the Selenium tests departed soon after the QA team.
We used Thrift for defining interfaces between our frontend and platform teams, which generally made communication and coordination between the teams straightforward. We did end up with some poorly designed interfaces, which created much confusion, but in general using Thrift for defining the types and interfaces between teams was a great communication aid.
We rarely changed behavior of existing Thrift interfaces, rather we would push out a new interface with the desired functionality, update the clients to use that functionality, and then remove the old interface. This was a somewhat awkward process, but since we deployed frontend and backend code independently (and doing a full rollout of all frontend or backend servers took a few minutes), it was a safe, sane way to ensure we didn’t break ourselves.
We launched all frontend changes with a mechanism to roll them out to a subset of users, or to disable them if they ran into problems. This allowed us to separate deployment from rollout, which made deploying code more peaceful, and gave us the ability to time rolling out features precisely.
We had initially intended to use this mechanism for A/B testing new features, but it ended up being most valuable for managing releases and getting feedback from small trusted groups of users.
We also dark launched backend features which we expected to have a performance or load impact, to avoid bringing down the world while we stared helplessly at a Jenkins progress bar.
Moving past how we were developing, let’s take a look at the system we developed.
Thus Spoke Conway, or “The Architecture”
If you look at the organizational structure we had when we designed the v4 architecture, and then you look at the architecture we developed, it’s basically an allegory of Conway’s Law.
We had an API team and an API server, a frontend team and a frontend server, a platform team and a backend server, an Ads team and an Ads server, a plethora of datastores managed by the Infrastructure team, and a Hadoop cluster for the Analytics team.
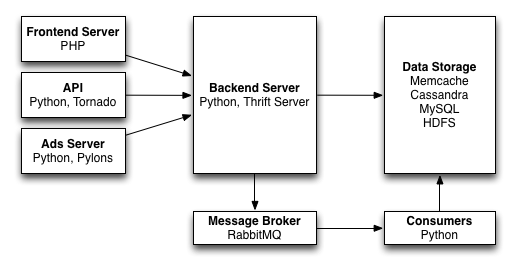
That said, it was a very standard architect for a team of our size, with the frontend team developing in stateless PHP/HTML/JS, with state and storage managed by the backend server, and with a message queue for handling long-running and non-transactional processing.
The most unusual aspect was probably the backend servers which were gevent based Thrift servers. For better or worse–by which I mean entirely for the worse–there isn’t a standard high-performance Python thrift server, so we ended up spending a good amount of time with gevent and making gevent-safe client pools. I’d probably avoid using Thrift for a Python server again, simply to avoid having to maintain a similar server.
Having both PHP and Python servers always bothered me a bit in the “I would never plan it this way” sense, but in practice wasn’t much of an issue: the last year or so, pretty much our entire team was comfortable working in both languages, and didn’t have too many complaints.
In the same vein of the perfectionist system designer, having Tornado, Apache+mod_wsgi+Pylons, and the Python gevent servers bothered me a bit, but in practice wasn’t that much of an issue (if we hadn’t had the Jenkins and Puppet deployment systems, I believe the technology proliferation would have been far more painful).
Closing Thoughts
Altogether, I think that our process and architecture were pretty reasonable, and worked out well for us. If we started over today we would definitely approach thing differently, or if the team hadn’t shrunk so significantly, or if we hadn’t been simultaneously managing the technical debt of legacy systems, APIs and contracts, and so on; those are all interesting topics to broach sometime.
There is also an article worth writing about the database and technology proliferation at Digg (Cassandra, MySQL, Redis, Memcache, HDFS, Hive, Hadoop, Tornado, Thrift servers, PHP, Python, Pylons, Gevent and such), which I’d like to piece together.
Or thinking through how our organization structure impacted how we worked (if this is an interesting topic for you, you must watch Adam Pisoni’s talk about the adaptable organization).
All in good time.