Acing Your Architecture Interview
My most memorable interview started with an entirely unexpected question: “How well do you remember calculus?” I smiled and said that it had been some years, and that I was rather out of practice. Nonetheless we spent the next hour trying to do calculus, which I bombed spectacularly.
Many people have similar misgivings about “architecture interviews”, which are one of my favorite interviews for experienced candidates from within the internet industry, and I decided to write up my algorithm for approaching these questions.
Before jumping in, a few examples of typical architecture interview questions:
- Design the architecture for Facebook, Twitter, Uber or Foursquare.
- Diagram a basic web application of your choice.
- Design a reliable website similar to a newspaper’s website.
- Design a scalable API to power a mobile game.
From that starting point, the interviewer will either give you more constraints to solve for (“your database starts to get overloaded”), or ask you to think of ways that your system will run into scaling problems and how to address them (“well, first off, I think we’d run out of workers to process incoming requests”).
The basic algorithm to this class of interviews is:
- Diagram your current design.
- Apply a new constraint to your design.
- Determine the bottleneck created by that constraint.
- Update your design to address the bottleneck.
That’s probably not quite enough to help you ace your next architecture interview, so the rest of this post will go through a brief primer on drawing architectural diagrams, and then dive into the bottlenecks created by specific constraints.
Diagramming
The most important thing to know about technical diagramming is that it’s much more of an art than a science. As long as you consistently do something reasonable, you’ll be fine.
During an interview, you’ll almost always be writing on a whiteboard, but if you do ever find yourself diagramming on a computer, I’m a huge fan of Omnigraffle. Even thought it is not cheap I think it’s a worthwhile investment (I use it for wireframing in addition to diagramming).
Let’s do a few examples.
On the left a server running a webserver and a database, and on the right two servers: one running a webserver and the other a database.
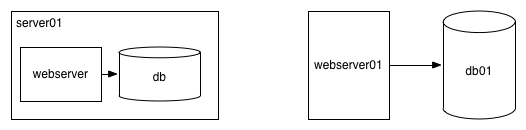
There are very few conventions, but generally servers are boxes, processes are boxes, and databases
or other storage mechanisms are cylinders. It’s totally fine to just use boxes for everything though.
Servers are generally named with server kind combined with a unique number, for example frontend01
and frontend02 for the first and second servers of the kind frontend. Numbering is helpful as you add
more servers to your example. Representing 1 as 01 is extremely arbitrary, but is a bit of a “smell” implying
that you’ve named servers before for server groups with more than nine servers (you can absolutely compose a number
of very reasonable arguements that naming servers this way is a bad idea, it’s more of a common practice than a
best practice).
Next, let’s show two datacenters, taking traffic from the mythical cloud that represents the internet.
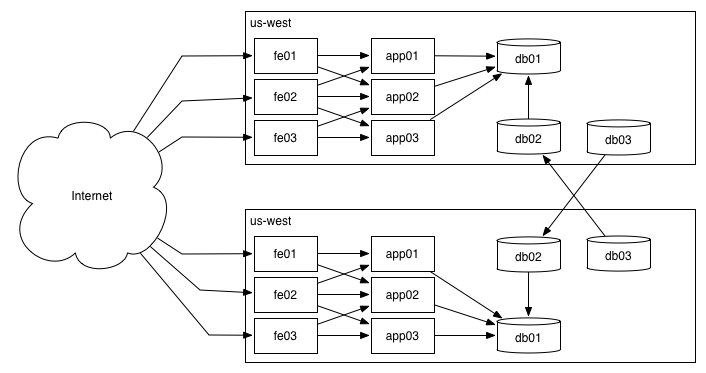
The internet is, by odd convention, always represented as a cloud. If you had a mobile device connecting to your app, generally you would show the mobile device, draw a line to the internet, and then continue as above (the same is equally true for a website).
Datacenters or regions are physically colocatedgroups of servers, and are generally depicted as a large box around a number of servers (exactly like processes within a server as depicted as boxes within the server, and generally it’s not unreasonable to think that a datacenter is to a server as a server is to a process).
As seen between the fe and app tiers of servers, I often leave off lines when it makes the diagram too messy.
Personally, I think diagrams should prefer to be effective instead of accurate, if the two concepts come into tension.
To summarize: lots of boxes, a few lines, and as simple as possible. Now, onward to problem solving!
Diagram, Constrain, Solve, Repeat
Now we’re getting into the thick of things. For each subsection, we’ll show a starting diagram, add a contraint to it, diagnose what the constraint implies, and then create an updated diagram solving for the constraint. There are many, many possible constraints, so we won’t be able to cover all of them, but hopefully we’ll be able to look at enough of them to give an idea.
Web Server Is Overloaded
You’re running your blog on a single server, which is a simple Python web application running on MySQL.
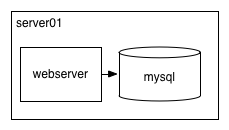
All of the sudden, your server becomes “overloaded”, what do you do?! Well, the first thing is to figure out what that even means. Here are a handful of things that might mean (in approximate order of likeliness):
- you don’t have enough workers to handle concurrent load,
- not enough memory to run its workload,
- not enough CPU to run its workload quickly,
- disk are running out of IOPs,
- not enough file descriptors,
- not enough network bandwidth.
You should ask the interviewer which of these issues is causing the overload, but if they ask you to predict which is happening, it’s probably one of the above. Let’s think about both vertical and horizontal scaling strategies for each of those (vertical scaling is increasing your throughput on a given set of hardware, perhaps by adding more memory or faster CPUs, and horizontal scaling is about adding more servers).
Many, probably most, servers use threads for concurrency. This means if you have ten threads you can process ten concurrent requests. Following, if your average request takes 250 ms, your maximum throughput on ten threads is 40 requests per second. By far the most common first scaling problem for a server is that you have too many incoming requests for your current workload.
The simplest solution is to add more worker threads, with server02 having many more threads
than server01.
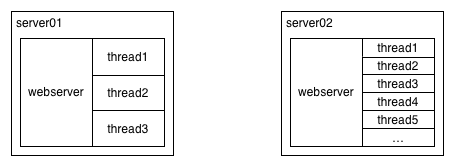
The limitation is that every additional thread consumes more memory and more CPU. At some point, varying greatly depending on your specific process, you simply won’t be able to add more threads due to memory pressure. It’s also possible that your server will have some kind of shared resources across threads, such that it gets slower for each additional thread, even if it isn’t becoming memory or cpu constrained.
If you become memory constrained before becoming CPU constrained, then another great option is to use a nonblocking webserver which relies on asynchronous IO. The nonblocking implemention decouples your server from having one thread per concurrent request, meaning you could potentially run many, many concurrent requests on a single server (perhaps, 10,000 concurrent requests!).
Once you’ve exhausted your above options to process more requests on your given server,
then the next steps are likely to break apart your single server into several specialized
servers (likely a server role of servers and a database or db role of servers), and put
the web servers behind a load balancer.
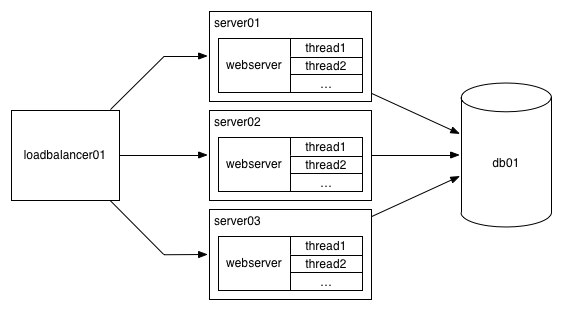
The load balancer will balance the incoming requests across your webservers, each of which will
have its own threads that can process concurrent requests. (Load balancers rely on non-blocking IO,
and are heavily optimized, so their concurrency limits are usually not a limiting factor.)
You’re not setup so you can more-or-less indefinitely add more and more server nodes to increase your concurrency.
(Typically you’ll break your database at this point, which is continued below.)
Scaling horizontally via load balancer is the horizontal solution to all host-level problems, if you are running a stateless service. (A service is stateless if any instance of your service can handle any request; if you need the same server to continue handling all requests for a given page or user, it is not stateless).
If you remember one thing, it’s using a load balancer to scale horizontally and skip forward to the databases section, but we’ll also dig a bit into vertically scaling the other common scaling challenges for a single server.
The next, most common scenario is running out of memory (perhaps due to too many threads). In terms of vertically scaling, you could add more RAM to your server or spend some time investing into reducing the memory usage.
If your data is too large to fit into a given server and all the data needs to fit into memory at once, then you can shard the data such that each server has a subset of data, and update your load balancer to direct traffic for a given shard to the correct servers.
We’ll look at this category of solution a bit more in the section on databases below, but the other option is to load less of your data into memory and instead to store most of it on disk. This means that reading or writing the data will be slower, but that you’ll have significantly more storage capacity (1TB SSDs are common, but it’s still uncommon for a web server to have over 128GB of RAM).
For read heavy workloads, a compromise between having everything on disk and everything in memory is to load the “hot set” (the portion which is frequently accessed) of data into memory and keep everything else on disk (a newspaper might keep today’s articles in memory but keep their historical archive on disk for the occasional reader interested in older news).
Running out of CPU is very similar to running out of RAM, with a couple of interesting aspects.
A server with major CPU contention keeps working in a degraded way whereas a server with insufficient memory tends to fail very explicitly (software tends to crash when it asks for more memory and doesn’t get it, and Linux has the not-entirely-friendly OOM killer which will automatically kill processes using too much memory).
In many cases where you’re doing legitimate work that is using too much CPU, you’ll be able to rely on a library in a more CPU efficient language (like Python or Ruby using a C extension, simplejson is a great example of this that you might already be using). It’s not uncommon for production deployments to spend 20-40% of their CPU time serializing and deserializing JSON, and simply switching the used JSON library can give a huge boost!
In cases where you’re already using performant libraries, you can rewrite portions of your code in more performant languages like Go, C++ or Java, but the decision to rewrite working software is fraught with disaster.
In a workload where you’re writing a bunch of data (or even just an obscene amount of logs) or reading a bunch of data from disk (perhaps because you have too much to fit into memory), then you’ll often run out of IOPS. IOPS are the number of reads or writes your disk can do per second.
You can rewrite your software to read or write to disk less frequently through caching in memory or by buffering writes in memory and then periodically flushing them to disk.
Alternatively, you can buy more or different disks. Disks are interesting because the kind of disk you use matters in a very significant way: spinning disks (SATA is a kind of larger, slower disks, and SAS are a kind of faster, smaller disks) max out below 200 IOPS, but low end SSDs can do 5,000 IOPS and the best can do over 100,000 IOPS. (There are even higher end devices like FusionIO which can perform far more at great cost.)
It’s pretty common to end up with your web servers running cheap SATA drives and to have your database machines running more expensive SSDs.
For workloads with high concurrency, for example your non-blocking service you used to solve being limited by the number of threads on your server, an exciting problem you will eventually run into is running out of file descriptors.
Almost everyone has a great file descriptor related disaster story, but the good news is that it’s just a value you need to change in your operating systems configuration, and then you can go back to your day a bit wiser. (There is a storied history of operating systems setting bewilderingly low default values for file descriptors, but on the average they are setting increasingly reasonable defaults these days, so you may never run into this.)
Finally, if your application is very bandwidth intensive–perhaps your hypothetical application does streaming video–then at some point you’ll start running out of bandwidth on your network interface controller or NIC. Most servers have 1GBs NICs these days, but it’s pretty cost effective to upgrade to 10GBs NICs if you need them, which most workloads don’t.
Alright, that concludes our options for scaling out our single web server! In addition to the numerous strategies for vertically scaling that server out to give us a bit more work, load balancers are really by far our best tool.
Next let’s take a look at the scenario where your servers aren’t overloaded at all, but are responding very slowly.
Application is Slow
For this section, let’s say you’re running an API which takes a URL and returns a well formatted, easy to read version of the page (something like this). Your initial setup is simple, with a load balancer, some web servers and a database.
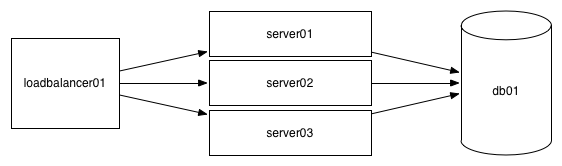
All of the sudden, your users start to complain that your application has gotten slow. The humans can perceive latency over 100 to 200ms, so ideally you’d want your pages to load in less than 200ms, and for some reason your application is now taking 1.5 seconds to load.
How can you fix this?
Your first step for every performance problem is profiling. In many cases, profiling won’t make it immediately obvious what you need to fix, but it will almost always give you a bread crumb. You follow that bread crumb until you profile another component which gives you another bread crumb, and you keep chasing.
In this case, it’s pretty likely that the first issue is that reading from your database has gotten slow. In a case where users frequently call your API on the same URLs, then a great next step would be adding a cache like Redis or Memcached.

Now for all API calls you’ll check:
- to see if the data is in your cache and use the data there if it exists,
- if the data is in your database, if it is, you’ll write that data to cache and then return it to the user,
- otherwise you’ll crawl the website, then write it to the database, then to the cache, then return it to the user.
As long as users keep crawling mostly the same URLs, your API should be fast again.
Another common scenario is for your application is getting slow because it’s simply doing too much! Perhaps every incoming request is retrieving some data from your cache, but it’s also writing a bunch of analytics into your database, and writing some logs to disk. You profile your server, and find that it’s spending the majority of its time writing the analytics data.
A great way to solve this is to run the slow code somewhere where it won’t impact the user. In some languages this is as simple as returning the response to the user and doing the analytics writes afterward, but many frameworks make that surprisingly tricky.
In those cases, a message queue and asynchronous workers are your friend. (Some example message queues are RabbitMQ and Amazon Simple Queuing Service.)
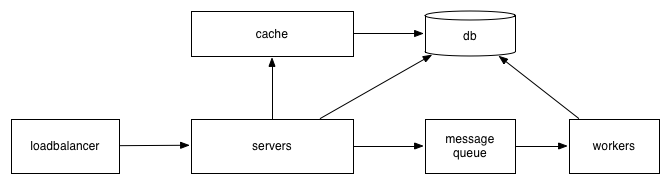
(Note that I’ve gone ahead and replaced the named servers with boxes which represent many servers, many cache boxes, and so on. I did this to reduce the overall complexity of the diagram, trying to keep it simple. Diagram refactoring is often useful! A hybrid approach is to have a box of servers and then to show multiple servers within that box, but only draw lines from the containing box, allowing you to more explicitly indicate many servers in a given role without having to draw quite so many overlapping lines.)
Now when a request comes to your servers, you do most of the work synchronously, but then schedule a task in your message queue (which tends to be very, very quick, depending on what backend you’re using it’ll vary, but very likely <50ms), which will allow your worker processes to dequeue the task and process it later, without your user having to wait for it to finish (in other words, asynchronously).
Finally, sometimes latency is not about your application at all, but instead is because your user is far away from your server. Crossing from the United States’ east coast to the west will take about 70ms, and a bit more to go from the east coast to Europe, so traveling from the west coast to Europe can easily be over 160ms.
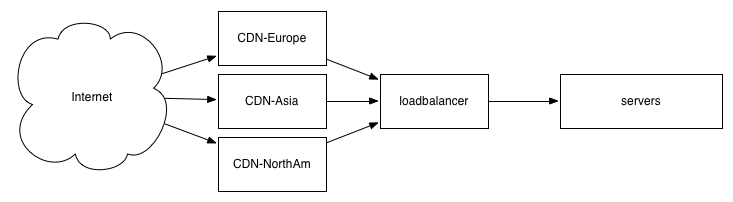
Typically the most practical way to address this is to use a CDN, which behaves like a geographically distributed cache, allowing common requests to get served from local caches which are optimistically only 10 or 20ms away from the user instead of traveling across the globe. (AWS Cloud Front, Fastly, EdgeCast and Akamai are some popular examples of CDNs.)
Larger companies or those with very special needs–typically with high bandwidth needs like video streaming–sometimes create points of presence or POPs which act like CDNs but are much more customizable, but it’s increasingly uncommon as more and more companies start and stay in Amazon, Google or Microsoft clouds.
To repeat slightly, CDNs are typically only useful for situations where your content is either static or can be periodically regenerated, which is the case for a newspaper website for logged out users, and where some subset of your content is popular enough that multiple people want to see the same content in a given minute or so (acknowledging that a minute is an arbitrary length of time, you can cache content however long you want). (This admittedly ignores the latency advantages of SSL termination, which this article covers nicely.)
If you need to reduce latency to your users and your workload doesn’t make using a CDN effective, then you’ll have to run multiple datacenters, each of which has either all of your data or has all the necessary data for users who are routed to it.
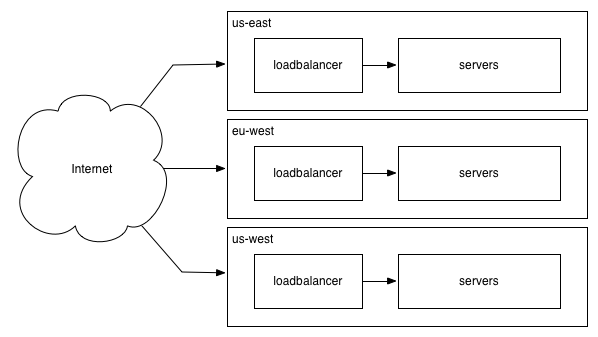
(If you happen to be wondering or may be asked what mechanism picks the right datacenter for you, generally that is Anycast DNS, which is very nifty and definitely worth some bonus points if you can relevantly mention it in an interview.)
Running multiple datacenters tends to be fairly complex depending on how you do it, and as a topic is beyond the scope of something which can be covered in this article. A relatively small percentage of companies run multiple datacenters (or run in multiple regions for the cloud equivalent), and almost all of them do something fairly custom.
That said, designing a system which supports multiple datacenters ends up being very similar to scaling out your database, which happens to be the next section.
Database Is Overloaded
Let’s say that you’re implementing a simple version of Reddit, with user submissions and comments.
All is good for a while, but you start getting too many reads and your database becomes CPU bound. If you’re using a SQL database like MySQL or PostgreSQL, the simplest fix is to add replicas which have all the same data as the primary but which only support reads (nomenclature here varies a bit, with primary and secondary or primary and replica becoming more common, older documentation and systems tend to refer to these as master and slave, but that usage–despite being the default and dominant for many years and not uncommon to hear today–is steadily going out of favor).
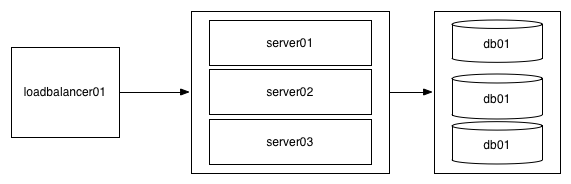
Your write load must still be applied across every server (primary or replica), so replicas do not give you any additional write bandwidth, but every read can be done against any server (within the constraints of replication lag, which only matters if you are trying to read data immediately after you write it, in which case you may have to force “read after write” operations to read from the primary database, but you can still allow all other reads to go to any of the replicas), so you can horizontally scale out reads for a long time (at some point you’ll eventually become constrainted on adding more replics on the available bandwidth, but many databases allow you to chain replication from one replica to another replica, which will–in theory anyway–allow you to scale out more or less indefinitely).
If you’re overloaded with writes, your solution will end up being a bit different. Rather than replication, instead you’ll need to rely sharding: splitting your data so that each database server only contains a subset, and then having a mechanism (often just some code in your application) which correctly picks the right shard for a give operation.
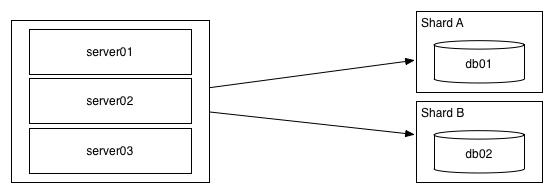
Because this allows each server to only do a subset of the writes, you can scale out horizontally to handle more or less any write load. In practice people dislike sharding because you can no longer perform operations against all of your data (for example, to count all of the submitted posts), instead you’ll have to perform the operation against each shard independently and figure out how to combine the results yourself.
If your servers are running out of IOPS or disk space, sharding is also the best solution. In a certain sense, sharding is load balancing for stateful services.
Sharding is also complex to maintain operationally, you’ll spend a lot of time maintaining the mechanisms which route to the correct shard, and even more time figuring out how to rebalance your shards to prevent one shard from becoming so large that it can’t handle all of the writes routed to it.

If you have heavy reads and heavy writes, then you absolutey can combine replication and sharding as shown above.
Although replication and sharding are two of the most common scaling solutions for an architecture interview, there are a few others worth mentioning:
Batching is useful when you have too many writes for your database, but for whatever reason you don’t want to start sharding your database yet. Especially for usecases like analytics which are tracking the number of pageviews for a given page over a minute, batching could allow you to go from 10,000s of writes per second to one write a minute (although you’ll have to store the batched data somewhere, perhaps in a message queue or even justin your application’s memory).
Finally, the last strategy I’ll mention here is to use a different kind of database, in particular NoSQL databases like Cassandra are designed to spread writes and reads across many servers by default, as opposed to having to implementing your own custom sharding tools. The typical downside to NoSQL servers is that they have a reduced set of operations you can perform efficiently because each shard only has a subset of data.
If you want to get deeper on NoSQL, my advice would be to read the fairly approachable Dynamo Paper which will give you the concepts and vocabulary to have a thoughtful conversation about the scenarios where a NoSQL database might be appropriate.
Ending Thoughts
This ended up being a bit longer than expected, and in particular what really came to me while writing it is what an odd kind of interview this is. Essentially it is a test to see if people can create the impression that they’ve built large or complex systems before.
Oddness aside, this interview format does a great job of recreating the real experience of codesigning a system together or explaining how an existing system works to a new teammate. As long as we use it with candidates with an appropriate background–namely, some years of experience at an internet company or a company using the same technologies as an internet company–then I think it’s a useful tool in your kit.
If not this format, how do you get a sense of someone’s system design experience?